需要用到的第三方库:
requests(Python HTTP请求工具)
lxml(解析网页结构工具)
beautifulsoup4(网页文档解析工具)
先贴上代码
import requests from bs4 import BeautifulSoup import csv #1.新建一个csv的文件 to_be_show=open ('D:\豆瓣最近上映电影.csv','w',encoding='gbk',newline='') writer=csv.writer(to_be_show) #CVS写入的参数为一个list writer.writerow(['电影名','链接','海报','上映日期','类型','地区','想看人数']) #2.发送请求,获取即将上映电影 response=requests.get('https://movie.douban.com/cinema/later/hangzhou/') html_content=response.content.decode('utf-8') response.close() #3.解析html格式的响应内容 soup=BeautifulSoup(html_content,'lxml') all_movies=soup.find('div',id='showing-soon') #新建一个列表接收所有电影信息 all_movies_list=[] for each_movie in all_movies.find_all('div',class_='item'): tag_a=each_movie.find_all('a') tag_li=each_movie.find_all('li') movie_name=tag_a[1].text movie_link=tag_a[1]['href'] movie_poster=tag_a[0].find('img')['src'] movie_date=tag_li[0].text movie_type=tag_li[1].text movie_area=tag_li[2].text movie_want_see=tag_li[3].text.replace('人想看','') #打印一下 print('名字:{name},链接:{link},海报:{poster},上映日期:{date},类型:{type},地区:{area},想看人数:{want_see}'. format(name=movie_name,link=movie_link,poster=movie_poster,date=movie_date,type=movie_type,area=movie_area,want_see=movie_want_see)) all_movies_list.append({'名字':movie_name,'链接':movie_link,'海报':movie_poster,'上映日期':movie_date,'类型':movie_type,'地区':movie_area,'想看人数':movie_want_see}) #4.用sorted将所有电影按想看的人数反序排列,x为all_movies_list中的每一个元素 all_movies_list=sorted(all_movies_list,key=lambda x:int(x['想看人数']),reverse=True) #将电影信息写入cvs文件 for movie_list in all_movies_list: writer.writerow([movie_list['名字'],movie_list['链接'],movie_list['海报'],movie_list['上映日期'],movie_list['类型'],movie_list['地区'],movie_list['想看人数']]) #关闭文件 to_be_show.close()
CSV文件
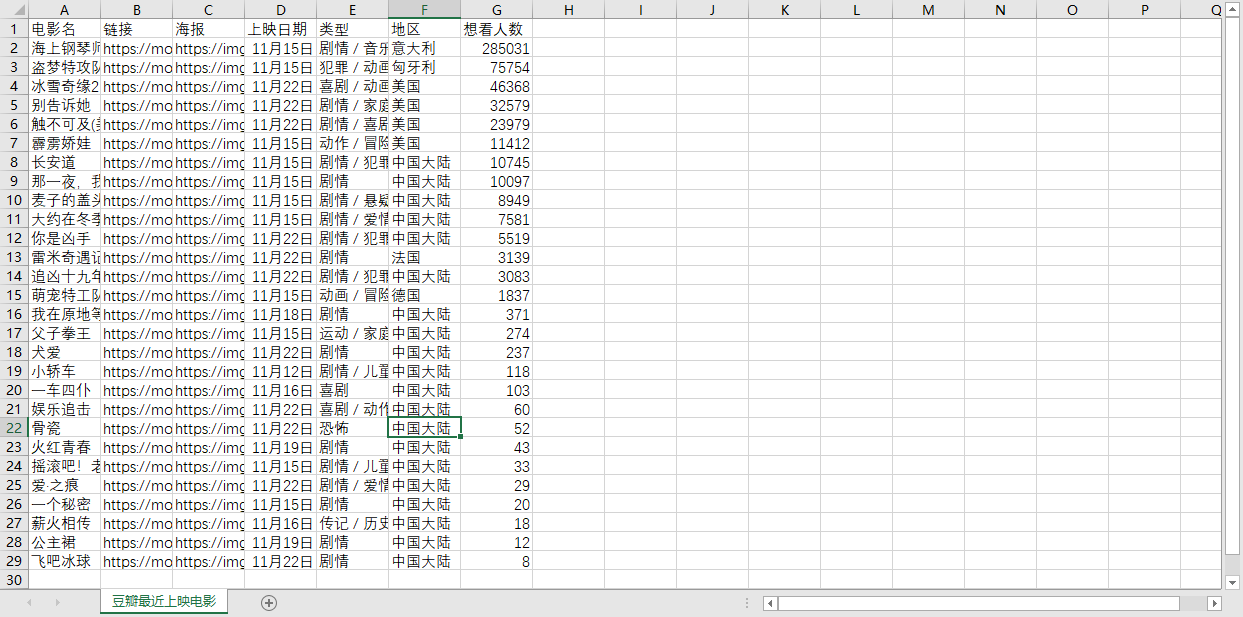
1.requests库介绍
Python用来发送http请求的第三方库
(1)自动管理cookie:requests.session(),之后使用session请求,就会自动带上所有的cookie
import requests session = requests.session() response = session.get("https://www.baidu.com") print(response.content.decode('utf-8'))
#添加请求参数,请求头,cookie
import requests import json session=requests.session() #添加cookie cookie={ '_dacevid3':'81f74afa.f084.cb8d.b2d4.2993cf95c925', '__dacevst':'81c58de1.147d96cb|1573559053809' } requests.utils.add_dict_to_cookiejar(session.cookies,cookie) #设置请求头 header={ 'accept': 'image/webp,image/apng,image/*,*/*;q=0.8', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', } #设置请求参数 param='{"name":"admin","password":"123456"}' #使用URL,请求头,请求参数发送请求 url='http://www.baidu.com' res=session.post(url,data=json.dumps(param),headers=header) try: print(res.content) except RuntimeError as error: print(error) finally: res.close()
2.lxml库介绍
3.beautifulsoup4库介绍
beautifulsoup4是一个可以从HTML或XML文件中提取数据的Python库,他可以选择几个不同的解析器:
html.parser(Python原生自带,速度慢,容错能力差)
html5lib(Python自带,速度慢)
lxml(需要安装,Python最快,还可以解析xml文件)
beautifulsoup4介绍链接:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
(1)初始化BeautifuSoup的参数
soup=BeautifulSoup(html_content,'lxml')
第一个参数 html_content是网页的源代码,可以是个Unicode字符串,也可以是一个二进制字符串(如果第一个参数是字符串并且网页自带了charset信息,BS会默认采用网页的默认编码解码,否则默认以你当前文件
执行的编码(通常是utf-8)进行解析。如果是二进制字符串,如果自己手动指定了编码,就以指定编码解析,否则默认utf-8解析)。
html.parser进行解析(2)BeautifulSoup的基本使用语法规则
——find() 使用示例
soup.find('a'),会返回在soup包含的源代码中,遇到的第一个<a>...</a>标签内容对象。
soup.find('a', id='next'),会返回在soup包含的源代码中,遇到的第一个有属性为id,值为next的<a>对象,比如<a id="next">...</a>。(不只可以用id,大部分其他的属性都可以直接使用,比如src、name。 值得注意的是,class这个属性因为是Python关键字,不能直接使用,所以在BS里面,使用class_='...'进行代替 )
find返回的结果,依然可以继续使用find()或者find_all()方法。如果找不到指定的内容,find会返回None
——find_all()使用示例
soup.find_all('a'),会返回在soup包含的源代码中,遇到的所有<a>...</a>标签内容的可迭代对象(返回一个 list)。
soup.find_all('a', class_='next'),会返回在soup包含的源代码中,遇到的所有属性为class,值为next的<a>的 可迭代对象,比如<a class="next">...</a>。(语法和find也一样,class也不能直接写)
find_all返回的“list”中的单个对象 依然可以继续使用find()或者find_all()方法。如果找不到指定的内容,find_all会返回一个空的“list”。
——获取元素的某个属性
soup['src'],取出soup对象的src属性。如果该属性不存在,那么程序会报错。
——获取元素中的所有文本
soup.text,假设soup对象为<div>你好<a>复联</a></div>,那么这个操作返回字符串是"你好复联"。
注意:BeautifulSoup的find('a')是查找第一个<a></a>标签,find_all('a')是查找所有<a></a>标签,和selenium使用xpath查找标签不同,xpath是按html层级查找标签,刚开始接触BeautifulSoup被搞混淆了