GIL介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全
如果多个线程的target=work,那么执行流程是:
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
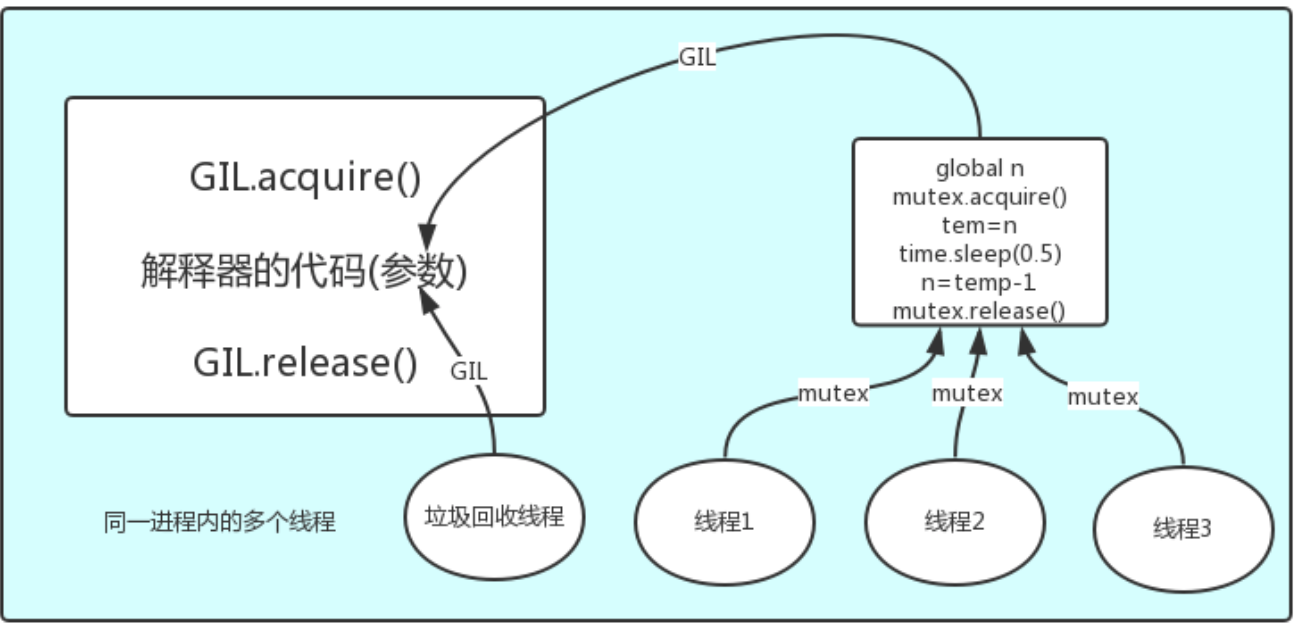
GIL与Lock
GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock,如下图

分析:
1、100个线程去抢GIL锁,即抢执行权限
2、肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
3、极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
4、直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程示例代码:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from threading import Thread,Lock
import os,time
n = 100
def work():
global n
Lock.acquire()
temp = n
time.sleep(1)
n = temp -1
Lock.release()
if __name__ == '__main__':
Lock = Lock()
l = []
for i in range(100):
t = Thread(target=work)
l.append(t)
t.start()
for i in l:
i.join()
print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全,不加锁则结果可能为99GIL与多线程
有了GIL的存在,同一时刻同一进程中只有一个线程被执行
1、对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用
2、当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O,所以我们只能相对的去看一个程序到底是计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用武之地
假设我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程单核情况下,分析结果:
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜
如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜
多核情况下,分析结果:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜
如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜多线程性能测试
如果并发的多个任务是计算密集型:多进程效率高
# 计算密集型:用多进程
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i
if __name__ == '__main__':
l=[]
# print(os.cpu_count()) #本机为8核
start=time.time()
for i in range(8):
p=Process(target=work) #耗时23.493834257125854
# p=Thread(target=work) #耗时46.50895023345947
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))如果并发的多个任务是I/O密集型:多线程效率高
# IO密集型:用多线程
from multiprocessing import Process
from threading import Thread
import os,time
def work():
time.sleep(2)
print('=====>')
if __name__ == '__main__':
l = []
print(os.cpu_count())
start = time.time()
for i in range(400):
# p = Process(target=work)# 26.513117790222168
p = Thread(target=work)# 2.0516674518585205
l.append(p)
p.start()
for i in l:
i.join()
stop = time.time()
print('run is time %s'%(stop-start))应用:
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析