并发量太高的应用中(比如10分钟内插入300w条记录),数据库往往难堪重负,在没有银子实现服务器集群/负载均衡/分布式存储的情况下,可以尝试一下把数据库做一个临时副本全部放在内存中处理,完成操作后,再同步到硬盘的物理数据库中。
那么,把数据库放在内存中到底有多快? 晚上抽空试了一下:
步骤1:先用Ramdisk之类的工具,划出一块内存当作虚拟硬盘.
步骤2:先在sql2005中新建一个空库db,然后分离,把分离后的数据库文件复制到虚拟硬盘中,并附加回数据库,至此完成数据库在内存中的建立。
步骤3:建一个测试表Test

 Code
Code
USE [db]
GO
/****** 对象: Table [dbo].[Test] 脚本日期: 06/15/2009 21:55:24 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Test](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](50) COLLATE Chinese_PRC_CI_AS NOT NULL,
CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
步骤4:直接在查询界面中写一个循环,插入300w条数据,见下图:

在我的笔记本上,共耗时6分50秒,数据库文件增加到近280M
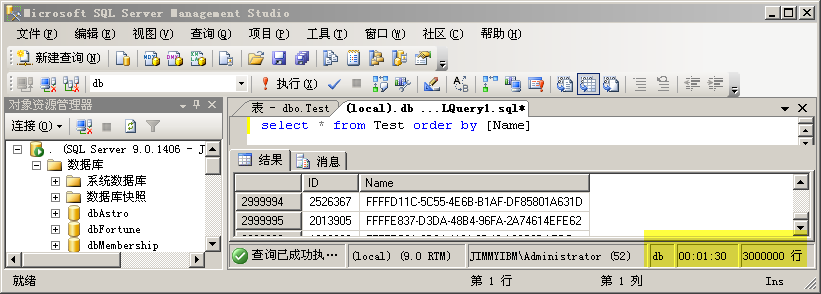
步骤5:测试一次性查询300w条数据

耗时2分钟2秒
步骤6:清空表后,对Name字段做索引,重复插入300w数据

步骤6:重复刚才的查询