
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
(1)环境配置:
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url ='http://heyuan.8684.cn/' ##开始的URL地址
start_html = requests.get(all_url, headers=headers)
#print(start_html.text)
Soup = BeautifulSoup(start_html.text, 'html.parser')
(2)爬取站点分析:
a、河源市公交线路分类方式有3种:

b、我主要通过数字开头来进行爬取,打开网站,点击“1”,右击鼠标选择“检查”,可以发现保存在链接保存在<div class="bus_kt_r1">里面,故只需要提取div里的href即可:
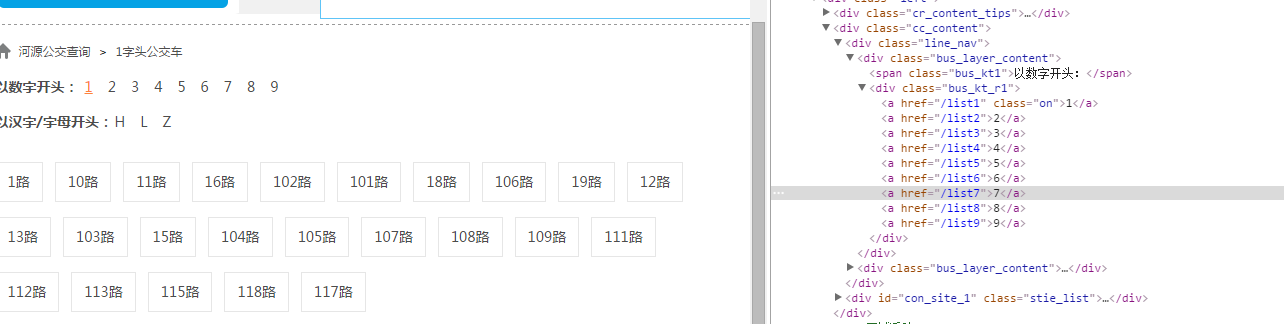
代码:
all_1 = Soup.find('div', class_='bus_kt_r1').find_all('a')#获取以数字开头所有路线
c、接着往下,发现每一路的链接都在<div id="con_site_1" class="site_list"> 的<a>里面,取出里面的herf即为线路网址,其内容即为线路名称。
代码:
href = a['href'] # 取出a标签的href 属性
html = all_url + href
second_html = requests.get(html, headers=headers)
#print(second_html.text)
Soup2 = BeautifulSoup(second_html.text, 'html.parser')
all_a2 = Soup2.find('div', class_='stie_list').find_all('a')
d、打开线路链接,就可以看到具体的站点信息了,打开页面分析文档结构后发现:线路的基本信息存放在<div class="bus_i_content">里面,而公交站点信息则存放在<div class="bus_line_top">及<div class="bus_line_site">里面。
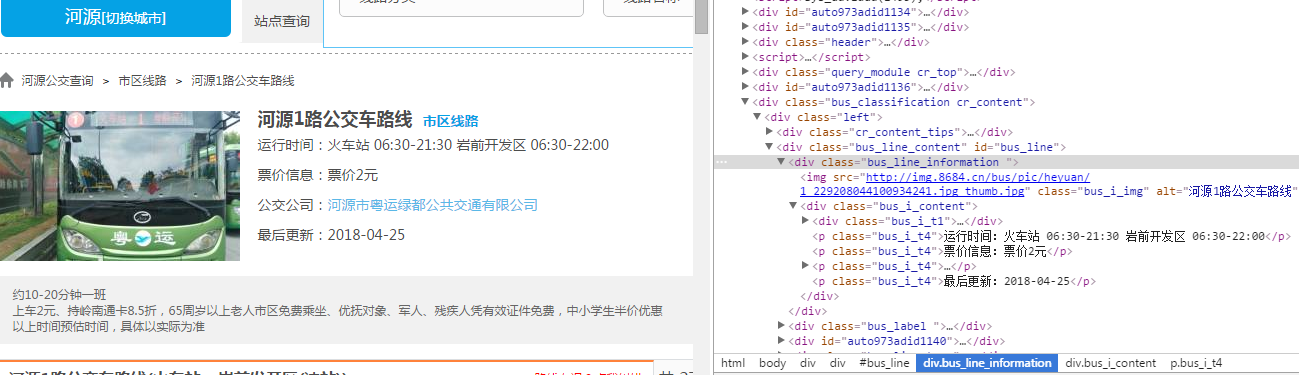
提取代码:
title1 = a2.get_text() # 取出a1标签的文本
href1 = a2['href'] # 取出a标签的href 属性
# print(title1, href1)
html_bus = all_url + href1 # 构建线路站点url
thrid_html = requests.get(html_bus, headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'html.parser') # 以html.parser方式解析html
bus_name = Soup3.find('div', class_='bus_i_t1').find('h1').get_text() # 提取线路名
bus_type = Soup3.find('div', class_='bus_i_t1').find('a').get_text() # 提取线路属性
bus_time = Soup3.find_all('p', class_='bus_i_t4')[0].get_text() # 运行时间
bus_cost = Soup3.find_all('p', class_='bus_i_t4')[1].get_text() # 票价
bus_company = Soup3.find_all('p', class_='bus_i_t4')[2].find('a').get_text() # 公交公司
bus_update = Soup3.find_all('p', class_='bus_i_t4')[3].get_text() # 更新时间
bus_label = Soup3.find('div', class_='bus_label')
if bus_label:
bus_length = bus_label.get_text() # 线路里程
else:
bus_length = []
print(bus_name, bus_type, bus_time, bus_cost, bus_company, bus_update)
all_line = Soup3.find_all('div', class_='bus_line_top') # 线路简介
all_site = Soup3.find_all('div', class_='bus_line_site') # 公交站点
line_x = all_line[0].find('div', class_='bus_line_txt').get_text()[:-9] + all_line[0].find_all('span')[
-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = [] # 上行线路站点
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num == 2: # 如果存在环线,也返回两个list,只是其中一个为空
line_y = all_line[1].find('div', class_='bus_line_txt').get_text()[:-9] + all_line[1].find_all('span')[
-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = [] # 下行线路站点
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y, sites_y_list = [], []
information = [bus_name, bus_type, bus_time, bus_cost, bus_company, bus_update, bus_length, line_x, sites_x_list,
line_y, sites_y_list]
e、自此,我们就把一条线路的相关信息及上、下行站点信息就都解析出来了。如果想要爬取全市的公交网络站点,只需要加入循环就可以了。
代码:
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url ='http://heyuan.8684.cn/' ##开始的URL地址
start_html = requests.get(all_url, headers=headers)
#print(start_html.text)
Soup = BeautifulSoup(start_html.text, 'html.parser')
all_1 = Soup.find('div', class_='bus_kt_r1').find_all('a')#获取以数字开头所有路线
Network_list = []
for a in all_1:
href = a['href'] # 取出a标签的href 属性
html = all_url + href
second_html = requests.get(html, headers=headers)
#print(second_html.text)
Soup2 = BeautifulSoup(second_html.text, 'html.parser')
all_a2 = Soup2.find('div', class_='stie_list').find_all('a')
for a2 in all_a2:
title1 = a2.get_text() # 取出a1标签的文本
href1 = a2['href'] # 取出a标签的href 属性
# print(title1, href1)
html_bus = all_url + href1 # 构建线路站点url
thrid_html = requests.get(html_bus, headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'html.parser') # 以html.parser方式解析html
bus_name = Soup3.find('div', class_='bus_i_t1').find('h1').get_text() # 提取线路名
bus_type = Soup3.find('div', class_='bus_i_t1').find('a').get_text() # 提取线路属性
bus_time = Soup3.find_all('p', class_='bus_i_t4')[0].get_text() # 运行时间
bus_cost = Soup3.find_all('p', class_='bus_i_t4')[1].get_text() # 票价
bus_company = Soup3.find_all('p', class_='bus_i_t4')[2].find('a').get_text() # 公交公司
bus_update = Soup3.find_all('p', class_='bus_i_t4')[3].get_text() # 更新时间
bus_label = Soup3.find('div', class_='bus_label')
if bus_label:
bus_length = bus_label.get_text() # 线路里程
else:
bus_length = []
print(bus_name, bus_type, bus_time, bus_cost, bus_company, bus_update)
all_line = Soup3.find_all('div', class_='bus_line_top') # 线路简介
all_site = Soup3.find_all('div', class_='bus_line_site') # 公交站点
line_x = all_line[0].find('div', class_='bus_line_txt').get_text()[:-9] + all_line[0].find_all('span')[
-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = [] # 上行线路站点
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num == 2: # 如果存在环线,也返回两个list,只是其中一个为空
line_y = all_line[1].find('div', class_='bus_line_txt').get_text()[:-9] + all_line[1].find_all('span')[
-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = [] # 下行线路站点
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y, sites_y_list = [], []
information = [bus_name, bus_type, bus_time, bus_cost, bus_company, bus_update, bus_length, line_x, sites_x_list,
line_y, sites_y_list]
Network_list.append(information)
# 定义保存函数,将运算结果保存为txt文件
def text_save(content, filename, mode='a'):
file = open(filename, mode, encoding='utf-8')
for i in range(len(content)):
file.write(str(content[i]) + '
')
file.close()
# 输出处理后的数据
text_save(Network_list, 'Network_bus.txt')

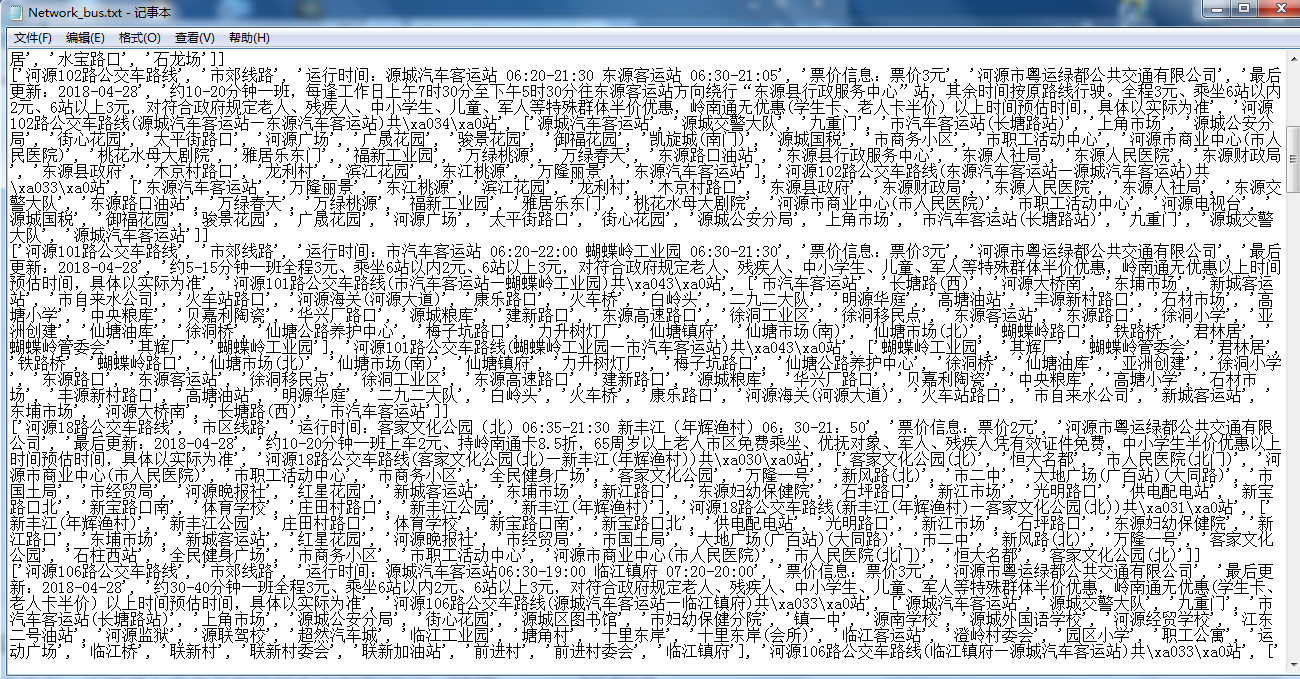
3.对爬了的数据进行文本分析,生成词云。
(1)首先打开爬取的数据的文件,通过jieba分词进行分词并通过空格分隔,然后生成词云。
代码:
from PIL import Image, ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import jieba
# 读入背景图片
abel_mask = np.array(Image.open("./公交车.jpg"))
# 读取要生成词云的文件
path = open('Network_bus.txt',encoding='utf-8').read()
# 通过jieba分词进行分词并通过空格分隔
wordlist_after_jieba = jieba.cut(path, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud().generate(wl_space_split)
my_wordcloud = WordCloud(
background_color='white', # 设置背景颜色
mask=abel_mask, # 设置背景图片
max_words=200, # 设置最大现实的字数
font_path='C:/Users/Windows/fonts/simkai.ttf',
max_font_size=50,
random_state=30, # 设置有多少种随机生成状态,即有多少种配色方案
scale=.5,
).generate(wl_space_split)
# 根据图片生成词云颜色
image_colors = ImageColorGenerator(abel_mask)
# my_wordcloud.recolor(color_func=image_colors)
# 以下代码显示图片
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
4.对文本分析结果进行解释说明。
我的图片是:

文本获取到的字符信息并不是我们想要的效果,因此,为了达到我们想要的效果,我就将所获取到的文本信息,生成一个词云图,我们更加直观的观察到我们

5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
遇到的问题:
1、开始无法安装wordcloud
解决办法:在网站https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载wordcloud-1.4.1-cp36-cp36m-win32.whl
然后在终端pip install wordcloud-1.4.1-cp36-cp36m-win32.whl

2、安装完wordcloud-1.4.1-cp36-cp36m-win32.whl 无法导入wordcloud
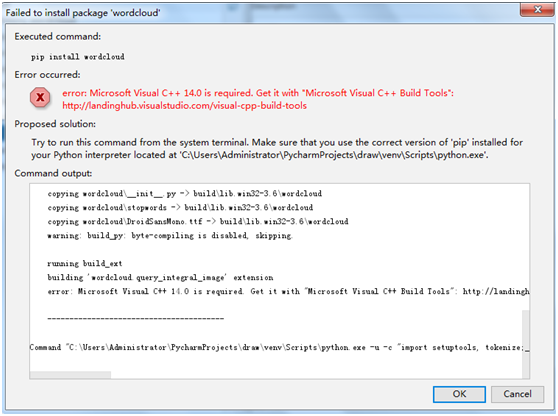
解决方法:通过网上查找我找到了如下的办法::
打开项目选择file-->settings...-->project-projiect interpreter右边选择上方长条框,选择Show All...,接着选择System Interpreter就可以了
数据分析思想及结论:
我的数据分析是打开我爬取的数据文件,然后通过结巴进行分词,最后生成词云。
结论:在做大作业的过程中,通过遇到问题然后找到解决问题的方法,我对爬虫有了进一步的了解,同时,也能从中发现自己的不足就是:对通过结巴进行数据分析不熟练。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
全部代码:
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
from PIL import Image, ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import jieba
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url ='http://heyuan.8684.cn/' ##开始的URL地址
start_html = requests.get(all_url, headers=headers)
#print(start_html.text)
Soup = BeautifulSoup(start_html.text, 'html.parser')
all_1 = Soup.find('div', class_='bus_kt_r1').find_all('a')#获取以数字开头所有路线
Network_list = []
for a in all_1:
href = a['href'] # 取出a标签的href 属性
html = all_url + href
second_html = requests.get(html, headers=headers)
#print(second_html.text)
Soup2 = BeautifulSoup(second_html.text, 'html.parser')
all_a2 = Soup2.find('div', class_='stie_list').find_all('a')
for a2 in all_a2:
title1 = a2.get_text() # 取出a1标签的文本
href1 = a2['href'] # 取出a标签的href 属性
# print(title1, href1)
html_bus = all_url + href1 # 构建线路站点url
thrid_html = requests.get(html_bus, headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'html.parser') # 以html.parser方式解析html
bus_name = Soup3.find('div', class_='bus_i_t1').find('h1').get_text() # 提取线路名
bus_type = Soup3.find('div', class_='bus_i_t1').find('a').get_text() # 提取线路属性
bus_time = Soup3.find_all('p', class_='bus_i_t4')[0].get_text() # 运行时间
bus_cost = Soup3.find_all('p', class_='bus_i_t4')[1].get_text() # 票价
bus_company = Soup3.find_all('p', class_='bus_i_t4')[2].find('a').get_text() # 公交公司
bus_update = Soup3.find_all('p', class_='bus_i_t4')[3].get_text() # 更新时间
bus_label = Soup3.find('div', class_='bus_label')
if bus_label:
bus_length = bus_label.get_text() # 线路里程
else:
bus_length = []
print(bus_name, bus_type, bus_time, bus_cost, bus_company, bus_update)
all_line = Soup3.find_all('div', class_='bus_line_top') # 线路简介
all_site = Soup3.find_all('div', class_='bus_line_site') # 公交站点
line_x = all_line[0].find('div', class_='bus_line_txt').get_text()[:-9] + all_line[0].find_all('span')[
-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = [] # 上行线路站点
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num == 2: # 如果存在环线,也返回两个list,只是其中一个为空
line_y = all_line[1].find('div', class_='bus_line_txt').get_text()[:-9] + all_line[1].find_all('span')[
-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = [] # 下行线路站点
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y, sites_y_list = [], []
information = [bus_name, bus_type, bus_time, bus_cost, bus_company, bus_update, bus_length, line_x, sites_x_list,
line_y, sites_y_list]
Network_list.append(information)
# 定义保存函数,将运算结果保存为txt文件
def text_save(content, filename, mode='a'):
file = open(filename, mode, encoding='utf-8')
for i in range(len(content)):
file.write(str(content[i]) + '
')
file.close()
# 输出处理后的数据
text_save(Network_list, 'Network_bus.txt')
# 读入背景图片
abel_mask = np.array(Image.open("./公交车.jpg"))
# 读取要生成词云的文件
path = open('Network_bus.txt',encoding='utf-8').read()
# 通过jieba分词进行分词并通过空格分隔
wordlist_after_jieba = jieba.cut(path, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud().generate(wl_space_split)
my_wordcloud = WordCloud(
background_color='white', # 设置背景颜色
mask=abel_mask, # 设置背景图片
max_words=200, # 设置最大现实的字数
font_path='C:/Users/Windows/fonts/simkai.ttf',
max_font_size=50,
random_state=30, # 设置有多少种随机生成状态,即有多少种配色方案
scale=.5,
).generate(wl_space_split)
# 根据图片生成词云颜色
image_colors = ImageColorGenerator(abel_mask)
# my_wordcloud.recolor(color_func=image_colors)
# 以下代码显示图片
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()