面向对象第三次作业总结
JML基础梳理及工具链
注释结构
- 行注释:
//@annotation - 块注释:
/*@ annotation @*/
两种注释方法均适用@开头,并将JML注释放在被注释成分的近邻上部。
常见表达式
-
原子表达式
esult表达式:表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值。这里此表达式的类型根据被注释的函数的返回值而定。old(expr)表达式:用来表示一个表达式expr在相应方法执行前的取值。当expr有被修改时,使用此表达式,表示expr被修改之前的值。这里有一点需要注意,对于一个引用对象,只能判断引用本身是否发生变化,即只能描述引用对象的地址是否发生变化,而不能描述对象的成员变量等是否发生变化。ot_assigned(x,y,…)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。ot_modified(x,y,…)表达式:限制括号中的变量在方法执行期间的取值未发生变化。onnullelements(container)表达式:表示container对象中存储的对象不会有null。
-
量化表达式
-
forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。使用的结构如下:(forall 类型 变量; 变量满足的限制; 在限制条件下的结果)
以下几种表达式均有类似的使用结构。
-
exists表达式:与forall表达式使用结构类似,为存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。 -
sum表达式:返回给定范围内的表达式的和。 -
product表达式:返回给定范围内的表达式的连乘结果。 -
max表达式:返回给定范围内的表达式的最大值。 -
min表达式:返回给定范围内的表达式的最小值。 -
um_of表达式:返回指定变量中满足相应条件的取值个数。
-
-
操作符
- 子类型关系操作符
E1<:E2,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。如果E1和E2是相同的类型,该表达式的结果也为真。 - 等价关系操作符
b_expr1<==>b_expr2或者b_expr1<=!=>b_expr2,其中b_expr1和b_expr2都是布尔表达式,这两个表达式的意思是 b_expr1==b_expr2 或者 b_expr1!=b_expr2 。 - 推理操作符
b_expr1==>b_expr2或者b_expr2<==b_expr1,即数理逻辑中的蕴含运算。 - 变量引用操作符
othing表示空集;everything表示全集。
- 子类型关系操作符
方法规格
-
前置条件(pre-condition)前置条件是对调用者的限制,即要求调用者确保条件为真。
-
后置条件(post-condition)后置条件是对方法实现者的要求,即方法实现者确保方法执行返回结果一定满足谓词的要求,即确保后置条件为真。
-
副作用范围限定(side-effects)assignable表示可赋值modifiable表示可修改- 多数情况下二者可以交换使用
-
signals子句signals子句的结构为
signals (Exception e) b_expr,当b_expr为true时,方法会抛出括号中给出的相应异常e。signals_only子句是对signals子句的简化版本,不强调对象状态条件,强调满足前置条件时抛出相应的异常。
类型规格
-
不变式invariant不变式是要求在所有可见状态下都必须满足的特性。可见状态主要包含以下几种:
对象的有状态构造方法(用来初始化对象成员变量初值)的执行结束时刻
在调用一个对象回收方法(finalize方法)来释放相关资源开始的时刻
在调用对象o的非静态、有状态方法(non-helper)的开始和结束时刻
在调用对象o对应的类或父类的静态、有状态方法的开始和结束时刻
在未处于对象o的构造方法、回收方法、非静态方法被调用过程中的任意时刻
在未处于对象o对应类或者父类的静态方法被调用过程中的任意时刻 -
状态变化约束constraint可以认为状态变化约束比上面的不变式放宽了一定的限制,它并不要求一定不发生变化,而是在变化过程中形成要满足一定的约束条件。
JML工具
-
openJML
可以根据JML对实现进行静态的检查,其中用于进行JML分析的部分在
solvers中,包括常见的如cvc4以及z3。 -
JMLUnitNG
可以根据JML自动生成对应的测试样例,用于进行单元化测试。
关于这两种工具的使用,实际情况如下所示。
JMLUnitNG使用实例
在这里我根据讨论区中的示例进行了尝试,过程如下。
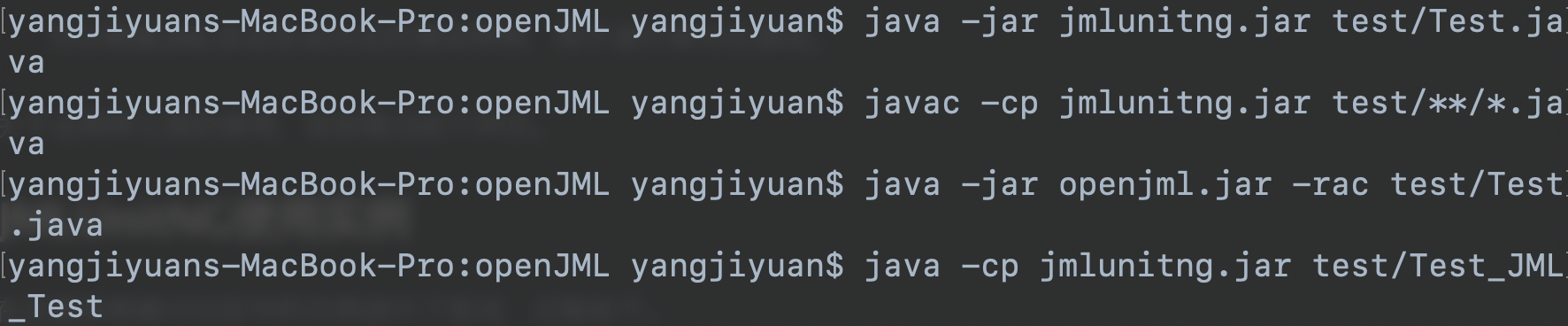
我在当前目录下的test文件夹下创建里一个名为Test.java的文件,然后上述四步基本上仿照讨论区的示例。
首先在Test.java所在文件目录下生成对应的测试用的文件。此时该目录下文件如下:

然后后续的指令分别进行的是对test中Test_JML_Data目录下的java文件进行编译,然后使用jmlc编译待测试文件。以上步骤完成之后,再直接使用第四条指令会报错,第四条指令是运行已经生成好的测试文件,查看测试结果,但是此前尚未对这个文件进行编译,因此,再执行一句:
javac -cp jmlunitng.jar test/*.java
这样,使用上述第四条指令之后,就可以看到测试效果:
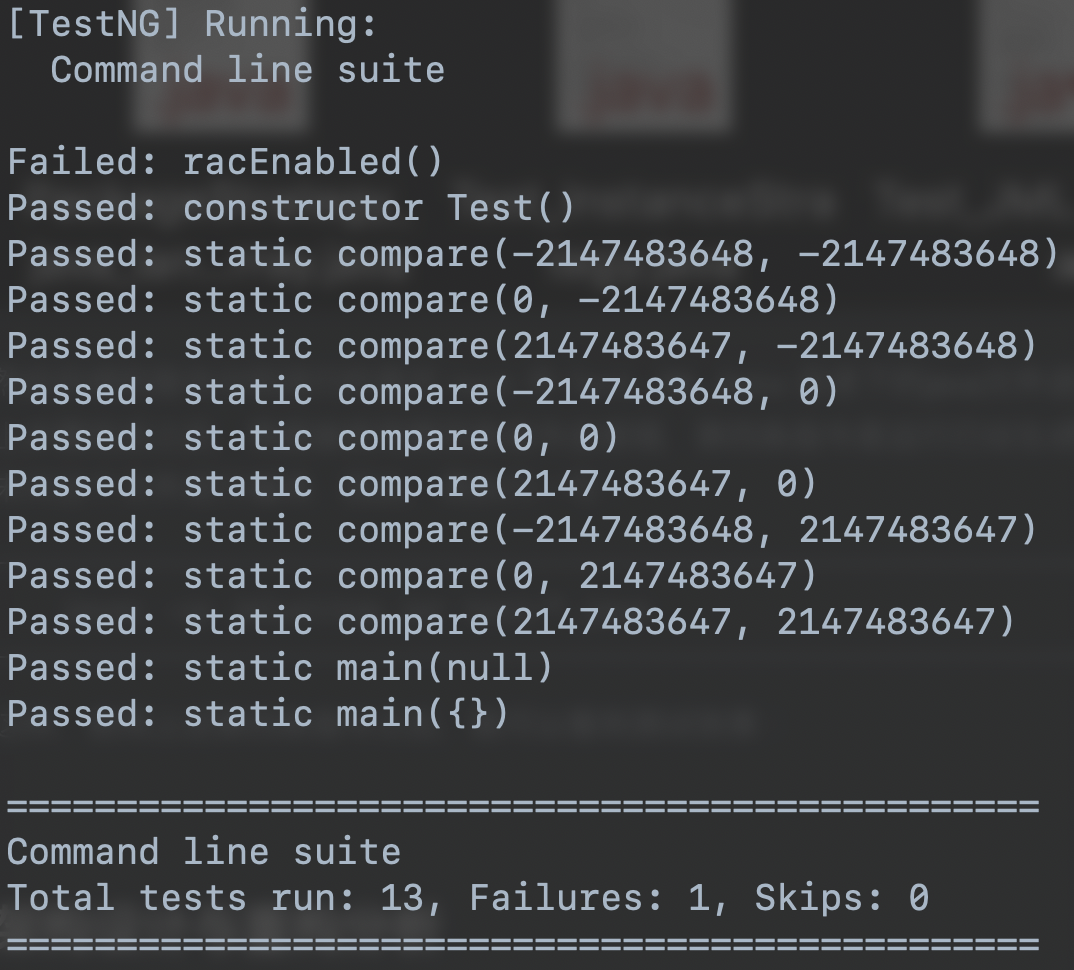
可以看到自动生成的用例对于compare函数测试,其测试方法是使用极端的数据进行组合,分别使用0、int类上限、int类下限,对这个函数进行测试。
架构设计与重构分析
第一次作业
- 结构分析
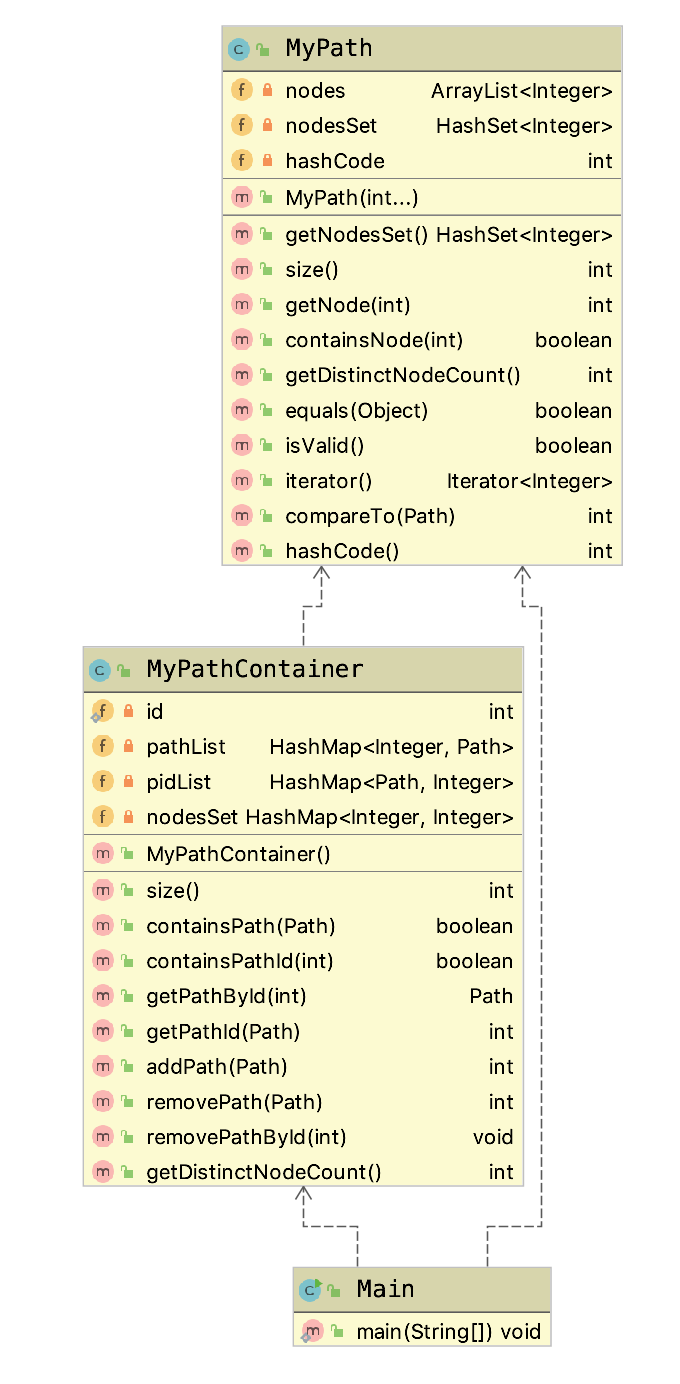
首先是关于第一次作业的结构设计。从整体上看层次比较简单,在主类Main中通过将MyPath和MyPathContainer两个类传给AppRunner函数,实现对这两个功能模块的测试。而在MyPathContainer这个类中,又因为涉及到对Path的操作,因此会一定程度上依赖于Path。
从细节上讲,在类MyPath中,主要进行了存取的操作,增加的操作只在初始化时存在,并没有删除的操作,保存路径的节点又是一个有序的结构,因此使用Arraylist进行存储。另外,由于涉及到要查找不相同的节点的个数,为了避免每次查找都统计一次浪费时间,直接采用将统计的操作平摊到时间复杂度不容易减小的初始化操作中,并使用HashSet来进行存储,这样在尝试获取不同节点个数时,只要获取此set的size即可。
在类MyPathContainer中,有比较多的增删操作,同时还涉及从Path到PathId以及反向的双向查找,因此考虑使用两个HashMap,分别记录双向的索引关系。此外,在这个类中要统计所有Path的不同节点的个数,因此再次维护一个HashMap,目的是将获取不同节点个数的操作平摊到增加路径和删除路径中,这个HashMap的Value部分是这一个节点在全局中出现的次数,用于在删除路径时判读是否要删除此节点。
public int removePath(Path path) throws PathNotFoundException {
if (path != null && path.isValid() && pathList.containsValue(path)) {
int oldId = pidList.get(path);
pathList.remove(oldId, path);
pidList.remove(path, oldId);
for (Integer node : ((MyPath) path).getNodesSet()) {
if (nodesSet.get(node) >= 2) {
nodesSet.replace(node, nodesSet.get(node) - 1);
} else {
nodesSet.remove(node);
}
}
return oldId;
} else {
throw new PathNotFoundException(path);
}
}
- 复杂度与依赖度分析
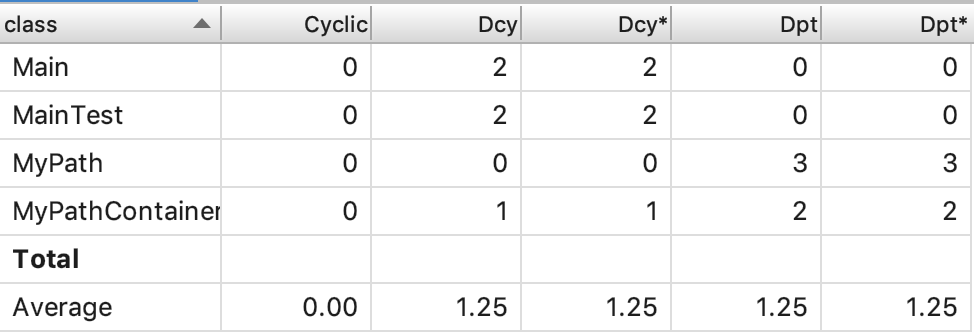
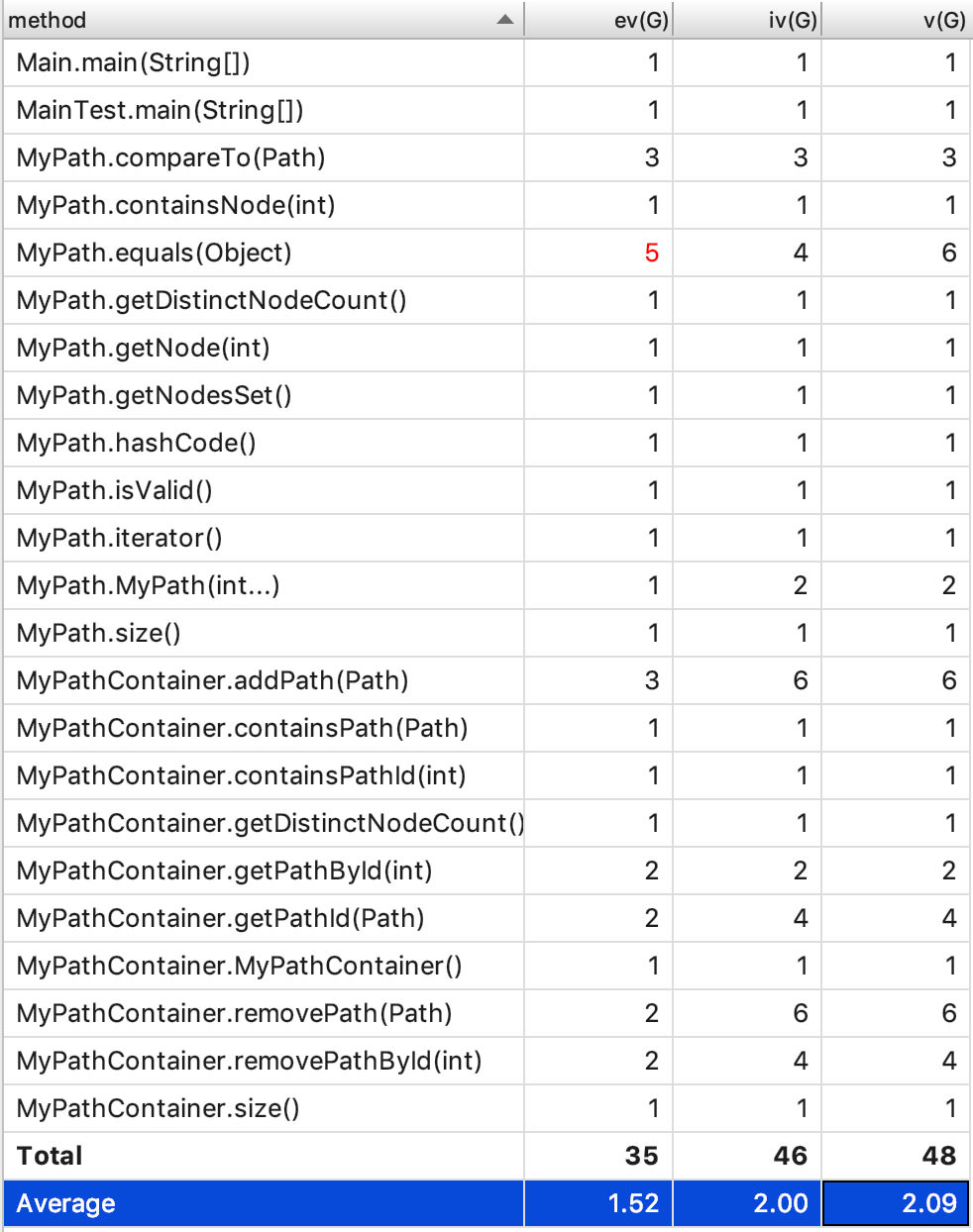
因为是第一次作业,方法的功能都不算很难,因此从整体上看复杂度与相互之间的依赖度大体上在比较合理的范围之内。其中,在MyPath类中,equals()方法的复杂度相对较高,其实我认为只是其他方法实现的功能比较基础,并不需要复杂的条件判断等,而此方法根据JML的描述,需要分不同的情况讨论,同时需要有一个循环遍历的过程。其他的方法中复杂度相对较高的,应该是对Path的增加和删除的方法,由于这样的方法不可避免地要进行遍历的操作,自身的时间复杂度不容易下降,因此将其他操作分摊到这些方法中,导致了其复杂度的相对偏高。
第二次作业
- 结构分析
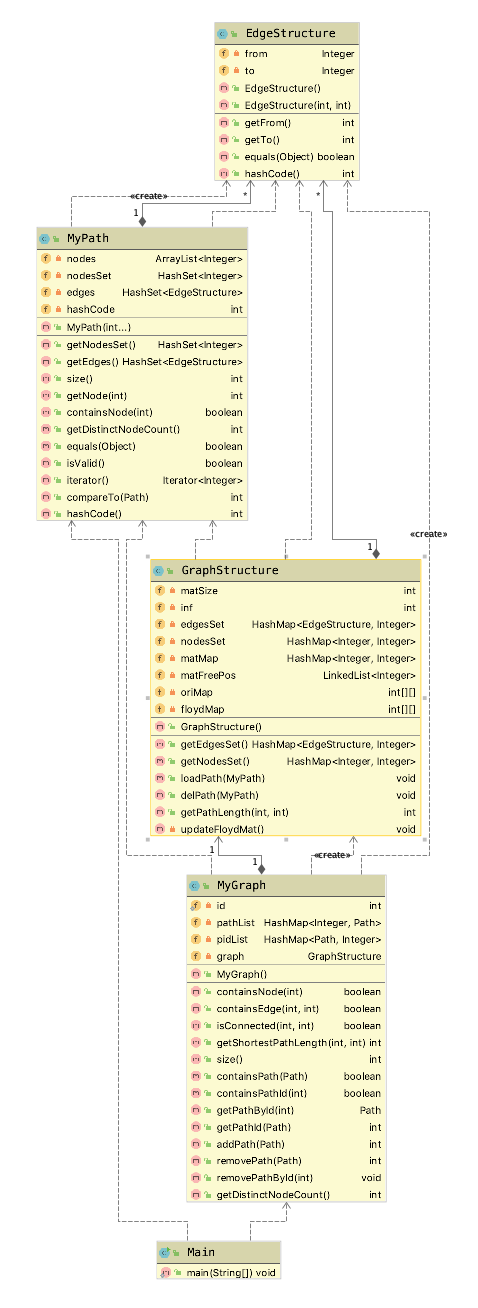
首先是关于继承与重构的分析。从上面的图中可以看到,在MyPath类中基本完全继承于上一次作业中的设计,然后新增加的MyGraph类,与之前MyPathContainer类相同的方法基本没有做改变,直接来自于上一次作业,这里做的不好的一点,就是没有必要使用复制的方式,应该直接让MyGraph直接继承 MyPathContainer类即可。
至于重构方面,我对之前的MyPathContainer的成员变量进行了增加。增加的成员变量是一个GraphStructure类型的变量。因为这次涉及到了更多关于图的操作,因此我将图这个数据结构单独封装成一个类,即上面的GraphStructure类,里面我使用了静态数组存储图的邻接矩阵,考虑到指导书上对于图的节点数的限制,我使用了一个LinkedList的结构保存当前空闲的节点,并通过一个HashMap结构存储节点编号与静态矩阵的索引号的映射。基于这个邻接矩阵,我使用Floyd算法,在每次对图进行变更时,一次性计算出图中任意两点之间的最短距离,将查找最短距离的操作转化成对于静态数组的访问,以节省每次使用单源最短路径算法的计算成本。
如上所言,由于我将与对图有关的操作转移到了GraphStructure这个类中,因此在第一次作业中在MyPathContainer中进行路径的增加和删除操作,实际上是改成了调用GraphSturcture实例中的方法,降低了这个方法的复杂度,对功能进行了更好的分离。
// 与前一段代码相比较,其中删除节点的细节已经被封装在`GraphStructure`这个类中
// 在`MyGraph`类中只是进行对应的方法调用
public int removePath(Path path) throws PathNotFoundException {
if (path != null && path.isValid() && pathList.containsValue(path)) {
int oldId = pidList.get(path);
pathList.remove(oldId, path);
pidList.remove(path, oldId);
for (Integer node : ((MyPath) path).getNodesSet()) {
if (nodesSet.get(node) >= 2) {
nodesSet.replace(node, nodesSet.get(node) - 1);
} else {
nodesSet.remove(node);
}
}
return oldId;
} else {
throw new PathNotFoundException(path);
}
}
此外,一个没有必要的设计就是上图中的EdgeStructure结构,我本意是希望通过这个结构判断两条边是否是同一条边,因此也为这个类重写了equals()方法和HashCode()方法。其实这个类完全可以通过两级的HashMap的嵌套来实现。
- 复杂度与依赖度分析

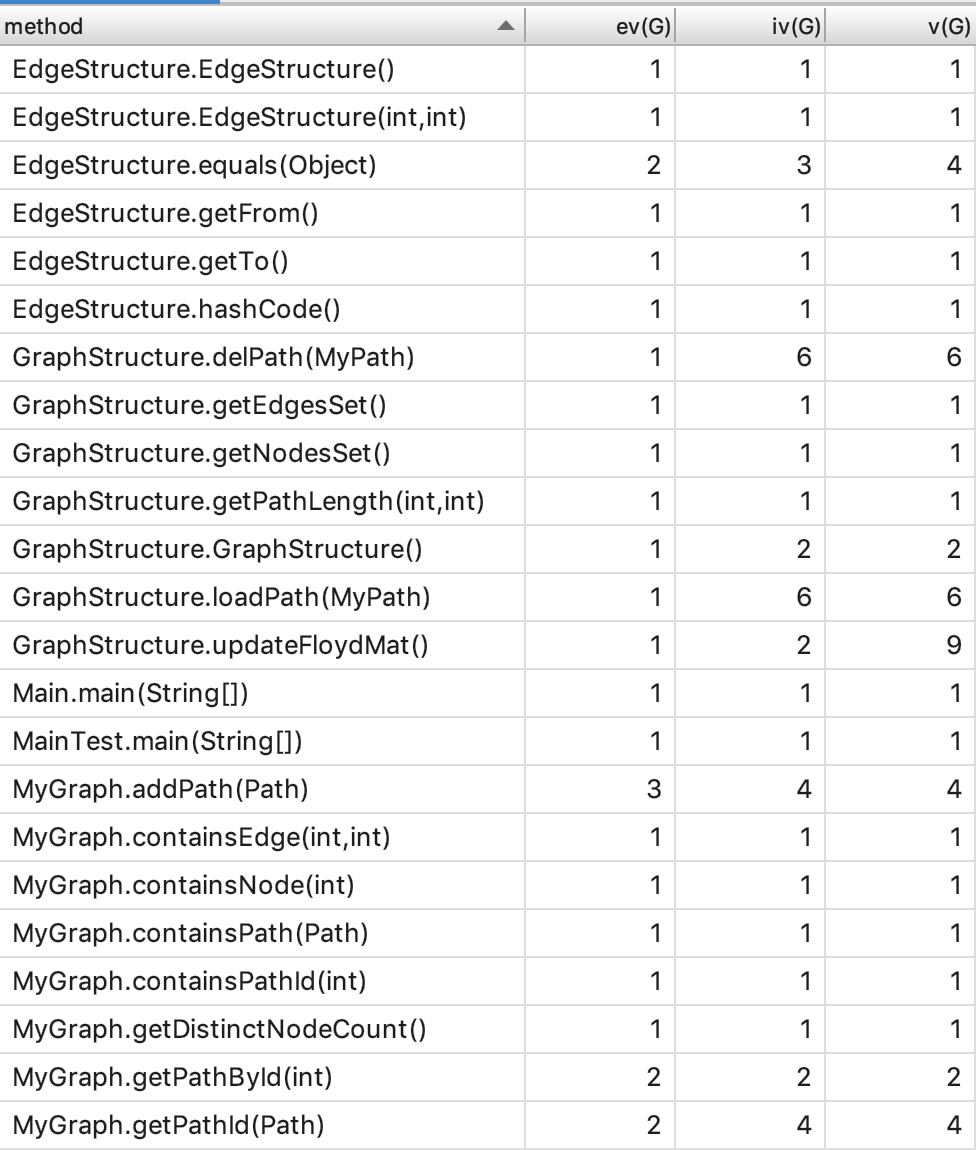

如果如上面所言,使用两个HashMap嵌套的结构来取代自己创建的EdgeStructure类,可以减少其他类对这个类不必要的依赖。其余的依赖均在正常情况之内。
这次复杂度比较高的地方,主要集中在了与图有关的操作上,比如GraphStructure类中加载一条路径以及删除一条路径的操作,以及使用Floyd算法更新图的操作。其实在加载路径(loadPath函数)以及删除路径(delPath函数)中,由于之前设计的不好的EdgeStructure类,导致为了加载每一条边,还会额外增加一层循环。
for (EdgeStructure edge : path.getEdges()) {
// imitate add node to nodesSet
if (edgesSet.keySet().contains(edge)) {
edgesSet.replace(edge, edgesSet.get(edge) + 1);
} else {
edgesSet.put(edge, 1);
// edge already has two ori
oriMap[matMap.get(edge.getFrom())]
[matMap.get(edge.getTo())] = 1;
updateFloydMat = true;
}
}
如果对这里进行优化的话,完全可以进一步降低复杂度。而且在实际测试中,可以看出这个类的hashCode方法重写地不好,导致散列表的散度不够,会使得访问HashMap的时间成本增加。总而言这,这样的设计是一个很大的败笔。
第三次作业
- 结构分析
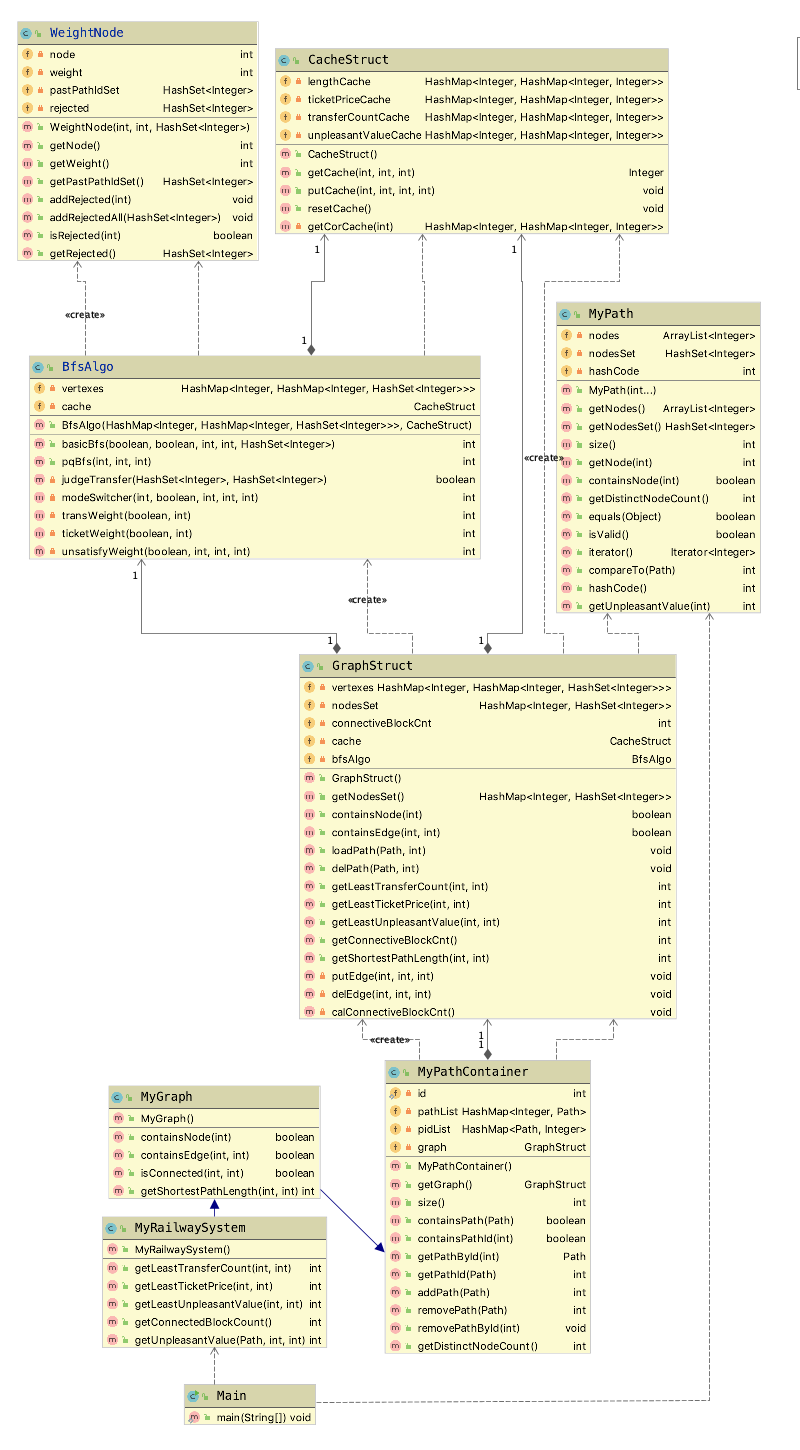
首先是继承与重构的分析。这次作业为了改进结构,没有直接对原来的函数进行复制,而是直接使用了继承的方式。与第一次作业相比,MyPath类以及MyPathContainer类基本上没有变化。然而与第二次作业相比,我对MyGraph类以及GraphStruct类进行了重构,重构的原因是因为指导书增加了增删指令的条数,继续沿用第二次的结构,但是会因为时间复杂度过高导致CPU time超时。
这次我采用了BFS+Priority+Cache的策略。我将这一结构分别封装在了BfsAlgo类以及CacheStruct类中,同时为了辅助实现,又封装了一个WeightNode的类。主要的思路是,通过BFS进行遍历,同时根据指定的权重计算方式(在这里我使用了modeSwitcher函数以及三种权重的计算函数来实现),计算当前路径到达此节点时的权重,并根据此创建WeightNode对象,将其加入优先队列中。每次从优先队列中取队首,作为最小权重,重复此过程,直到找到为止。由于每次第一次从优先队列里取出的WeightNode是到当前节点的最短加权距离,因此将其保存到cache,以便下次进行访问。
- 依赖度和复杂度分析
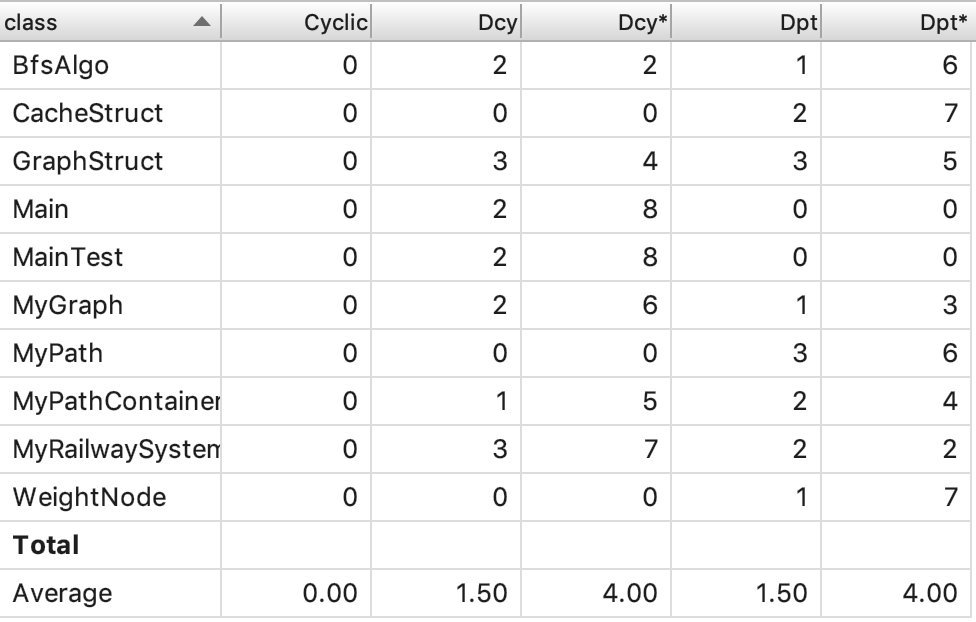
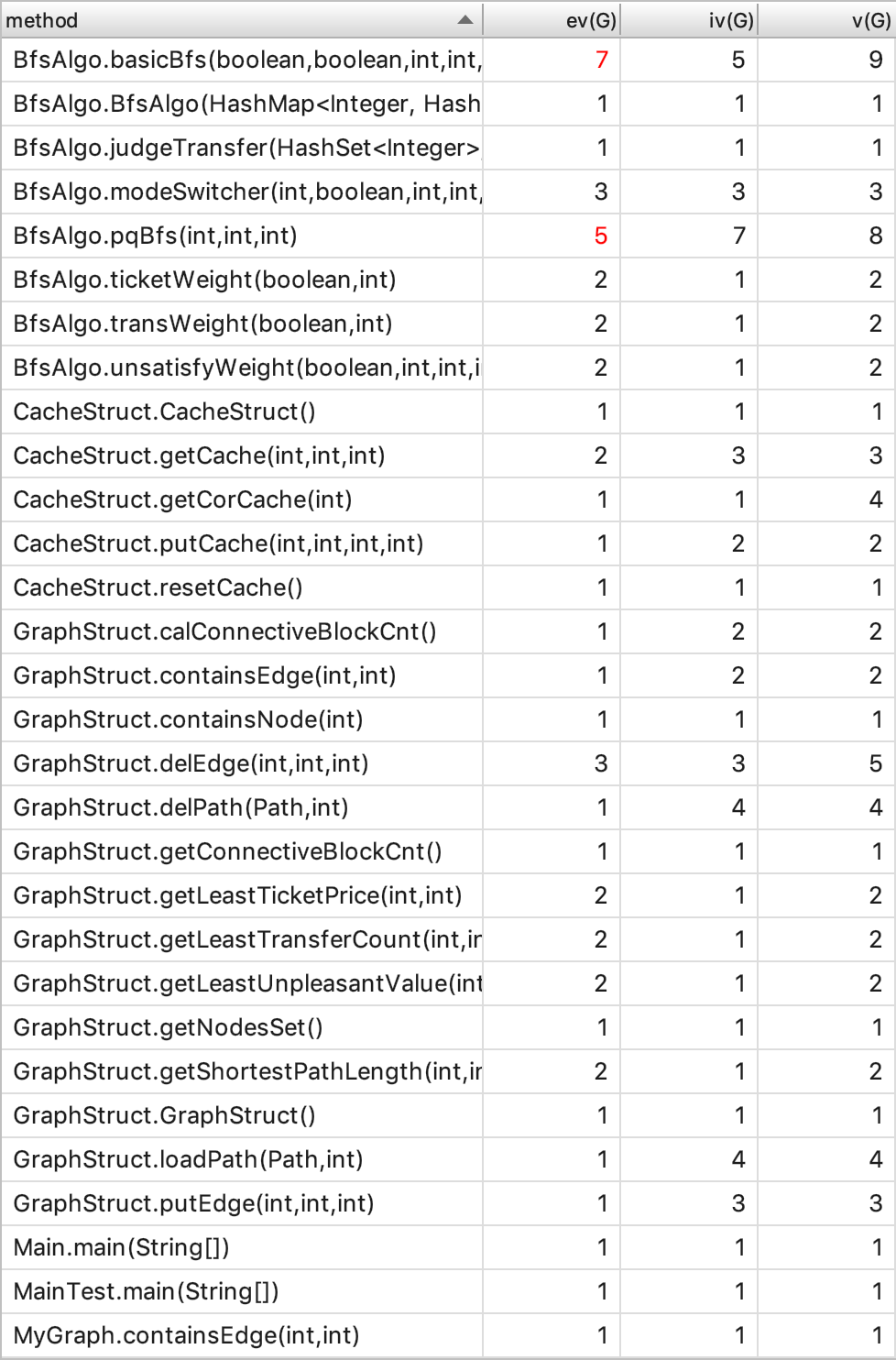
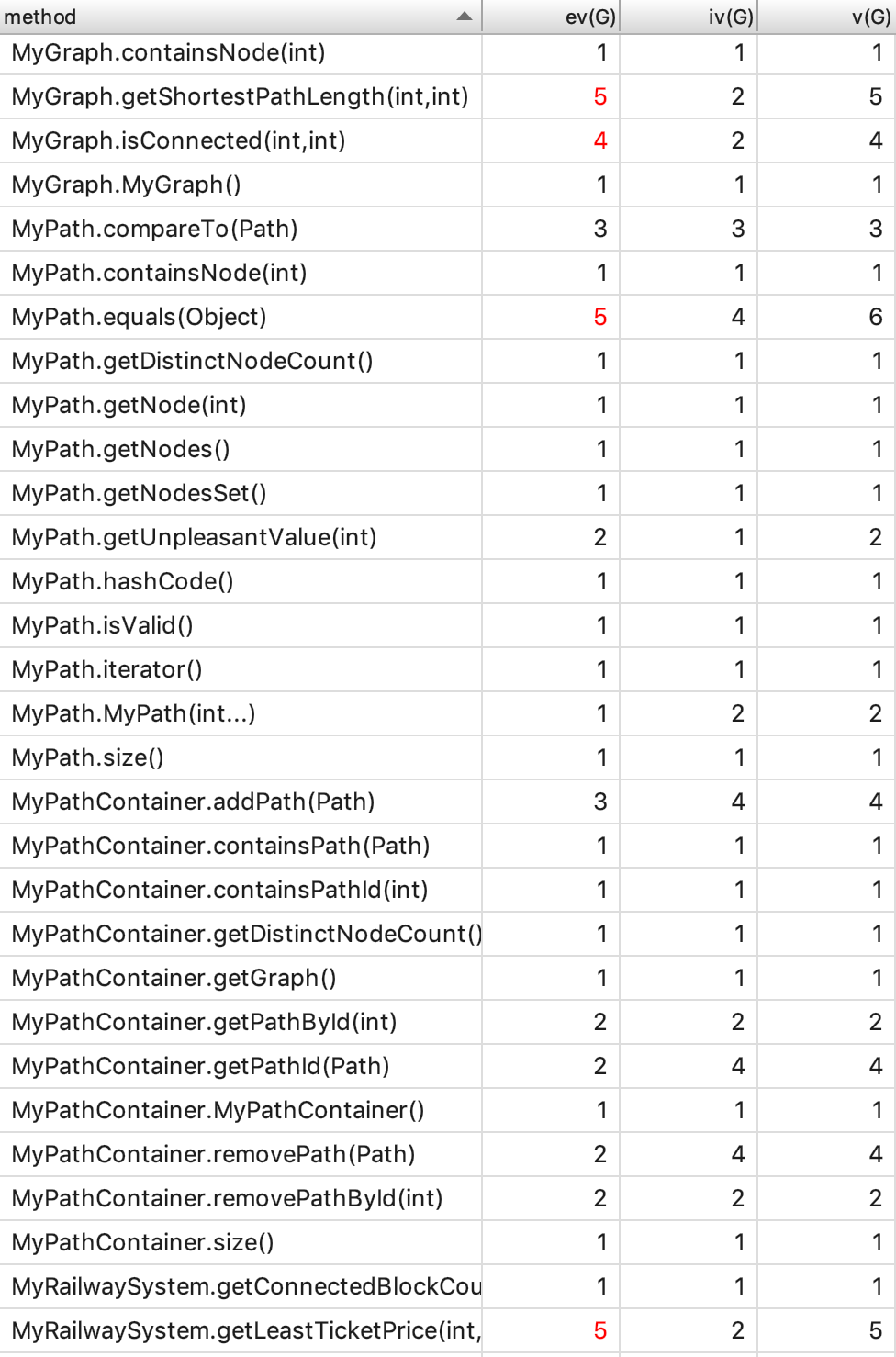

由于相对于第二次作业进行了一些改善,这次不必要的依赖有所减少。这次比较复杂的方法都集中在了这次作业新增的功能上。其原因在于这些功能增加了对算法的要求,而这次使用的BFS也不再是单纯的BFS,其中增加了很多诸如标记、存储、以及遍历的条件判断的操作,因此复杂度不免会增加。
bug与修复
-
第一次作业
这次作业在强测和互测中均没有被爆出bug。在程序写完进行调试的过程中出现的bug是在处理路径的id部分,由于最开始没有审题,误将id从0开始计算。
这次作业从完成到最终提交其实也经历了很多重构以及修改的过程。最开始的版本,由于对操作要求缺乏分析,以及对Java的数据结构类的实现方式的不清楚,我在
MyPath以及MyPathContainer两个类中均只使用了Arraylist结构,后来通过看讨论区以及看了一些源码之后,才做出了之前所述的调整。 -
第二次作业
这次作业在强测和互测中均没有被爆出bug。在程序写完进行调试的过程中也没有遇到bug,但是由于最开始结构设计与算法使用的不合理,导致本地自己测试时CPU时间偏长。
最开始我使用的是BFS+cache的模式,其实这种做法本身没有问题,但是正如前面所讲,我使用了自己构造的
EdgeStruct类作为HashMap的索引,然而hashCode方法重写地不好,导致经常会有不止一个对象拥有同一个hashCode的情况,因此在数据集比较大的情况下,使用JProfiler查看各部分对CPU时间的贡献,可以看到对于这个HashMap的操作,比如put方法、contains方法等等,都会占据比较多的CPU时间。因此,我当时选择了多源最短路径的Floyd算法,进行了一次重构。 -
第三次作业
这次作业的情况非常糟糕。首先这次被大面积杀伤的原因在于当时使用的BFS+优先队列的方法是我从周围的同学了解到并相互讨论得到的方法,感觉从清晰度方面并不能解释地很清楚,因此出现了一些意料之外的情况,比如当到达一个节点后,我通过当前节点的邻接节点是否被标记过来判断是否应当跳过这个节点,但是完全存在这种情况,使得一个节点被标记后不能访问,但是有一条别的路径,如果可以访问这个节点,将能够得到更短的带权路径长度。因此我通过为每一个权重节点增加一个reject容器,里面保存对于这一个路径上的节点所不能访问的节点,然后每一条路径根据自身的情况判断,而不会对其他路径造成影响。
使用的反例如下:
PATH_ADD 1 2 PATH_ADD 1 3 2 4 LEAST_TRANSFER_COUNT 1 4正确结果显然为0,但是因为上面所讲的那个错误,我在标记了2节点后,3节点无法访问2节点,因此统计得到的输出结果为1。
规格撰写与理解的心得体会
使用规格的目的是在于能够用一种相对于自然语言而言更加严谨、更加没有二义性的方式对一个方法或者类的功能进行描述,这样在多人进行协作开发,而且开发的项目对于正确性与准确性的要求比较严格的时候,更能够保证不会因为不同的成员对于方法或者类的功能理解缠身歧义,导致开发过程中出错。
在实际体会了这种模式之后,一方面确实看到,如果确实能够做到描述严谨,JML可以对规格进行非常客观的描述,这种描述并不是实现思路,而是提供对于功能与特性的理解。但是与此同时,我也感觉到对于我来说JML其本事还是很有难度的,对于一个相对比较复杂的功能,JML的表述会显得很长,而且有时为了简化表述,还需要借助一些本来并不一定需要实现的方法,并且为这些方法还要单独写规格。感觉这样不论是书写还是理解,都会产生一定的困难,特别是当读者的编程水平并不高的时候,有可能反而因为其复杂性造成理解的偏差。因此,我觉得在一些要求比较高的特定工作领域中,使用JML更能够进行规范,但是在一些领域,比如小团队进行普通的应用开发时,个人感觉使用比较详细的自然语言更能够节约开发成本,提高效率。