1 标准化 & 归一化
导包和数据
import numpy as np from sklearn import preprocessing data = np.loadtxt('data.txt', delimiter=' ')

1.1 标准化 (Z-Score)
x'=(x-mean)/std 原转换的数据为x,新数据为x′,mean和std为x所在列的均值和标准差
标准化之后的数据是以0为均值,方差为1的正态分布。
但是Z-Score方法是一种中心化方法,会改变原有数据的分布结构,不适合对稀疏数据做处理。
# 建立 StandardScaler 对象 z_scaler= preprocessing.StandardScaler() # 用 StandardScaler 对象对数据进行标准化处理 z_data = z_scaler.fit_transform(data)

1.2 归一化(Max-Min)
x'=(x-min)/(max-min),min和max为x所在列的最小值和最大值
将数据规整到 [0,1] 区间内(Z-Score则没有类似区间)
归一化后的数据能较好地保持原有数据结构。
数据中有异常值时,受影响比较大
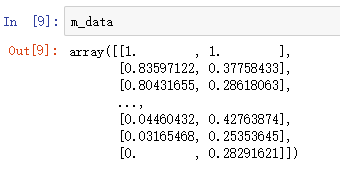
# 建立MinMaxScaler模型对象 m_scaler = preprocessing.MinMaxScaler() # 使用 MinMaxScaler 对象 对数据进行归一化处理 m_data = m_scaler.fit_transform(data)
2 离散化 / 分箱 / 分桶
离散化,就是把无限空间中有限的个体映射到有限的空间中
导包和数据
import pandas as pd from sklearn.cluster import KMeans from sklearn import preprocessing df = pd.read_table('data1.txt', names=['id', 'amount', 'income', 'datetime', 'age'])
数据基本情况

2.1 针对时间数据的离散化
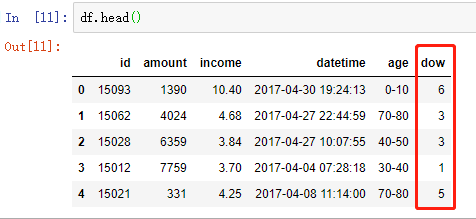
方法 1 :使用 pd.to_datetime 及 dt.dayofweek
# 将数据转成 datetime 类型 df['datetime'] = pd.to_datetime(df['datetime']) # 显示 周几 df['dow'] = df['datetime'].dt.dayofweek
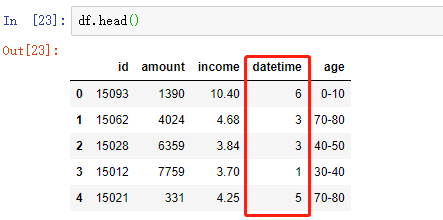
方法 2:纯手工打造(可以忽略了)
# 将时间转换为datetime格式,Python3中,map返回一个迭代器,所以需要list一下,把其中的值取出来 df['datetime'] = list(map(pd.to_datetime,df['datetime'])) # 离散化为 周几 的格式 df['datetime']= [i.weekday() for i in df['datetime']]
2.2 针对连续数据的离散化
连续数据的离散化结果可以分为两类:
一类是将连续数据划分为特定区间的集合,例如{(0,10],(10,20],(20,50],(50,100]}
一类是将连续数据划分为特定类,例如类1、类2、类3
常见实现针对连续数据化离散化的方法如下。
分位数法:使用四分位、五分位、十分位等分位数进行离散化处理
距离区间法:可使用等距区间或自定义区间的方式进行离散化,该方法(尤其是等距区间)可以较好地保持数据原有的分布
频率区间法:将数据按照不同数据的频率分布进行排序,然后按照等频率或指定频率离散化,这种方法会把数据变换成均匀分布。好处是各区间的观察值是相同的,不足会改变了原有数据的分布状态。每个桶里的数值个数是相同的
聚类法:例如使用 K 均值将样本集分为多个离散化的簇
2.2.1 距离区间法:自定义分箱区间实现离散化
# 自定义区间边界 bins = [0, 200, 1000, 5000, 10000] # 按照给定区间 使用 pd.cut 将数据进行离散化 df['amount_grp1'] = pd.cut(df['amount'], bins=bins)
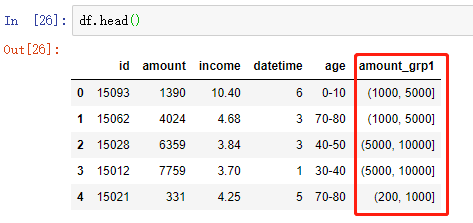
附:实现离散化 并添加自定义标签(另外一份数据中的)
bins = [0,2,10,300] labels = [ '<2', '<10','<300'] # right == False : 左闭右开,不加此项,默认为左开右闭的 df['price_level'] = pd.cut(df.price,bins=bins,labels=labels, right=False)
2.2.2 频率区间法:按照等频率或指定频率离散化
df['amount3'] = pd.qcut(df['amount'], 4, labels=['bad', 'medium', 'good', 'awesome'])
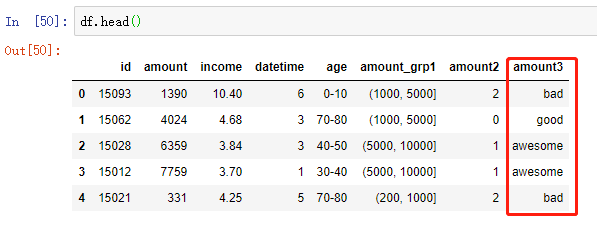
2.2.3 聚类法实现离散化
1 # 获取要聚类的数据 2 df_clu = df[['amount']] 3 4 # 创建 KMeans 模型并指定要聚类数量 5 model_kmeans = KMeans(n_clusters=4, random_state=111) 6 7 # 建模聚类 8 kmeans_result = model_kmeans.fit_predict(df_clu) 9 10 # 将新离散化的数据合并到原数据框 11 df['amount2'] = kmeans_result
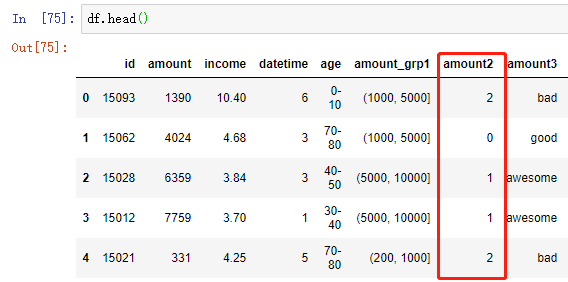
对第 5 行代码的补充:
创建KMeans模型并指定要聚类数量,分成4组
random_state 随机数种子,指定之后,每次划分的训练集测试集划分方式相同
如果指定的random_state相同,每次生成的随机数都是一样的
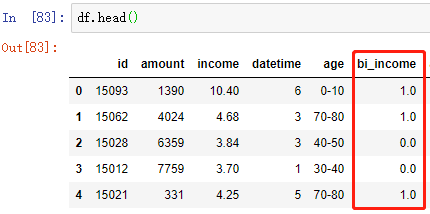
3 二值化
根据某一阈值,将数据分成两类,得到一个只拥有两个值域的二值化数据集
# 建立Binarizer模型对象,利用income这一列的平均值作为阈值,进行二值化 bi_scaler = preprocessing.Binarizer(threshold=df['income'].mean()) # Binarizer标准化转换 bi_income = bi_scaler.fit_transform(df[['income']]) df['bi_income'] = bi_income