摘 要
在医学图像分割任务中,重点是从背景像素中检测和区分出代表感兴趣区域的前景像素。到目前为止,背景像素构成了图像中大多数像素。因此,对于背景像素而不是前景像素的检测存在一致的偏差。这导致基于深度学习的医学图像分割频繁出现的假阴性像素分类,即前景像素被错误地分类为属于背景像素类别。在本文中,我们提出了一种新的注意力机制来解决这种较高的假阴性检测率。我们的方法试图引导模型进行更多的假阳性检测,从而纠正由于训练数据不平衡而导致的分类结果不平衡。提出的注意力机制具有三种实现方式:(1)显式指导模型以检测误报;(2)通过转向相反的假阴性来隐式学习假阳性;(3)在多任务环境中,共同引导假阳性和假阴性的学习。为了验证提出的方法,我们在一个比较难的任务中验证了我们提出的网络:对肿瘤核心进行分割。在BRATS 2018训练数据上进行5次交叉验证后,我们的模型优于9个最新的基准模型,包括:空间注意力,空间通道注意力和自我注意力。更具体地说,我们的第三种实现将假阴性降低了10.4%,而假阳性的检增加却可以忽略不计。我们的第三个实施方案还将网络的Hausdorff距离提高了28%以上,同时将IoU值提高了3%以上。除了显著的性能提升外,我们提出的注意机制通过一个有效的感受野具有直观的可解释性。我们相信我们提出的可解释的注意力机制,可以帮助广泛的医学应用中更安全的计算机辅助诊断。在审查期间,为了保持保持匿名,隐藏了我们在GitHub上的代码的链接。
关键字:注意机制,可解释的AI,可解释性,表征学习,分割,医学图像分析,计算机视觉。
1. 介绍
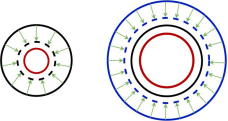
注意力机制的深度学习方法最近已经从计算机视觉迁移到医学图像分析中以解决分割任务。注意力集中的目的是把学习的重点放在感兴趣的显著区域(ROI),也就是前景像素,最小化ROI中包含背景区域的错误分类。注意力机制是通过隐含特征表征中的加权步骤实现的,使网络重点集中在ROI区域。但是,在医学图像中,前景像素通常是严重不足。导致偏向背景区域的检测误差,会造成真阳性低和假阴性高,尤其是在ROI边缘(见图5)。与FN检测率相比,假阳性检测率几乎可以被忽略不计(见附录A)。显然,减少FN检测是增加DL-驱动分割的效用的关键挑战。注意力机制是改善TP检测的方法,但是现有的方法不能充分减少FNs。现有的注意力机将注意力集中在标记为ROI的前景区域上,我们称之为TPs。理想情况下,模型是能够检测到整个ROI的,但是对背景像素的偏差阻碍了现有的注意力机制,导致图中黑色圆圈区域。为了克服现有注意力机制的高FN率,我们提出了一种代替策略,将其称为关注FP的注意力机制。直觉是可以通过鼓励偏向FP来减少FN,特别是在TP边界附近,图中显示了这一点。我们设计的注意力机制将学习如何专注于扩展的ROI(蓝色实心圆)。如上一段所述,在发生收缩之后,最终会导致检测到更多的TP(红色圆圈更靠近黑色圆圈,其中左右两个黑色圆圈相同)。在文本中,我们介绍了我们关注FP注意力机制的三种实现方式。值得注意的是,我们提出的方法既不需要额外的FP注释,也不需要修改原始数据分布,否则可能会导致信
息丢失。
2. 相关工作
我们首先简要介绍一些关于关注TP注意力的代表性注意力机制。然后,我们将有效感受野的概念描述为构建关注FP的神经网络的理论。
注意力机制 根据关注的目标(例如,关注什么,在哪里关注)。然后,大多数现有的注意力机制可以分为三类:通道注意力机制(例如:特征图每个通道的重要性),空间注意力机制(例如:每个特征图空间位置的重要性),空间通道混合注意力机制(例如:特征图在每个通道上每个空间位置的重要性)。通道注意力机制是根据每个通道最具代表性的特征(例如:平均值,最大值或者两者)。在空间注意力中,已使用了一种自注意力机制,或来自深层的的语义特征被用作“key”,用来增强浅层的表征学习。
有效感受野 在卷积神经网络的一层中,与下一层神经元对应的区域大小称之为“感受野”,其中感受野的中心对神经元的影响最大。然而,研究发现,在整个感受野中像素的影响分布类似于高斯分布。因此,在前向传播中,梯度信号以平方指数的方式从RF中心空间衰减。因此,只有一小部分RF有助于输出,该有效区域称之为“有效RF”(ERF)。随着网络深度的增加,RF的ERF也随之减少。更重要的是,已证明ERF的大小受神经网络拓扑结构的影响。通过将ERF与潜在的空间嵌入,我们可以以一种可解释的方式灵活地控制模型的注意力。
3. 方法
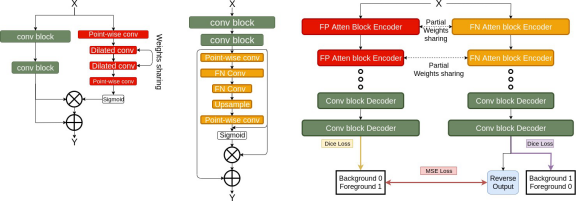
我们提出了三种方法来实现paying attention to FP。在每个小节中,我们首先介绍我们使用的技术。然后,我们解释如何如何与以前的应用方法不同地应用这些技术,以实现我们的注意力机制。在实现中,我们按照图5中左侧的流程,用注意力模块代替了编码器中的卷积模块。
3.1 False Positive Attention(FPA)
我们通过应用卷积神经网络去学习更好的平滑ERF,从而提出首次提出 False Positive Attention (FPA) ,它是从原始的ERF中扩展来的,但由在相同深度的空洞卷积层引导。空洞卷积层通过扩展RF合并相邻的信息。进一步证明,在相同深度下,空洞卷积的ERF大于卷积层的ERF。另一个针对半监督学习的相关工作使用空洞卷积把判别特征转换成临近的非判别特征,从而导致更多的FPs。我们提出的FPA是根据这两项工作开发的。为了聚合ERF周围区域的信息汇总到ERF中,使用卷积层和空洞卷积层的平均输出是直观的。但是,为FP attention创建更大的平滑ERF,我们使用sigmoid函数而不是取平均值。Softmax并没有被使用,因为我们想在整个张量中加权。在实现过程中,我们的注意力模块使用两个并行分支,它们具有相同的深度。主分支处理视觉信息,而注意分支生成FP注意权值,其结果是其ERF较大。
3.3 M-FPA和D-RFNA(集成)的多任务
然后,我们将一个M-FPA和另一个D-RFNA结合起来,形成一个多任务集成网络,如图2所示。在集成网络的编码部分,MFPA和DRFNA共用相同的主分支。这样做是为了得到正则化的效果。在集成网络解码部分,MFPA和DRFNA使用两个独立的分支进行稳定的优化。我们分别使用两个损失函数去训练两个编码器分支。此外,我们强制MFPA和DRFNA分支的具有相似的输出,将DRFNA的输出标签翻转回1(前景)和0(背景),会添加此MSE正则化损失。