一、算法原理
根据距离和密度来聚类
- 选取起始点,如果所有点都已经当选过起始点或者已经纳入类别,则停止
- 将跟选取点距离小于一定阈值的点纳入一个集合
- 如果步骤2的点个数大于一定数值,则纳为一个类别,并且在这个类别中再选取一个中心点然后进入步骤2,否则进入步骤1
二、Code
1 from scipy.spatial import distance 2 from sklearn.neighbors import NearestNeighbors 3 from sklearn.cluster.dbscan_ import DBSCAN 4 from sklearn.cluster.dbscan_ import dbscan 5 import numpy as np 6 7 from sklearn.cluster.tests.common import generate_clustered_data 8 9 min_samples = 10 10 eps = 0.0309 11 12 X = generate_clustered_data(seed=1, n_samples_per_cluster=1000) 13 14 D = distance.squareform(distance.pdist(X)) 15 D = D / np.max(D) 16 core_samples, labels = dbscan(D, metric="precomputed", eps=eps, 17 min_samples=min_samples)
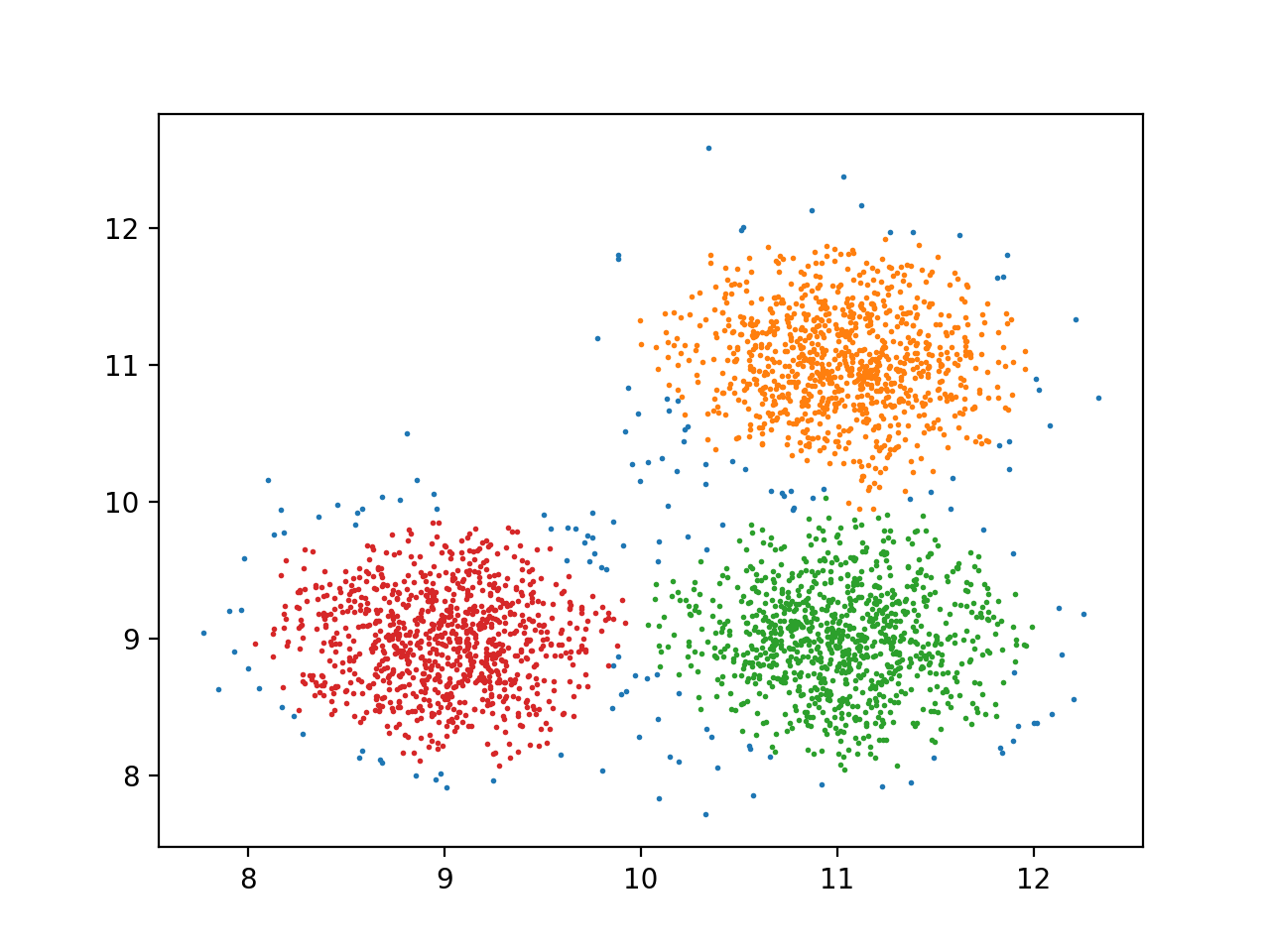
三、结果
有图可得,这种类型的聚类其实用DBSCAN并不是很好,不如kmeans。DBSCAN更适合环状的聚类,或者高密度的形状聚类