1、AT&T格式汇编
在 Unix 和 Linux 系统中,更多采用的还是 AT&T 格式,两者在语法格式上有着很大的不同:
-
在 AT&T 汇编格式中,寄存器名要加上 '%' 作为前缀;而在 Intel 汇编格式中,寄存器名不需要加前缀。例如:
AT&T 格式 Intel 格式 pushl %eax push eax -
在 AT&T 汇编格式中,用 '$' 前缀表示一个立即操作数;而在 Intel 汇编格式中,立即数的表示不用带任何前缀。例如:
AT&T 格式 Intel 格式 pushl $1 push 1 -
AT&T 和 Intel 格式中的源操作数和目标操作数的位置正好相反。在 Intel 汇编格式中,目标操作数在源操作数的左边;而在 AT&T 汇编格式中,目标操作数在源操作数的右边。例如:
AT&T 格式 Intel 格式 addl $1, %eax add eax, 1 -
在 AT&T 汇编格式中,操作数的字长由操作符的最后一个字母决定,后缀'b'、'w'、'l'分别表示操作数为字节(byte,8 比特)、字(word,16 比特)和长字(long,32比特);而在 Intel 汇编格式中,操作数的字长是用 "byte ptr" 和 "word ptr" 等前缀来表示的。例如:
AT&T 格式 Intel 格式 movb val, %al mov al, byte ptr val - 在 AT&T 汇编格式中,绝对转移和调用指令(jump/call)的操作数前要加上'*'作为前缀,而在 Intel 格式中则不需要。
-
远程转移指令和远程子调用指令的操作码,在 AT&T 汇编格式中为 "ljump" 和 "lcall",而在 Intel 汇编格式中则为 "jmp far" 和 "call far",即:
AT&T 格式 Intel 格式 ljump $section, $offset jmp far section:offset lcall $section, $offset call far section:offset 与之相应的远程返回指令则为:
AT&T 格式 Intel 格式 lret $stack_adjust ret far stack_adjust -
在 AT&T 汇编格式中,内存操作数的寻址方式是
section:disp(base, index, scale)
而在 Intel 汇编格式中,内存操作数的寻址方式为:
section:[base + index*scale + disp]
由于 Linux 工作在保护模式下,用的是 32 位线性地址,所以在计算地址时不用考虑段基址和偏移量,而是采用如下的地址计算方法:
disp + base + index * scale
下面是一些内存操作数的例子:
AT&T 格式 Intel 格式 movl -4(%ebp), %eax mov eax, [ebp - 4] movl array(, %eax, 4), %eax mov eax, [eax*4 + array] movw array(%ebx, %eax, 4), %cx mov cx, [ebx + 4*eax + array] movb $4, %fs:(%eax) mov fs:eax, 4
2、寄存器
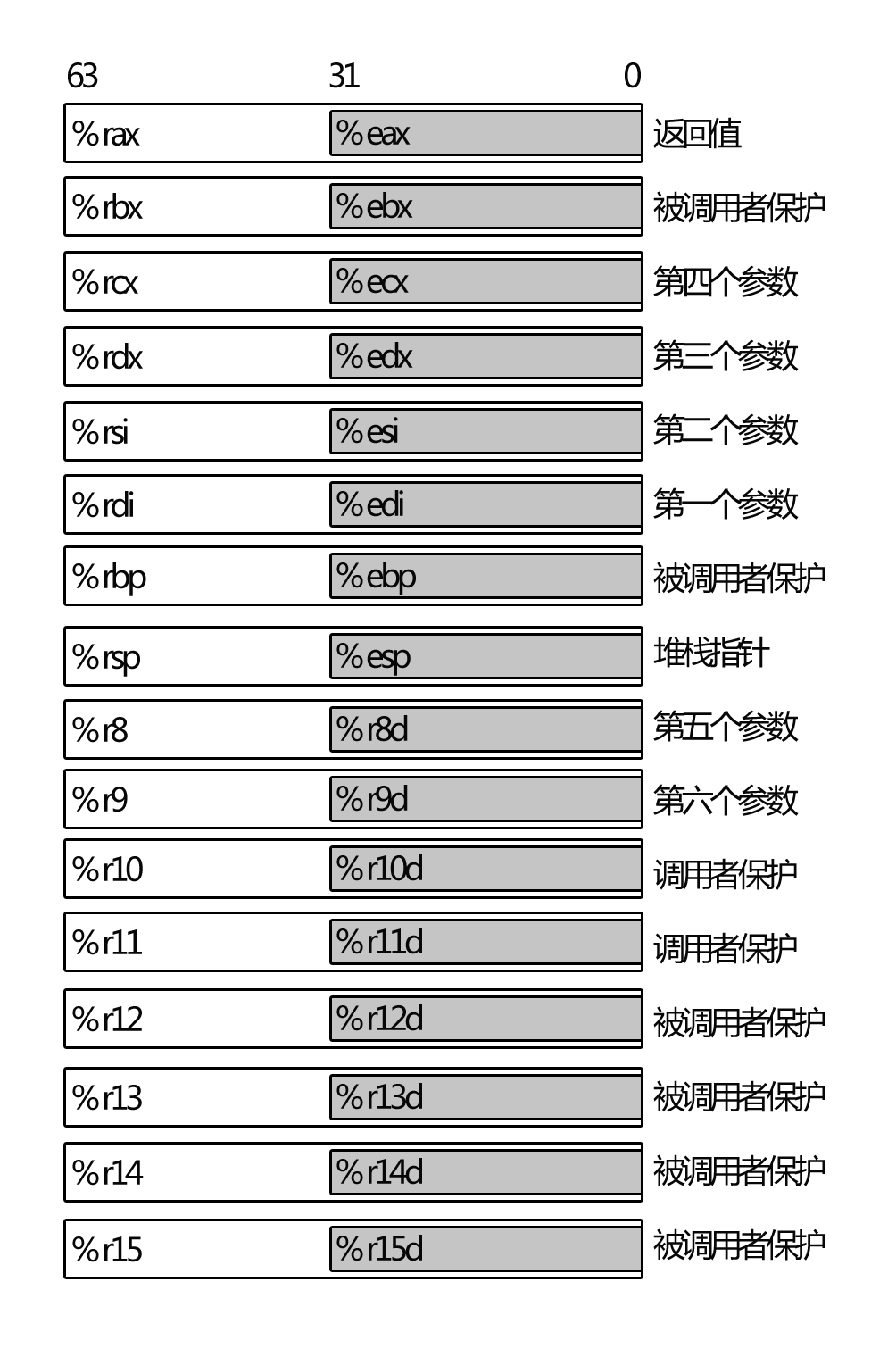
X84中原有8个32位通用寄存器%eax,%ebx,%ecx,%edx,%esi,%edi,%ebp,%esp, 在X86_64中
分别被扩展为64位,并且多了8个寄存器。因此X86_64的寄存器如下:
- rax, eax, ax, ah, al;
- rbx, ebx, bx, bh, bl;
- rcx, ecx, cx, ch, cl;
- rdx, edx, dx, dh, dl;
- rsi, esi, si;
- rdi, edi, di;
- rbp, ebp;
- rsp, esp;
- r8-r15;
GCC中对这些寄存器的调用规则如下:
- %rax 作为函数返回值使用。
- %rsp 栈指针寄存器,指向栈顶
- %rdi,%rsi,%rdx,%rcx,%r8,%r9 用作函数参数,依次对应第1参数,第2参数。。。
- %rbx,%rbp,%r12,%r13,%14,%15 用作数据存储,遵循被调用者使用规则,简单说就是随便用,调用子函数之前要备份它,以防他被修改
- %r10,%r11 用作数据存储,遵循调用者使用规则,简单说就是使用之前要先保存原值
3、栈帧
以一个简单的add函数为例:
1 #include <stdio.h> 2 3 int add(int a, int b) 4 { 5 return a + b; 6 } 7 8 int main(void) 9 { 10 int c, a = 1, b = 2; 11 12 c = add(a, b); 13 14 return c; 15 }
编译并反汇编,
1 scripts$ gcc -g test.c -o test 2 scripts$ objdump -S -d test > test.s 3 scripts$ vim test.s
1 0000000000400474 <add>: 2 #include <stdio.h> 3 4 int add(int a, int b) 5 { 6 400474: 55 push %rbp 7 400475: 48 89 e5 mov %rsp,%rbp 8 400478: 89 7d fc mov %edi,-0x4(%rbp) 9 40047b: 89 75 f8 mov %esi,-0x8(%rbp) 10 return a + b; 11 40047e: 8b 45 f8 mov -0x8(%rbp),%eax 12 400481: 8b 55 fc mov -0x4(%rbp),%edx 13 400484: 8d 04 02 lea (%rdx,%rax,1),%eax 14 } 15 400487: c9 leaveq 16 400488: c3 retq 17 18 0000000000400489 <main>: 19 20 int main(void) 21 { 22 400489: 55 push %rbp 23 40048a: 48 89 e5 mov %rsp,%rbp 24 40048d: 48 83 ec 10 sub $0x10,%rsp 25 int c, a = 1, b = 2; 26 400491: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp) 27 400498: c7 45 fc 02 00 00 00 movl $0x2,-0x4(%rbp) 28 29 c = add(a, b); 30 40049f: 8b 55 fc mov -0x4(%rbp),%edx 31 4004a2: 8b 45 f8 mov -0x8(%rbp),%eax 32 4004a5: 89 d6 mov %edx,%esi 33 4004a7: 89 c7 mov %eax,%edi 34 4004a9: e8 c6 ff ff ff callq 400474 <add> 35 4004ae: 89 45 f4 mov %eax,-0xc(%rbp) 36 37 return c; 38 4004b1: 8b 45 f4 mov -0xc(%rbp),%eax 39 }
从32、33行可知,edi<- a, esi<- b, 然后 call add,此时main函数中的栈帧结构如下(某个寄存器为x,则xH表示高4位):
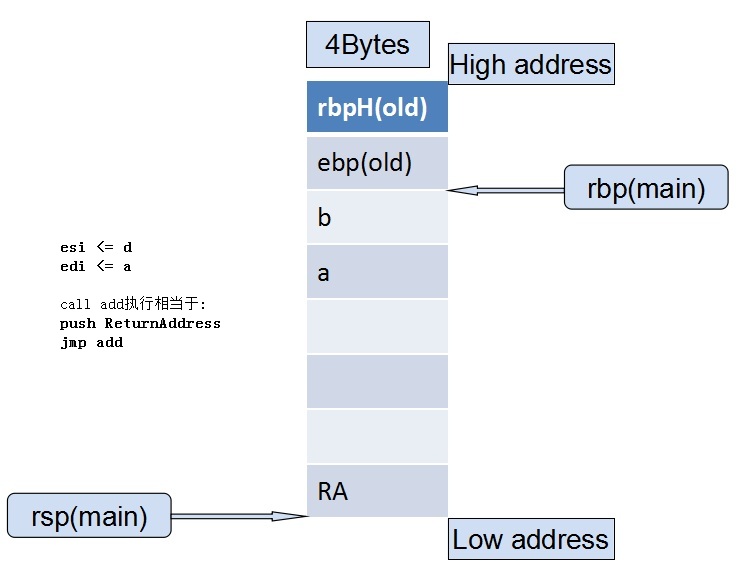
然后跳入add中执行:
从4-12行完毕,eax存储b, edx存储a, 此时整体的栈帧结构:
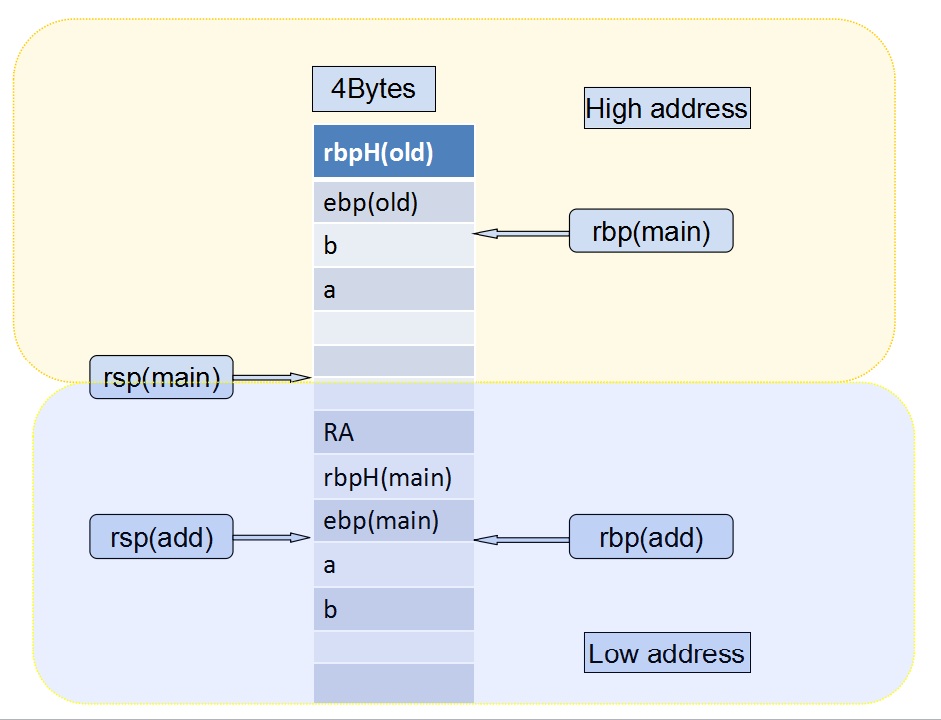
之后是指令:
lea (%rdx,%rax,1),%eax
lea是load effective address,加载有效地址,类似于C语言中的“&”取地址符的作用,本例中是将 rdx + rax * 1 ==> eax, 即 eax = a + b,
然后rax自动作为返回值。