SSTable是Bigtable中至关重要的一块,对于LevelDB来说也是如此,对LevelDB的SSTable实现细节的了解也有助于了解Bigtable中一些实现细节。
本节内容主要讲述SSTable的静态布局结构,SSTable文件形成了不同Level的层级结构,至于这个层级结构是如何形成的我们放在后面Compaction一节细说。本节主要介绍SSTable某个文件的物理布局和逻辑布局结构,这对了解LevelDB的运行过程很有帮助。
LevelDB不同层级都有一个或多个SSTable文件(以后缀.sst为特征),所有.sst文件内部布局都是一样的。上节介绍Log文件是物理分块的,SSTable也一样会将文件划分为固定大小的物理存储块Block,但是两者逻辑布局大不相同,根本原因是:Log文件中的记录是Key无序的,即先后记录的key大小没有明确大小关系,而.sst文件内部则是根据记录的Key由小到大排列的,从下面介绍的SSTable布局可以体会到Key有序是为何如此设计.sst文件结构的关键。

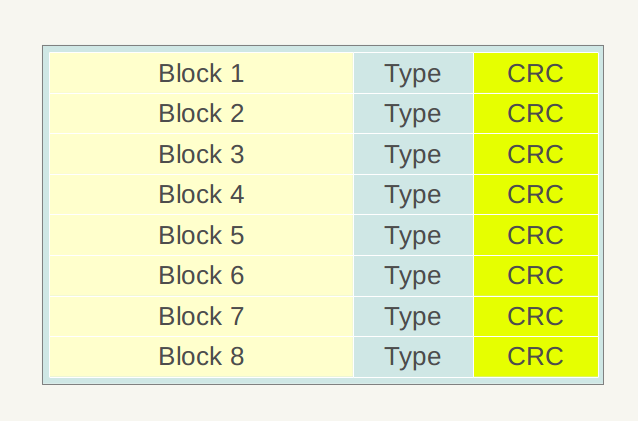
图1展示了一个.sst文件的物理划分结构,同Log文件一样,也是划分为固定大小的存储块,每个Block分为三个部分,包括Block、Type和CRC。Block为数据存储区,Type区用于标识Block中数据是否采用了数据压缩算法(Snappy压缩或者无压缩两种),CRC部分则是Block数据校验码,用于判别数据是否在生成和传输中出错。
以上是.sst的物理布局,下面介绍.sst文件的逻辑布局,所谓逻辑布局,就是说尽管大家都是物理块,但是每一块存储什么内容,内部又有什么结构等。图4.2展示了.sst文件的内部逻辑解释。
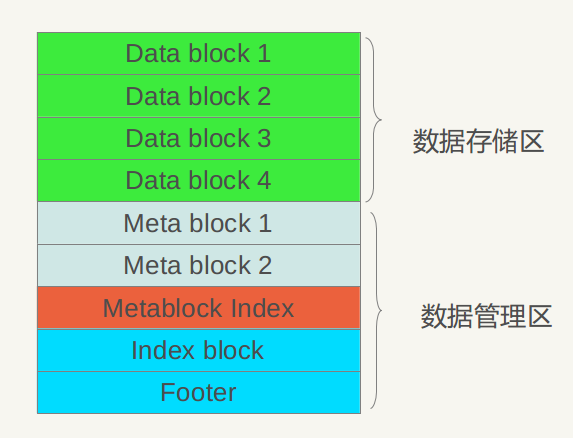
从图2可以看出,从大的方面,可以将.sst文件划分为数据存储区和数据管理区,数据存储区存放实际的Key:Value数据,数据管理区则提供一些索引指针等管理数据,目的是更快速便捷的查找相应的记录。两个区域都是在上述的分块基础上的,就是说文件的前面若干块实际存储KV数据,后面数据管理区存储管理数据。管理数据又分为四种不同类型:紫色的Meta Block,红色的MetaBlock Index和蓝色的Index block以及一个文件尾部块Footer。
LevelDB 1.2版对于Meta Block尚无实际使用,只是保留了一个接口,估计会在后续版本中加入内容,下面我们看看Index block和文件尾部Footer的内部结构。
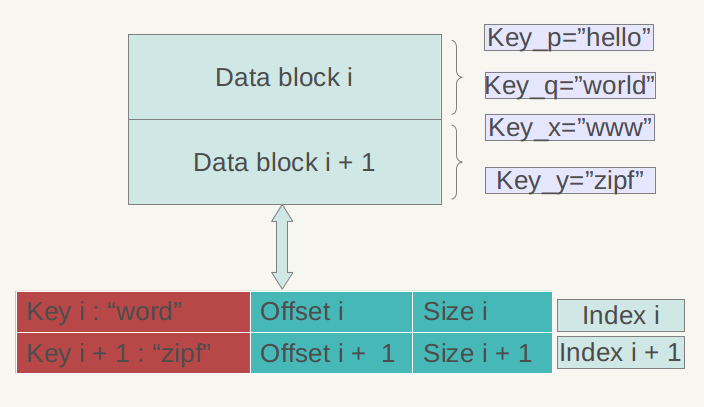
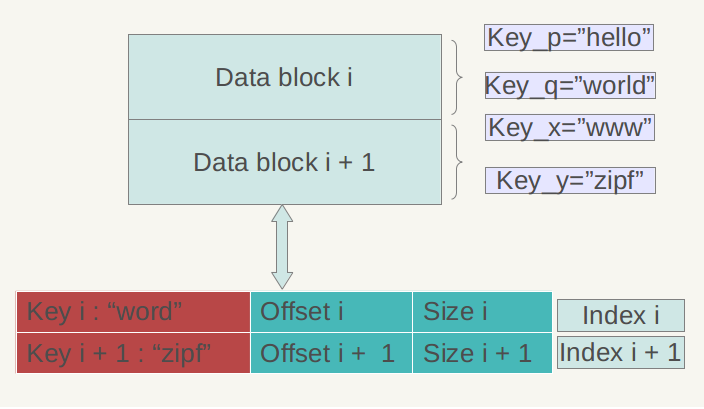
图3 Index block结构
图3是Index block的内部结构示意图。再次强调一下,Data Block内的KV记录是按照Key由小到大排列的,Index block的每条记录是对某个Data Block建立的索引信息,每条索引信息包含三个内容:Data Block中key上限值(不一定是最大key)、Data Block在.sst文件的偏移和大小,以图3所示的数据块i的索引Index i来说:红色部分的第一个字段记载大于等于数据块i中最大的Key值的那个Key,第二个字段指出数据块i在.sst文件中的起始位置,第三个字段指出Data Block i的大小(有时候是有数据压缩的)。后面两个字段好理解,是用于定位数据块在文件中的位置的,第一个字段需要详细解释一下,在索引里保存的这个Key值未必一定是某条记录的Key,以图3的例子来说,假设数据块i 的最小Key=“samecity”,最大Key=“the best”;数据块i+1的最小Key=“the fox”,最大Key=“zoo”,那么对于数据块i的索引Index i来说,其第一个字段记载大于等于数据块i的最大Key(“the best”),同时要小于数据块i+1的最小Key(“the fox”),所以例子中Index i的第一个字段是:“the c”,这个是满足要求的;而Index i+1的第一个字段则是“zoo”,即数据块i+1的最大Key。
文件末尾Footer块的内部结构见图4,metaindex_handle指出了metaindex block的起始位置和大小;inex_handle指出了index Block的起始地址和大小;这两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数(0xdb4775248b80fb57)。
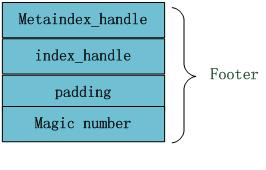
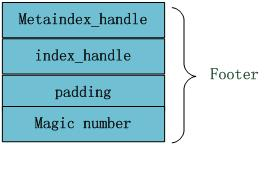
图4 Footer
上面主要介绍的是数据管理区的内部结构,下面我们看看数据区的一个Block的数据部分内部是如何布局的,图5是其内部布局示意图。

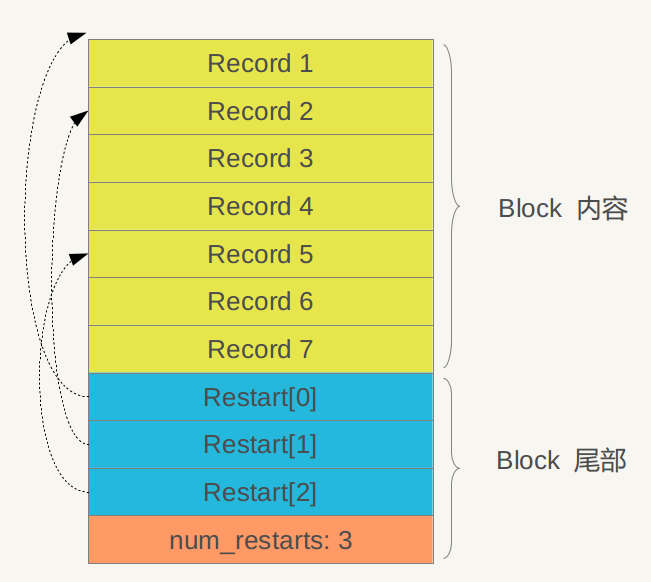
图5 Data Block内部结构
从图中可以看出,其内部也分为两个部分,前面是一个个KV记录,其顺序是根据Key值由小到大排列的,在Block尾部则是一些“重启点”(Restart Point),其实是一些指针,指出Block内容中的一些记录位置。
“重启点”是干什么的呢?简单来说就是进行数据压缩,减少存储空间。我们一再强调,Block内容里的KV记录是按照Key大小有序的,这样的话,相邻的两条记录很可能Key部分存在重叠,比如key i=“the car”,Key i+1=“the color”,那么两者存在重叠部分“the c”,为了减少Key的存储量,Key i+1可以只存储和上一条Key不同的部分“olor”,两者的共同部分从Key i中可以获得。记录的Key在Block内容部分就是这么存储的,主要目的是减少存储开销。“重启点”的意思是:在这条记录开始,不再采取只记载不同的Key部分,而是重新记录所有的Key值,假设Key i+1是一个重启点,那么Key里面会完整存储“the color”,而不是采用简略的“olor”方式。但是如果记录条数比较多,随机访问一条记录,需要从头开始一直解析才行,这样也产生很大的开销,所以设置了多个重启点,Block尾部就是指出哪些记录是这些重启点的。


图6 记录格式
在Block内容区,每个KV记录的内部结构是怎样的?图6给出了其详细结构,每个记录包含5个字段:key共享长度,key非共享长度,value长度,key非共享内容,value内容。比如上面的“the car”和“the color”记录,key共享长度5;key非共享长度是4;而key非共享内容则实际存储“olor”;value长度及内容分别指出Key:Value中Value的长度和存储实际的Value值。
上面讲的这些就是.sst文件的全部内部奥秘。
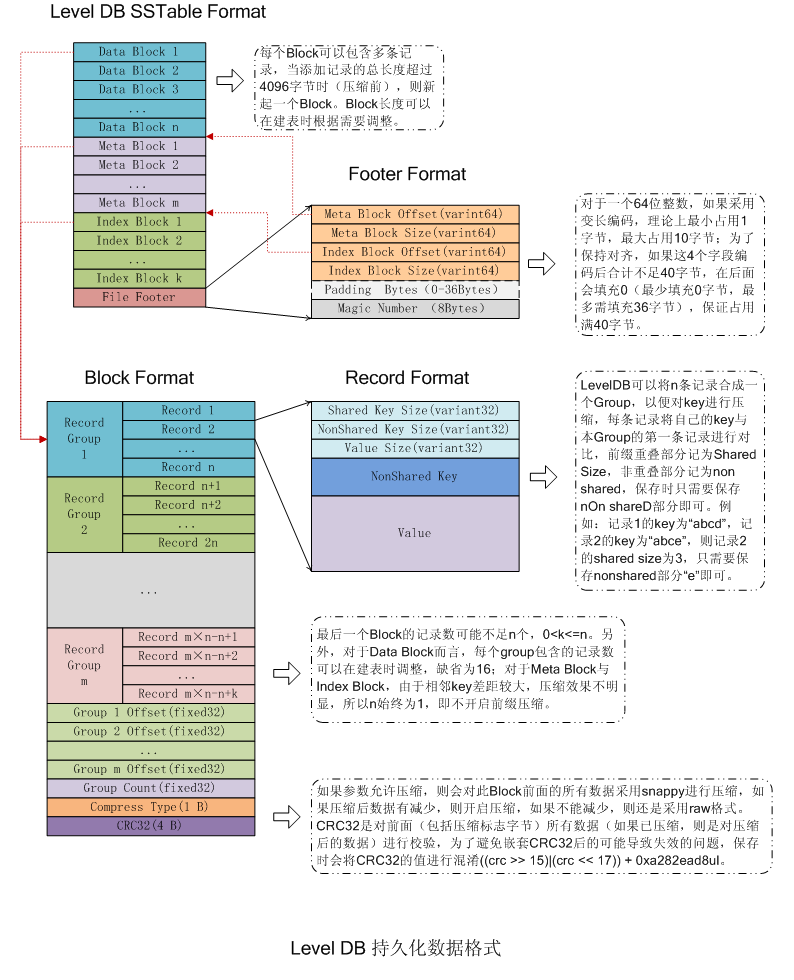
由上图可知,SSTable主要分为五部分:
1)DataBlock:存储Key-Value记录,分为Data、type、CRC三部分,其中Data部分的详细结构见 leveldb之SSTable
2)MetaBlock:暂时没有使用
3)MetaBlock_index:记录filter的相关信息(本文暂时没有考虑filter)
4)IndexBlock:描述一个DataBlock,存储着对应DataBlock的最大Key值,DataBlock在.sst文件中的偏移量和大小
5)Footer :索引的索引,记录IndexBlock和MetaIndexBlock在SSTable中的偏移量了和大小
1、TableBuilder
leveldb通过TableBuilder类来构建每一个.sst文件,TableBuilder类的成员变量只有一个结构体Rep* rep_,Rep的结构为:
1 struct TableBuilder::Rep { 2 Options options; 3 Options index_block_options; 4 WritableFile* file;//要生成的.sst文件 5 uint64_t offset; 6 Status status; 7 BlockBuilder data_block;//数据区 8 BlockBuilder index_block;//索引 9 std::string last_key;//上一个插入的key值,新插入的key必须比它大,保证.sst文件中的key是从小到大排列的 10 int64_t num_entries;//.sst文件中存储的所有记录总数 11 bool closed; 12 FilterBlockBuilder* filter_block; 13 bool pending_index_entry;//当DataBlock为空时,为true 14 BlockHandle pending_handle; //BlockHandle只有offset_和size_两个变量,用来记录DataBlock在.sst文件中的偏移量和大小 15 16 std::string compressed_output;//是否需要对DataBlock中的内容进行压缩 17 };
TableBuilder与BlockBuilder类似,通过Add()函数向文件中加入一条记录,通过Finish()来完成一个SSTable的构建。在下面的分析中,暂时不考虑filter_block
1.1 TableBuilder::Add()
通过Add()函数向一个.sst文件中加入一条记录,主要分为:写index_block,写Data_block,更新相关变量,可能完成一个DataBlock并将数据写入磁盘
1 void TableBuilder::Add(const Slice& key, const Slice& value) { 2 Rep* r = rep_; 3 if (r->num_entries > 0) { 4 assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);//待插入的key值必须比ast_key大 5 } 6 7 if (r->pending_index_entry) {//DataBlock为空时,为true 8 assert(r->data_block.empty()); 9 r->options.comparator->FindShortestSeparator(&r->last_key, key); 10 std::string handle_encoding; 11 r->pending_handle.EncodeTo(&handle_encoding);//handle_encoding记录每个DataBlock的偏移量和大小 12 r->index_block.Add(r->last_key, Slice(handle_encoding));//将DataBlock的last_key、offset和size写入到index_block 13 r->pending_index_entry = false;//变为false 14 } 15 16 r->last_key.assign(key.data(), key.size());//更新last_key 17 r->num_entries++;//更新记录总数 18 r->data_block.Add(key, value);//将key-value写入一个DataBlock 19 20 const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();//DataBlock的大小 21 if (estimated_block_size >= r->options.block_size) {//当DataBlock所占空间超过设定值(默认为4K)时 22 Flush();//完成一个DataBlock,并将DataBlock写入到磁盘.sst文件中 23 } 24 }
1.1.1TableBuilder::Flush()
当一个DataBlock超过设定值(默认为4K,1个page)时,执行Flush()操作
- void TableBuilder::Flush() {
- Rep* r = rep_;
- WriteBlock(&r->data_block, &r->pending_handle);
- if (ok()) {
- r->pending_index_entry = true;
- r->status = r->file->Flush();
- }
- }
首先调用WriteBlock()写入数据,然后对.sst文件执行fflush()将数据写入磁盘
1.1.2TableBuilder::WriteBlock()
WriteBlock()首先调用BlockBuilder::Finish()完成一个DataBlock的创建并返回数据区的内容Slice,然后判断是否需要进行压缩,最后调用WriteRawBlock()写入数据,并调用BlockBuilder::Reset()重新开始一个DataBlock
1.1.3TableBuilder::WriteRawBlock()
由之前对SSTable布局的分析可知,一个.sst文件的数据区分为三部分:DataBlock、Type和CRC
传入三个参数:block_contents为调用BlockBuilder::Finish()返回的数据区的内容,type为是否压缩,handle为DataBlock的偏移量和大小
1 void TableBuilder::WriteRawBlock(const Slice& block_contents, 2 CompressionType type, 3 BlockHandle* handle) { 4 Rep* r = rep_; 5 handle->set_offset(r->offset);//更新DataBlock在.sst文件中的偏移量和大小 6 handle->set_size(block_contents.size()); 7 r->status = r->file->Append(block_contents);//最终会调用fwrite将数据区内容写入到.sst文件中 8 if (r->status.ok()) { 9 char trailer[kBlockTrailerSize]; 10 trailer[0] = type;//第一个字节为type 11 uint32_t crc = crc32c::Value(block_contents.data(), block_contents.size()); 12 crc = crc32c::Extend(crc, trailer, 1); // Extend crc to cover block type 13 EncodeFixed32(trailer+1, crc32c::Mask(crc));//将CRC写入trailer 14 r->status = r->file->Append(Slice(trailer, kBlockTrailerSize));//将type和CRC写入.sst文件 15 if (r->status.ok()) { 16 r->offset += block_contents.size() + kBlockTrailerSize; 17 } 18 } 19 }
这样就完成了.sst文件中DataBlock的写入了
1.2TableBuilder::Finish()
调用Finish()来完成一个SSTable的创建,主要包括前面的DataBlock,还有IndexBlock、MetaIndexBlock、Footer等
1 Status TableBuilder::Finish() { 2 Rep* r = rep_; 3 Flush();//将数据区的内容全部写入到SSTable中 4 5 BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle; 6 7 // Write metaindex block 8 if (ok()) { 9 BlockBuilder meta_index_block(&r->options); 10 if (r->filter_block != NULL) {//记录filter相关信息,暂时没有考虑 11 // Add mapping from "filter.Name" to location of filter data 12 std::string key = "filter."; 13 key.append(r->options.filter_policy->Name()); 14 std::string handle_encoding; 15 filter_block_handle.EncodeTo(&handle_encoding); 16 meta_index_block.Add(key, handle_encoding); 17 } 18 WriteBlock(&meta_index_block, &metaindex_block_handle); 19 } 20 21 // Write index block 22 if (ok()) { 23 if (r->pending_index_entry) { 24 r->options.comparator->FindShortSuccessor(&r->last_key); 25 std::string handle_encoding; 26 r->pending_handle.EncodeTo(&handle_encoding); 27 r->index_block.Add(r->last_key, Slice(handle_encoding)); 28 r->pending_index_entry = false; 29 } 30 WriteBlock(&r->index_block, &index_block_handle);//将indexblock中的所有数据写入到SSTable文件中 31 } 32 33 // Write footer 34 if (ok()) { 35 Footer footer;//footer记录MetaIndexBlock和IndexBlock在SSTable文件中的偏移量和大小 36 footer.set_metaindex_handle(metaindex_block_handle); 37 footer.set_index_handle(index_block_handle); 38 std::string footer_encoding; 39 footer.EncodeTo(&footer_encoding); 40 r->status = r->file->Append(footer_encoding);//将footer写入到SSTable中 41 if (r->status.ok()) { 42 r->offset += footer_encoding.size(); 43 } 44 } 45 return r->status; 46 }
file->Append()最终都会调用到fwrite(),将数据写入到磁盘中。
这样就将数据区和数据管理区的所有内容都写入到磁盘中的.sst文件中了
2、Table
Table类用来描述一个SSTable文件,Table类中也只有一个成员变量Rep *rep_,其结构为:
- struct Table::Rep {
- Options options;
- Status status;
- RandomAccessFile* file;//.sst文件
- uint64_t cache_id;
- FilterBlockReader* filter;
- const char* filter_data;
- BlockHandle metaindex_handle; // Handle to metaindex_block: saved from footer
- Block* index_block;
- };
其内容主要包括通过SSTable文件中的Footer获得的IndexBlock和MetaIndexBlock(暂时不考虑filter)
2.1Table::Open()
通过Open一个.sst文件将其转换为Table结构,由下面的代码可知SSTable中的Footer是长度固定的,为2*BlockHandle::kMaxEncodedLength + 8,共28字节
- void Footer::EncodeTo(std::string* dst) const {
- metaindex_handle_.EncodeTo(dst);
- index_handle_.EncodeTo(dst);
- dst->resize(2 * BlockHandle::kMaxEncodedLength); // Padding
- PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber & 0xffffffffu));
- PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber >> 32));
- }
因此可直接从一个SSTable中找到Footer结构体,而Footer是索引的索引,其中存储着IndexBlock和MetaIndexBlock的信息,因此可以很方便的获取IndexBlock。
2.2Table::InternalGet()
可通过InternalGet()来查找对应的记录
1、首先在IndexBlock中找到目标key所在的DataBlock在SSTable文件中的偏移量和大小
2、然后根据找到的IndexBlock中的key,offset,size找到对应的DataBlock
3、DataBlock包含实际数据区、type和CRC,调用Table::ReadBlock()来从中找到实际的数据区
4、然后在数据区中对目标key进行查找
3、TableCache
前面讲过对于levelDb来说,读取操作如果没有在内存的memtable中找到记录,要多次进行磁盘访问操作。假设最优情况,即第一次就在level 0中最新的文件中找到了这个key,那么也需要读取2次磁盘,一次是将SSTable的文件中的index部分读入内存,这样根据这个index可以确定key是在哪个block中存储;第二次是读入这个block的内容,然后在内存中查找key对应的value。
LevelDb中引入了两个不同的Cache:Table Cache和Block Cache。其中Block Cache是配置可选的,即在配置文件中指定是否打开这个功能。
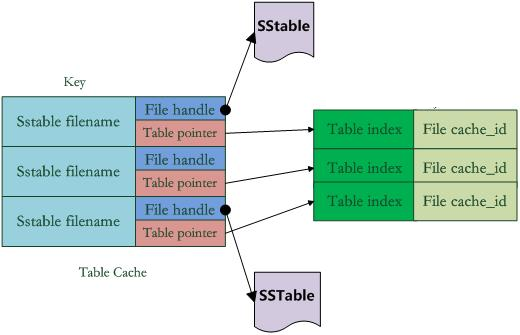
如上图,在Table Cache中,key值是SSTable的文件名称,Value部分包含两部分,一个是指向磁盘打开的SSTable文件的文件指针,这是为了方便读取内容;另外一个是指向内存中这个SSTable文件对应的Table结构指针,table结构在内存中,保存了SSTable的index内容以及用来指示block cache用的cache_id ,当然除此外还有其它一些内容。
比如在get(key)读取操作中,如果levelDb确定了key在某个level下某个文件A的key range范围内,那么需要判断是不是文件A真的包含这个KV。此时,levelDb会首先查找Table Cache,看这个文件是否在缓存里,如果找到了,那么根据index部分就可以查找是哪个block包含这个key。如果没有在缓存中找到文件,那么打开SSTable文件,将其index部分读入内存,然后插入Cache里面,去index里面定位哪个block包含这个Key 。如果确定了文件哪个block包含这个key,那么需要读入block内容,这是第二次读取。
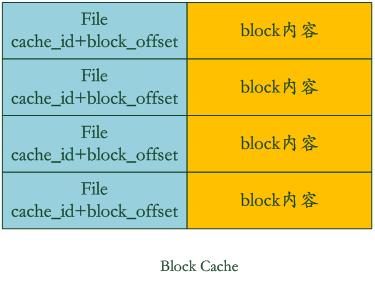
Block Cache是为了加快这个过程的,其中的key是文件的cache_id加上这个block在文件中的起始位置block_offset。而value则是这个Block的内容。
如果levelDb发现这个block在block cache中,那么可以避免读取数据,直接在cache里的block内容里面查找key的value就行,如果没找到呢?那么读入block内容并把它插入block cache中。levelDb就是这样通过两个cache来加快读取速度的。从这里可以看出,如果读取的数据局部性比较好,也就是说要读的数据大部分在cache里面都能读到,那么读取效率应该还是很高的,而如果是对key进行顺序读取效率也应该不错,因为一次读入后可以多次被复用。但是如果是随机读取,您可以推断下其效率如何。
由之前对Cache的分析:leveldb之cache 可知,内存访问效率比磁盘访问效率要高得多,因此leveldb将通过Cache在内存中缓存最近使用到的一些文件,以提高访问效率。.sst文件主要对应的是TableCache,通过TableCache将最近使用到的.sst文件缓存在内存中,类Table通过成员变量cache_来管理缓存文件,cache_的成员变量key对应的则是每个SSTable的文件名。
3.1TableCache::Get()
通过Get()进行查找相应记录
1 Status TableCache::Get(const ReadOptions& options, 2 uint64_t file_number, 3 uint64_t file_size, 4 const Slice& k, 5 void* arg, 6 void (*saver)(void*, const Slice&, const Slice&)) { 7 Cache::Handle* handle = NULL; 8 Status s = FindTable(file_number, file_size, &handle);//查找.sst文件 9 if (s.ok()) { 10 Table* t = reinterpret_cast<TableAndFile*>(cache_->Value(handle))->table; 11 s = t->InternalGet(options, k, arg, saver);//在目标.sst文件中查找目标记录 12 cache_->Release(handle); 13 } 14 return s; 15 }
在查找时,首先调用FindTable()来查找目标记录所在的.sst文件,然后在.sst文件中调用InternalGet()查找目标记录(见上面的2.2),这样就完成了查找操作,并将.sst文件与缓存cache联系起来了。
3.2TableCache::FindTable()
1 Status TableCache::FindTable(uint64_t file_number, uint64_t file_size, 2 Cache::Handle** handle) { 3 Status s; 4 char buf[sizeof(file_number)]; 5 EncodeFixed64(buf, file_number); 6 Slice key(buf, sizeof(buf));//.sst文件名 7 *handle = cache_->Lookup(key);//首先在现有的缓存中进行查找,具体实现见<a target=_blank href="http://blog.csdn.net/u012658346/article/details/45486051">leveldb之cache</a> 8 if (*handle == NULL) {//如果文件不存在于缓存中 9 std::string fname = TableFileName(dbname_, file_number); 10 RandomAccessFile* file = NULL; 11 Table* table = NULL; 12 s = env_->NewRandomAccessFile(fname, &file);//打开一个.sst文件 13 if (!s.ok()) { 14 std::string old_fname = SSTTableFileName(dbname_, file_number); 15 if (env_->NewRandomAccessFile(old_fname, &file).ok()) { 16 s = Status::OK(); 17 } 18 } 19 if (s.ok()) { 20 s = Table::Open(*options_, file, file_size, &table);//然后将.sst文件转换为Table 21 } 22 23 if (!s.ok()) { 24 assert(table == NULL); 25 delete file; 26 } else { 27 TableAndFile* tf = new TableAndFile; 28 tf->file = file; 29 tf->table = table; 30 *handle = cache_->Insert(key, tf, 1, &DeleteEntry);//如果此文件不在cache_中,则将其加入到缓存中 31 } 32 } 33 return s; 34 }
4、总结
1.类TableBuilder用来写入一个.sst文件:通过Add()向文件中加入一条记录,通过Finish()完成一个.sst文件的创建和写入
2.类Table利用成员变量index_block来描述一个.sst文件,通过Open()从一个.sst文件中获取index_block的内容,通过InternalGet()在一个.sst文件中查找目标记录
3.类TableCache通过成员变量cache_来将最近使用的.sst文件存放在内存中进行管理(LRU思想)。
4.SSTable的查找:
leveldb在查找一条记录时,首先是在Memtable中查找,当在Memtable中没有找到时,才在SSTable中查找。SSTable是存放在磁盘中的,而访问磁盘速度非常慢,因此leveldb将最近使用的SSTable文件缓存在内存中,以提高访问效率,这是通过TableCache实现的。
在SSTable中查找时,具体的步骤为:
1)通过cache->Lookup()在缓存中查找目标所在的.sst文件,当其不在缓存中时,在内存中创建一个.sst文件并调用cache->Insert()将其加入到缓存中。
2)在找到的.sst文件中调用InternalGet(),首先在index_block中进行查找,找到对应的DataBlock在.sst文件中的偏移和大小。由于DataBlock是由Block、type(是否压缩)和CRC三部分组成的,因此需要调用ReadBlock()获取真正的数据区。
3)然后调用block_iter->Seek(k)在数据区中进行查找,由于数据区包含多个重启点,因此首先是在重启点中进行二分查找,找到目标对应的重启点。然后从重启点开始找到重启点对应的一部分记录,并在其中查找目标key值。
这样就完成了在SSTable中的完整查找操作。