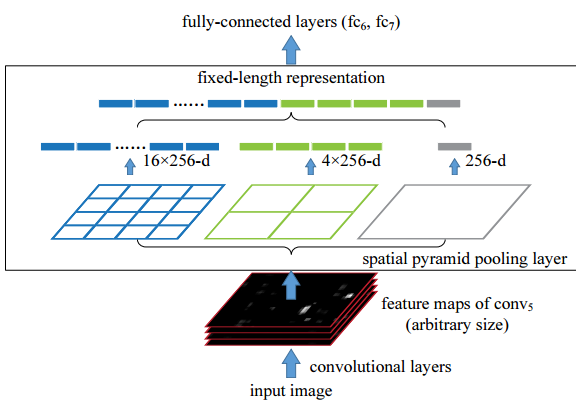
fast rcnn: 任意大小的图片输入,经过特征提取层提取特征,特征提取层来自主流分类网络(只能使用到最后一层卷基层)。由selective search等算法生成2000多个region proposal,在特征提取层最后一层进行roi pooling。生成的region proposal是原图的坐标大小,需要映射到特征层,因为原图到最后一个特征层缩小到了原图的1/16,所以将region proposal的坐标乘以1/16就变成了这个region proposal在最后一层特征层的映射坐标。映射到最后一层卷积层后,要经过一个max pooling,这个max pooling是一个简化版的空间金子塔池化。sppnet中的空间金字塔池化是多尺度池化,fast rcnn只使用了一个尺度池化。具体到池化过程,region proposal映射到最后一层特征层是一个矩形区域,将这个映射的矩形区域均分成大小相等的HxW个小矩形,然后在每个小矩形里进行max pooling提取特征。具体到如何分成HxW个小矩形,比如最后一层feature map的大小是60x40,你想分成6x4 = 24个,那每个小矩形的宽度是60/6 = 10,高度是40/4 = 10,之后再按照坐标进行相应计算就好了。 最后HxW个数值进行concatenate成一个特征向量。注意:因为pooling是在每一维的feature map上进行的pooling,所以如果最后一层feature map是256维的,那进行处理后还是生成256维的特征向量,形状就变成了(1,HxW,256)。下图是sppnet中空间金字塔的过程。
经过roi pooling后,类似于vgg16,接两个全连接层,这两个全连接层都是4096维的。在最后一个全连接层再分别接两个全连接层cls_score和bbox_pred,cls_score的维度是1x种类数,是每个种类的得分,bbox_pred的维度是4x种类数,4代表框的4个变换坐标,即bounding box regression精修。最后再进行loss计算
fast rcnn中的bounding box regression理解:
首先要明确的是,fast rcnn网络本身是不产生框坐标的。如果不适用bounding box regression,训练阶段的网络结构是这样的:

如果采用bounding box regression,训练阶段网络结构是这样:
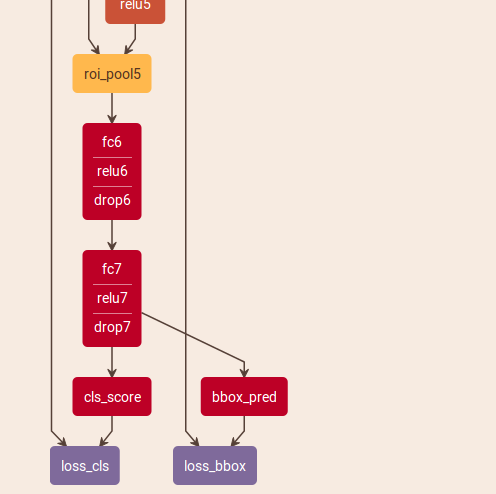
可以看到,采用了bounding box regression后,增加了一个bbox_pred层和loss_bbox层。bbox_pred层是一个全连接层,从fc7来,shape是(1,4x种类数)。loss_bbox层(也就是smoothL1)的输入除了bbox_pred外,还有从data层来的bbox_targets,这个就是训练数据的gt框。bbox_pred是由特征层训练得来的,之前一直以为生成的是框的4个坐标(即训练得到最后框的坐标再与gt框进行smoothL1的loss计算),但实际上,bbox_pred是4个变换,即bounding box regression的4个微调。观察不采用bounding box regression的网络结构图,会发现不采用的时候没有bbox_pred,如果bbox_pred表示的是框的4个坐标,那岂不是不使用bounding box regression就不生成框了,这样就不能跑这个模型了,但实际上不使用bounding box regression依旧可以跑模型,所以他代表的是4个变换,即对框坐标的微调。实际上,无论是否使用bounding box regression,最终的框坐标都来自于selective search生成的region proposal,网络的任务是识别这些框是否是某一类东西,如果是某一类东西,那这个框就作为最后检测出结果的框。bounding box regression
只不过是对所有这些框的位置进行精修罢了。即使不使用bounding box regression,也可以检测出目标,只不过准确率会低一点。并且cls_score和bbox_pred都由同一层全连接而来,即输入都是特征层,这充分体现了bounding box regression中由特征来学习这4个变换的思想。
讲一下test过程的流程就明白了:将图片和region proposal输入以训练好的网络得到所有region proposal的cls_score和bbox_pred,利用bbox_pred对所有的region proposal坐标进行精修得到新的region proposal,过滤掉所有cls_score小于阈值的框,对剩下的框进行nms处理,最后就得到最终结果。如果没有bounding box regression,就直接使用原始的selective search给的region proposal坐标,然后进行阈值过滤,nms处理,剩下的也就是最后的结果。
为什么要这么做?

以上图为例,绿色为gt框,红色是selective search生成的框,这个框识别出来是飞机,得分大于阈值,并且经过nms处理后依然存在。但在计算ap值时,这个框跟gt框的iou<0.5,会被认为识别错误(没有bounding box regression,最后保留下来的框都是selective search原始生成的,并不能进行改变。也就是说,最后模型选出来的框的坐标一定是selective search生成的2000多个中的某一个坐标或者某几个) 。如果使用了bounding box regression,可能把这个框微调成和gt框iou>0.5,这样就是正确识别。
loss计算未清理
自己看smoothL1的cuda代码可以写进来
自己把权重调高之后反而ap值降低,原因何在
如果改变7x7对整个模型是否有影响,实际代码中用的是6x6的
1.为什么vgg16最后一层缩小1/16?
vgg16中所有的卷积层都是kenel大小(卷积核大小)为3x3,pad大小为1,stride为1的卷积层。用公式W‘ = (W − F + 2P )/S+1(W代表未经过卷积的feature map大小,F代表卷积核的大小,P代表pad大小,S代表stride大小)计算可以发现,feature map的大小经过卷积后保持不变。vgg16中的卷积层分为5个阶段,每个阶段后都接一个kenel大小为2x2,stride大小为2x2的max pooling,经过一个max pooling后feature map的大小就缩小1/2,经过5次后就缩小1/32。fast rcnn中使用的vgg16只使用第5个max pooling之前的所有层,所以图像大小只缩小1/16。
2.遇到的bug:selective search生成的坐标是(y1,x1,y2,x2),但fast rcnn中的框计算全是(x1,y1,x2,y2)。
3.roi pooling跟faster rcnn的rpn是有区别的,一个是除以16,一个是乘以16。因为一个是从原图映射到特征层,另一个是从特征层映射到原图。
faster rcnn: faster rcnn改进的地方主要是引入rpn网络来生成region proposal(开创了利用卷积网络、特征层来生成region proposal,做到了share computation,提高了运行效率),代替了之前使用的selective search,实现了真正的端到端处理(fast rcnn有selective search单独生成region proposal的过程,不算真正意义上的端到端)。faster rcnn分成rpn网络和fast rcnn网络,fast rcnn网络和之前讲的一样,只是region proposal部分不来自selective search,而来自rpn网络(实际上就是一个rpn网络结合在fast rcnn网络上)。rpn网络和fast rcnn网络共用特征提取层,体现了share computation的思想。单独来看rpn网络,无论特征提取层用什么网络,都是在特征提取层最后一层卷积后面先添加一个kenel大小为3x3,stride为1,pad为1的卷积层,经过卷积后,feature map大小与特征层最后一层的feature map保持不变。之后再分别接一个属于rpn_cls_score的卷积,和一个属于rpn_bbox_pred的卷积。这两个卷积都是1x1的卷积,不同的是,rpn_cls_score的维度为2x种类数,rpn_bbox_pred的维度为4x种类数(可以看到这里利用了1x1卷积的降维功能)。实际上rpn_cls_score就是某一类的框为前景、背景的预测概率值,rpn_bbox_pred就是每一类的框的预测坐标值。值得注意的是:这里无论是score还是bbox坐标,都是直接从上一层卷积再卷积而来的,也就是从特征映射而来的,这也体现了从特征做判断的思想,在整个模式识别领域,实质上都是通过特征去判断去识别。更值得注意的是:这里映射得到的bbox坐标并不是直接的框的四个坐标值,而是四个变化值,即bounding box regression,所以,rpn网络训练学习的并不是直接的四个坐标值,而是4个变化值,这4个变换值,也就是rpn_bbox_pred,会输出到smoothL1。这与fast rcnn网络中使用bounding box regression很类似。不同的是,在fast rcnn网络中,smoothL1计算的是4个变化值和gt框的loss,但在rpn网络smoothL1计算的是4个变换值和4个变换值的loss。第一个4个变换值是从网络特征层提取的,第二个4个变换值是anchor和gt框的之间的变换值。第二个4个变换值是由rpn-data层来实现的(代码是rpn.anchor_target_layer)。rpn-data层输出的是gt框和anchor之间的4个变换值,也就是如何让anchor更加接近gt框,loss计算的就是这两个变换值的loss。在下一个小阶段,直接由anchors根据网络训练的4个变换值在生成最终的anchor坐标,这样也就接近原始数据中的gt框。rpn网络训练过程中,要筛选出256个anchor作为loss计算,正例128个,负例128个。有两种anchor为正例:1.anchor是所有anchor中与某一个gt的iou最大 2.anchor只要和一个gt的iou大于0.7。只有一种anchor为负例:与所有的gt的iou都小于0.3。注意:虽然两种情况都是positive,但anchor和gt计算4个变换时计算的是anchor和与这个anchor有最大iou的gt框的的4个变换。(具体过程可以看我写的anchor_target_layer层解读)。
训练好rpn网络后,需要生成fast rcnn所需要的region proposal,rpn_test.pt来完成此功能。rpn_test.pt的网络如下图:
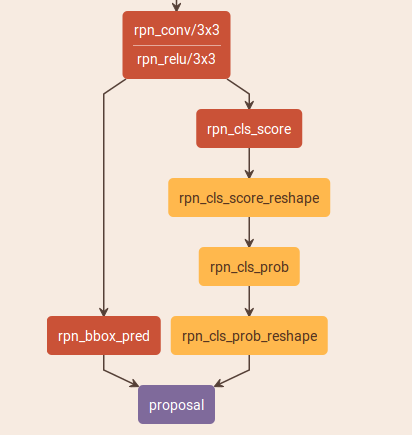
这个网络中所有的参数都是前一小阶训练的rpn网络得到的,与rpn网络不同的是不进行loss计算,直接根据rpn_bbox_pred、rpn_cls_score生成region proposal的坐标。rpn_bbox_pred不是真正的region proposal的坐标,而只是4个坐标变换值,这4个坐标变换值用来精修anchor坐标。这一部分是由proposal层来实现的(代码是rpn.proposal_layer),实际上就是把rpn滑动得到的anchor进行4个坐标变换,得到的新的框坐标,然后再经过一系列筛选(在我的proposal_layer.py层解读中详细记录了经过了怎样的筛选,可以筛选出300个proposals)就是最后fast rcnn网络中用到的region proposal。
产生anchor的代码部分(anchor_target_layer层有,proposal_layer层也有):
# 1. Generate proposals from bbox deltas and shifted anchors shift_x = np.arange(0, width) * self._feat_stride shift_y = np.arange(0, height) * self._feat_stride shift_x, shift_y = np.meshgrid(shift_x, shift_y) shifts = np.vstack((shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel())).transpose() # add A anchors (1, A, 4) to # cell K shifts (K, 1, 4) to get # shift anchors (K, A, 4) # reshape to (K*A, 4) shifted anchors A = self._num_anchors K = shifts.shape[0] all_anchors = (self._anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2))) all_anchors = all_anchors.reshape((K * A, 4)) total_anchors = int(K * A)
anchor的获得过程:先获得所有anchor可能的中心坐标点,然后产生多尺度多比例的以中心点的x1,y1,x2,y2坐标变换,最后就获得所有的anchor坐标。在卷积层最后一层,比如大小是60x38,提取这一层所有正整数坐标点(比如从0到60,从0到38),然后每个数乘以16,这样就把每个卷积层的坐标点映射到了原图中的坐标点,映射之后这些点就变成每个anchor的中心坐标点,一共有60x38个。然后利用generate_anchors函数产生9个中心点的坐标变换,这9个坐标变换是分别是平移中心点多少后就能生成x1,y1,x2,y2,将中心点坐标和变换相加就生成了所有的anchor坐标。generate_anchors函数有3个scale和3个ratio,ratio有1:2,1:1,2:1,在同一scale下,ratio就是3种长宽比,这些长宽比前提是这三种长宽比的面积相等。
fast rcnn整个训练过程分成了4步,2个大阶段,每个大阶段有3个小阶段。第一个大阶段:1.训练rpn网络。用imagenet的训练模型进行特征层参数的初始化,后面的层用高斯初始化。 2.用训练好的rpn网络得到region proposal。 3.训练fast rcnn网络。用imagenet的训练模型进行特征层参数的初始化,用rpn网络生成的region proposal进行训练。 第二个大阶段:1.训练rpn网络。特征层参数来自第一阶段fast rcnn训练得到的参数,并固定特征层参数。只finetune后面几层的参数。 2.用训练好的rpn网络得到region proposal。 3.训练fast rcnn网络。特征层参数依旧是上一阶段fast rcnn网络训练得到的参数,且参数保持不变。这时的region proposal来自这一阶段rpn网络训练得到的。只finetune后面几层的参数。
rpn网络添加卷积这个,可以去看一下paper,上面讲解了为什么要这么添加
region proposal越少,质量越高对最后ap值的提升越好,有效降低召回率,这个论文中的analysis of recall to iou部分有讲解
R-FCN: rfcn是一个全卷积的网络,almost computation shared on the entire image,提出了position-sensitive score map解决图像分类的转移不变性和目标检测的转移变性。之前的基于region proposal的目标检测都可以以roi-pooling为界分为两个子网络:全卷积网络和roi-wise网络。如果直接使用全卷积网络来实现目标检测,会得到较高的分类准确率,但同时检测的准确率也十分低。resnet基于faster做目标检测,把roi-pooling加在90层,rpn网络也是在90层进行,与faster不同的是,resnet在后面部分不使用全连接层,而是使用剩下的20层,把resnet最后一层全连接改成2个sibling layers。加入roi-pooling后,引入了平移变性,但roi-pooling后面的层不再具有平移不变性,并且训练和测试效率不高。
转移变性:在一个候选框内,转移一个目标应该产生描述这个框包含这个目标有多好的相应(translation of an object inside a candidate box should produce meaningful responses for describing how good the candidate box overlaps the object)。position-sensitive score map的结构就能很好响应。
resnet101做目标检测只把前90层提取特征了,rfcn直接把所有层拿来提取特征,因为越深的网络转移不变性越好,这样提高转移不变性(即提高分类准确率),但同时降低了转移变性,这时就添加了position-sensitive score map来提高转移变性,并且position-sensitive score map后面直接pooling、vote、加loss,后面就没有要学习的参数了,充分shared computation。
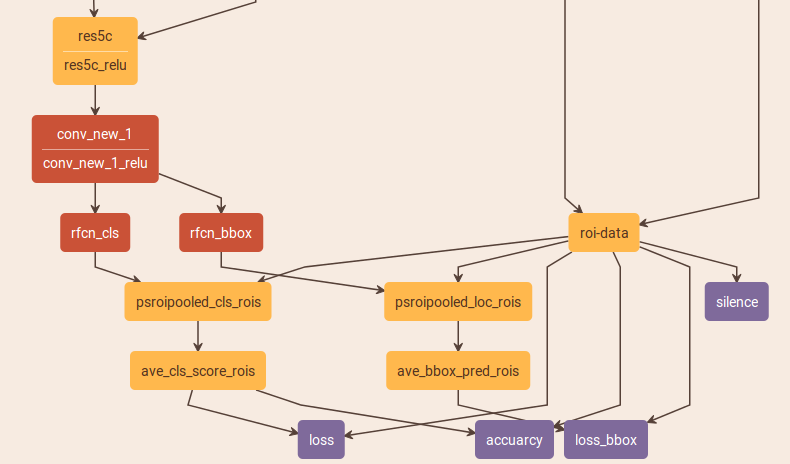
rfcn结构分为rpn网络和rfcn网络,rpn网络和faster一样,只是要注意是在90层进行的(其实完全可以在101层用rpn,因为101层都是特征提取层,只是90层是16分之一,方便计算)。剩下的rfcn网络就是在resnet最后一层卷积后面添加了position-sensitive score map、vote、loss。rfcn网络:特征提取层最后一层之后接一个1x1的卷积生成conv_new_1层,这一层之后再分别接两个1x1的卷积分别生成rfcn_cls和rfcn_bbox层,两层的shape分别是(类别*7*7,w,h)和(2*4*7*7,w,h)。实际上这两个就是position-sensitive score map,只不过rfcn_bbox层是针对4个坐标变换的(注意:rfcn_bbox层学习的也是变换,也是bounding box regression,这一点与fast、faster一样都是从特征学4个坐标变换)。两个再分别接psroipooled_cls_rois和psroipooled_loc_rois,这两层都使用的是PSROIPooling。关于PSROIPooling,以psroipooled_cls_rois
为例:现将roi的原始坐标映射到position-sensitive score map的坐标上(实际上就是4个坐标分别乘以1/16),将这个映射的区域平均分成7x7个(这里和roi pooling一样),每一个称为一个bin,每一个bin的shape是(7x7x类别数,w'/7,h'/7)。如果这个bin是第一个(最左最上的位置),那就找到这一部分的feature map(长度为类别数),然后对bin这一块区域进行average pooling,得到一个1x类别数的向量。最后得到的就是一个depth为类别数,7x7个数。
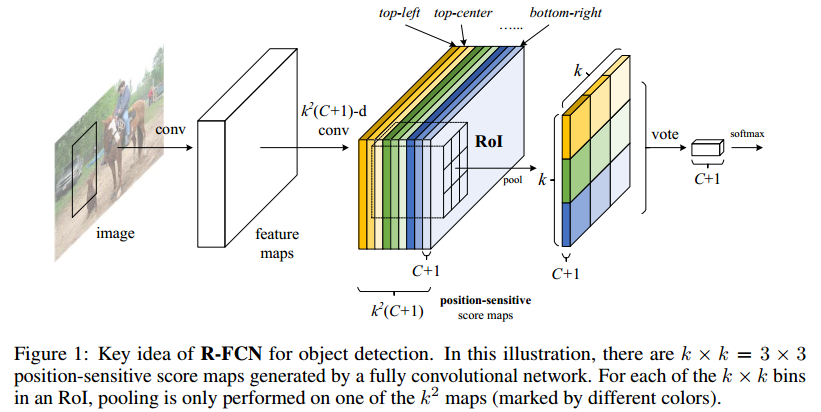
经过PSROIPooling后,再分别接ave_cls_score_rois和ave_bbox_pred_rois层,这两层都是普通的average池化层,这两层其实就是论文中所说vote部分。两层使用的都是7x7的average pooling,因为无论对于psroipooled_cls_rois还是psroipooled_loc_rois的输出,输出的shape分别是(类别数,7,7)和(2*4,7,7),经过池化后,变成了(类别数,1)和(2*4,1)。对于ave_cls_score_rois,求的就是每个类别的概率值,并且是这7x7个不同位置的bin平均得到的概率值。对于ave_bbox_pred_rois,求的是分别为前景和背景情况下的4个变换值,并且也是来自7x7个不同位置bin平均得到的值。最后再输出给分类的loss和bbox的loss。
看一下pspooling的cuda代码
bbox为什么要是前景和背景两种
面试问题:
1.给你一个深度模型,你会去调哪些参数
2.你都知道有哪些loss 函数
3.除了sgd还有哪些
4.如何解决目标检测中的前后遮挡问题
5.如何解决远近程度造成的尺寸不一样的情况
6.你有没有想过把roi Pooling在之前层进行,而不是在特征提取层最后一层
7.git你都使用了哪些指令
总结一点:工程能力特别重要,给你一个东西,你要自己去调试跑通,特别是一个c++工程如何去调试
bouding box regression的详细讲解:http://m.blog.csdn.net/zijin0802034/article/details/77685438