从训练一开始就loss为0:
最开始以为是在生成train.lmdb前没有对label_map进行修改,发现并不是这个问题
1.训练的命令是:python ./examples/ssd/ssd_pascal.py
运行ssd_pascal.py后,会在ssd/caffe/下生成jobs文件夹,并在子目录下生成以下文件:

ssd_pascal.py主要作用就是这些用来训练的文件,真正运行训练的是最后几段代码:
这段代码实际运行的就是VGG_VOC2007_SSD_300x300.sh:
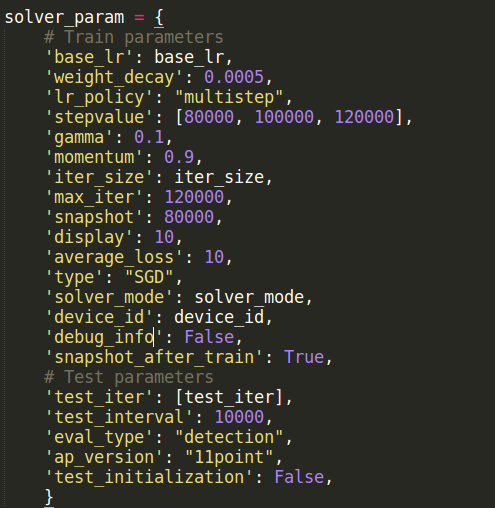
我先把~/ssd/caffe/examples/ssd/ssd_pascal.py里的solver_param的bug_info置为true进行调试:
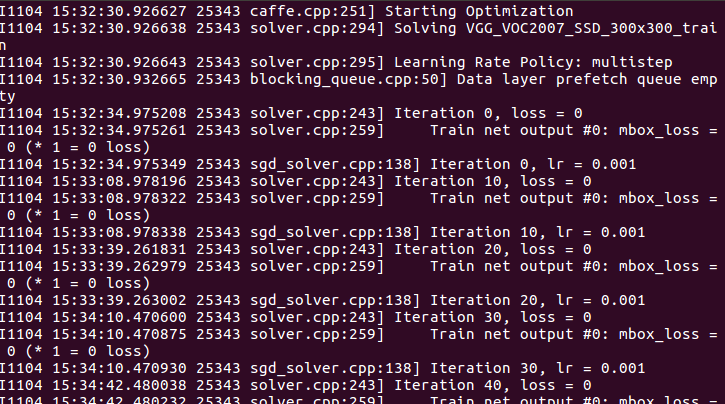
调试的结果如下图:
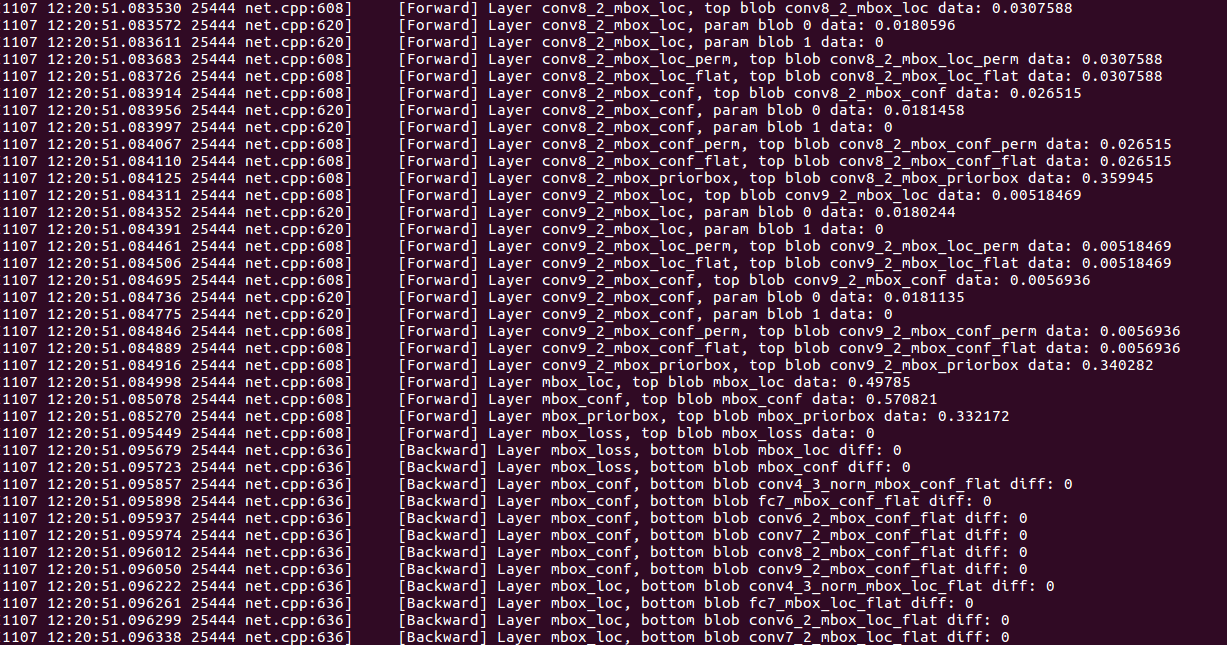
可以看到最后一个forward(mbox_loss层)为0,这个就是训练网络最终的loss输出。如下图,mbox_loss层的输入为:
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"

可以看到mbox_loc,mbox_conf,mbox_priorbox层都有输入,好像label也是有输入的

这个时候就要去调试mbox_loss层看到底是什么造成了输出loss为0。
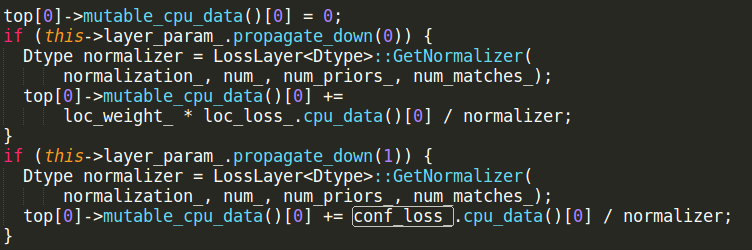
mbox_loss层的输出如下图,这两个if语句都要执行,loc_loss_为0,所以输出为0:
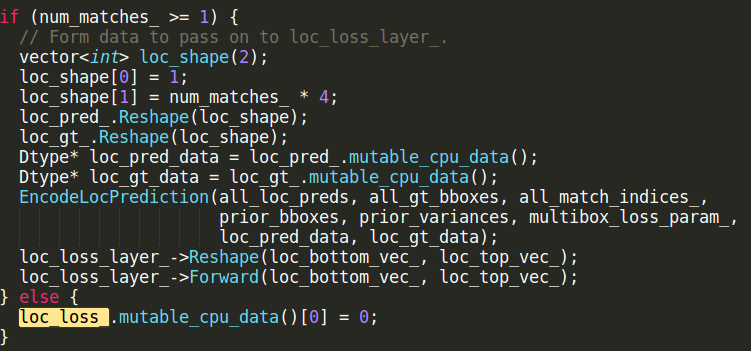
定位loc_loss_代码如下图,num_matches为0,所以loc_loss_也为0
定位num_matches代码如下图
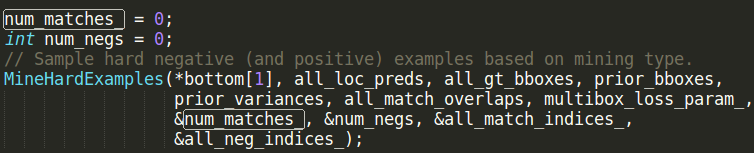
MineHardExamples函数在bbox_util.cpp定义实现,num_matches由CountNumMatches函数来得到
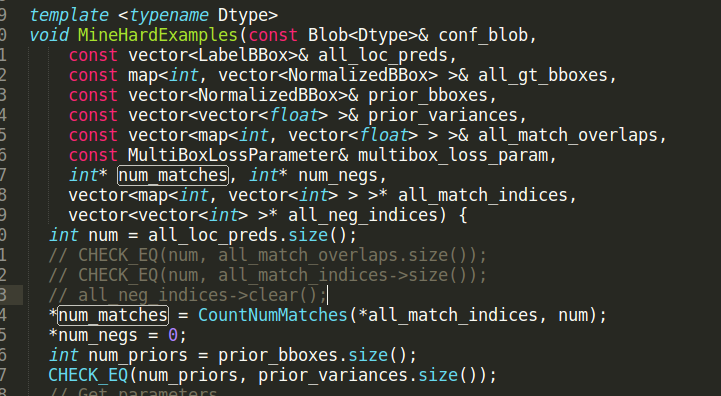
下面是CountNumMatches的代码:
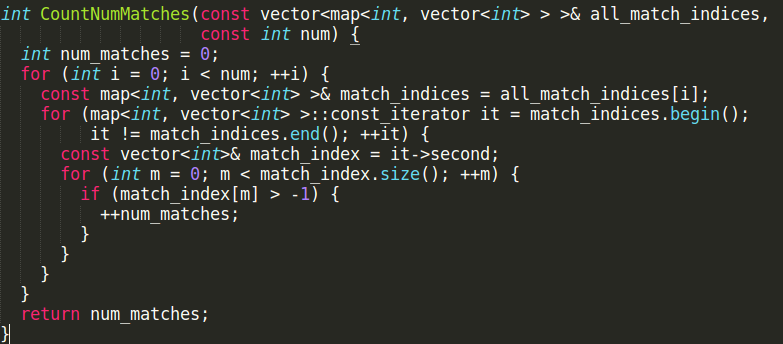
match_indices的size为0,所以后面两个for循环都不会执行。所以问题处在all_match_indices,all_match_indices又直接来自于MineHardExamples,所以返回看MineHardExamples。
MineHardExamples的all_match_indices来自于FindMatches,FindMatches也定义在bbox_util.cpp,如下图:
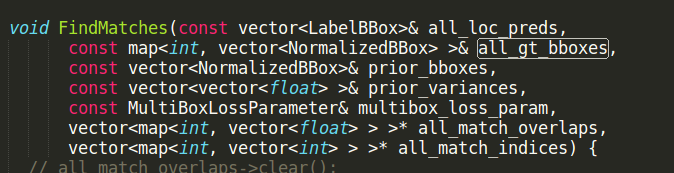
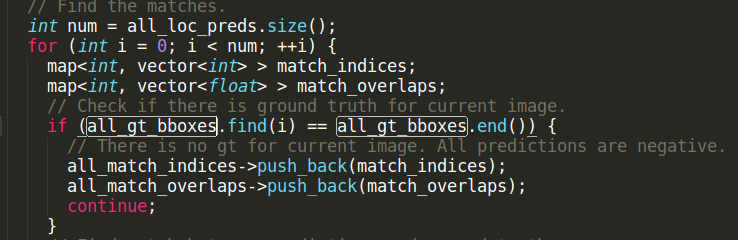
经过调试发现,FindMatches的all_gt_bboxes出错,按照作者注释:There is no gt for current image. All predictions are negative.
all_gt_bboxes来自于mbox_loss层GetGroundTruth函数:
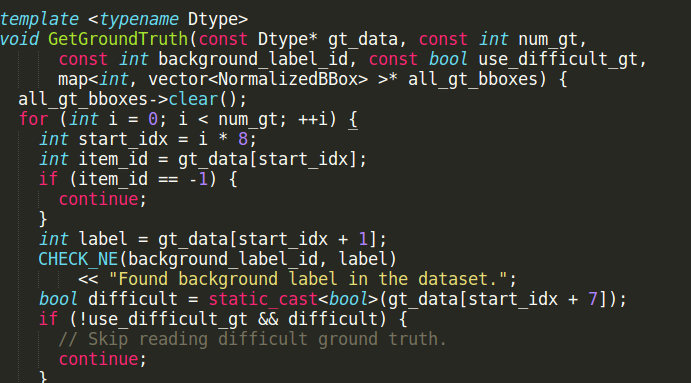
经调试发现item_id为-1,所以gt_data出现了错误,gt_data来自于bottom[3],如下图:
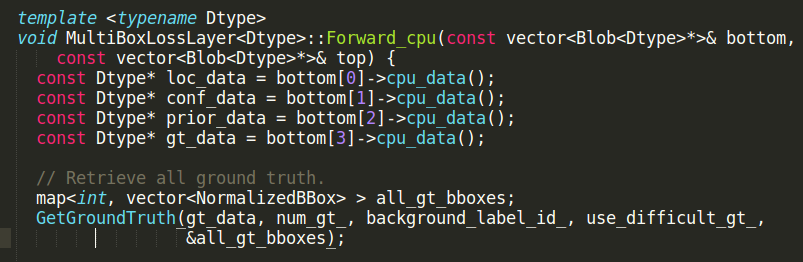
bottom[3]的数据是直接来自于data层(即annotated_data_layer层),传来的是从数据集得到的label数据,所以去看annotated_data_layer层。
要注意一个问题, mbox_loss层的bottom[3]其实是annotated_data_layer的top[1],即label。在annotated_data_layer.cpp中查找top[1],只有一个,涉及到top[1]的代码如下:
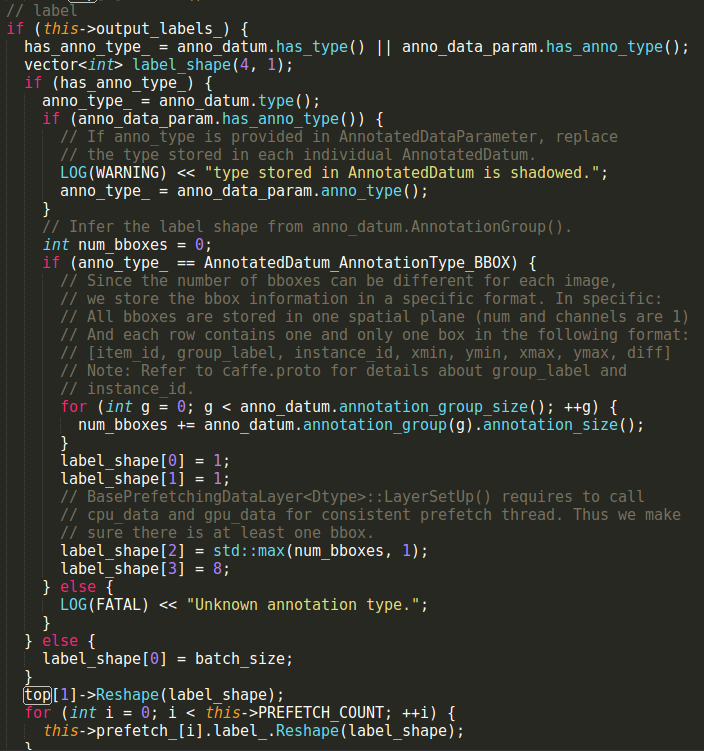
这一部分只是确定形状,真正载入数据的应该是load_batch的这一部分:
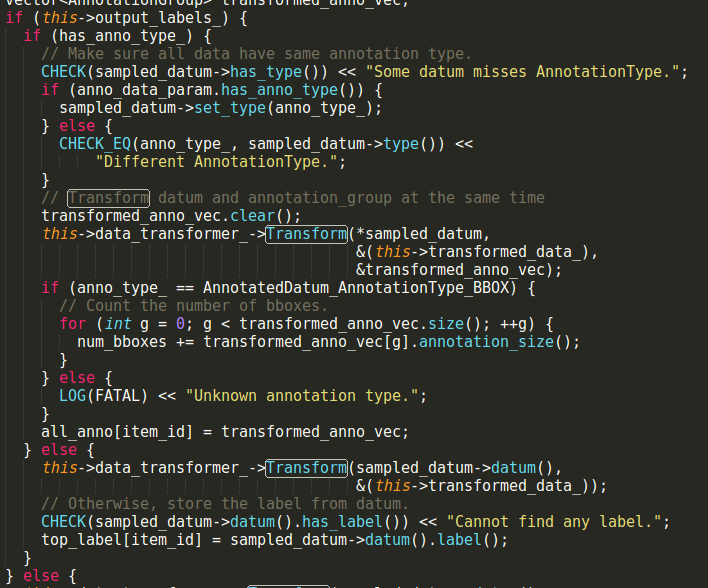
即Transform函数,Transform函数来自data_transformer.cpp,Transform函数最终又可以定位到TransformAnnotation函数,TransformAnnotation函数中的ProjectBBox(crop_bbox, resize_bbox, &proj_bbox)返回为false,ProjectBBox来自于bbox_util:
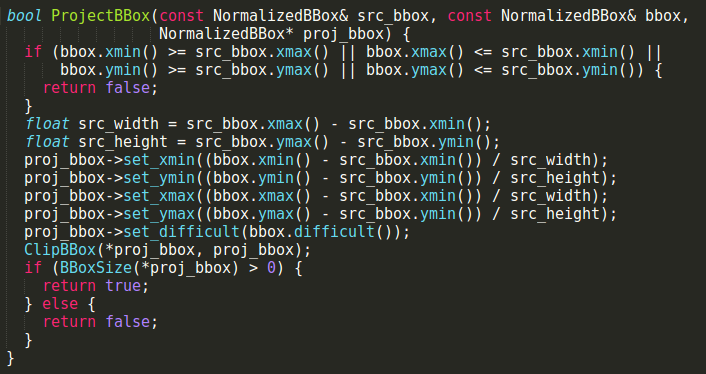
调试发现bbox的xmin,xmax,ymin,ymax都为0,这和第二个过程寻找bug的结果一样了:

后面还有很多自己继续看的源码,但实际上都不能直接解决问题。其实仔细思考,既然知道了从数据集读取的label有问题,那就直接定位数据读取的问题,直接调到第二个过程,而不是一而再再而三的往里面看源码,有点浪费时间。
2.第一个过程花费了很多时间看代码,依旧没能快速定位。尝试用一张图去跑程序,发现bug依旧存在。由第一个过程发现label为空想到应该可能是数据读取出现错误,所以将bug定位在数据读取部分。caffe读取的是lmdb数据库,自己的数据集是VOC格式的,所以需要将VOC转换为lmdb,步骤是先后使用create_list.sh和create_data.sh,create_data.sh就生成了lmdb。
看了一下create_list.sh生成的文件,感觉没什么问题,就去看create_data.sh。create_data.sh需要create_annoset.py,转去看create_annoset.py。create_annoset.py中使用了convert_annoset(cmd = "{}/build/tools/convert_annoset"),转去看convert_annoset。convert_annoset.cpp中使用了ReadRichImageToAnnotatedDatum函数,这个函数来自于io.cpp,转去看io.cpp。io.cpp中的ReadRichImageToAnnotatedDatum函数有ReadXMLToAnnotatedDatum函数,这个函数是读取xml文件的,转去看这个函数。

函数中有这样一段代码,这个时候就想到了在第一阶段看到的xmax为0,ymax为0。
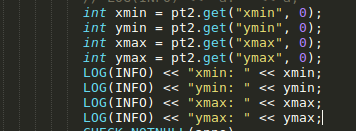
LOG输出看结果,这里的xmax和ymax也都为0。这说明从xml文件读取坐标时就出了错误。想一想本身代码应该不会有错,那就是我的xml文件有错,检查了很久发现xml文件格式没有错误。最后尝试将小数换成整数,发现就能正常读取这些坐标,loss的bug也解决了。
查阅资料,boost::property tree读取解析.xml文件的get函数有以下3种形式,把三种形式拿来调试:

下图是xml坐标为整数时的情况:

下图是xml坐标为浮点数的情况:

可以发现,为整数3种方式都可以,为小数的话,只能用float。想要实现浮点数坐标,就需要修改成以下形式:

并且你可以看到读取之后,就把这些坐标进行了回归处理:
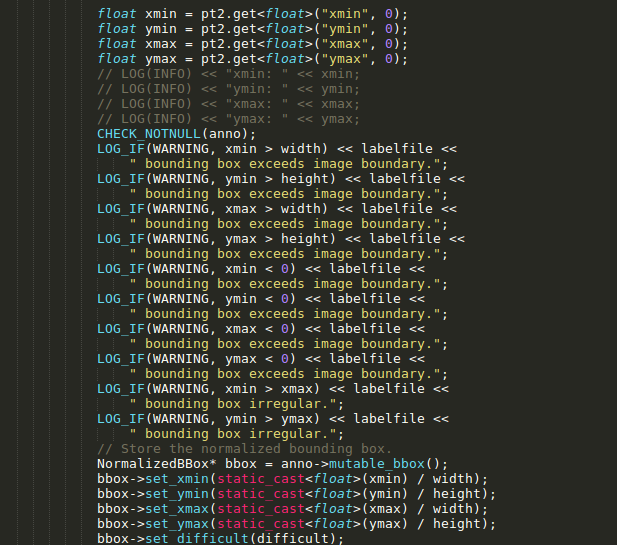
自己用datum.py读取的程序,修改bug后那个依旧是不对的
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=caffe%20detum&oq=datum%2520%25E6%2580%258E%25E4%25B9%2588%25E8%25AF%25BB&rsv_pq=cc56a2d200019cbb&rsv_t=d64chi4v5Hx3yBvu2spt16z0COREoG%2BSu1dt8AMBR%2Fa%2BdSExcqbrUwDUuOs&rqlang=cn&rsv_enter=1&inputT=4482&rsv_sug3=72&rsv_sug1=37&rsv_sug7=100&rsv_sug2=0&rsv_sug4=6527
https://zhuanlan.zhihu.com/p/23485774
http://blog.csdn.net/change_things/article/details/53158217
那个在等号前面的&引用
之所以不能LOG出来,是因为前面那个是一个datum类,不是int 或者float类型