refinedet只预测4个层,并且只有conv6_1、conv6_2,没有ssd中的conv7、8、9
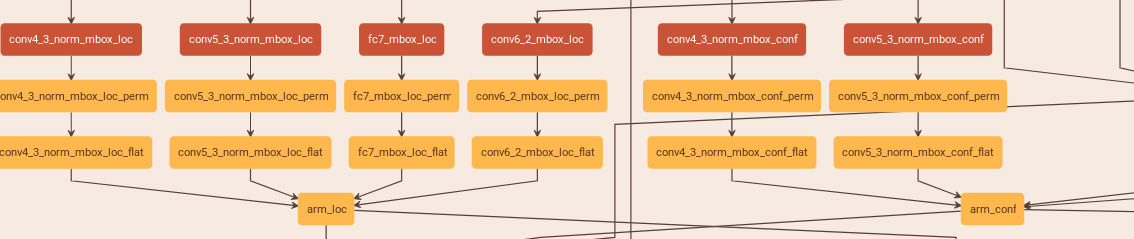
refinedet的4个层都只有1个aspect ratio和1个min_size,所以每层每个点只有3个anchor,arm中做location的conv4_3_norm_mbox_loc等层都是3*4个channel,做confidence的conv4_3_norm_mbox_conf都是6个channel,因为这里变成了2分类,每个anchor必须要有negative和positive的概率
refinedet是两步都要回归bounding box的框,refinedet中的odm_loss就相当于ssd中的mbox_loss,mbox_loss获得了anchor的坐标后会加上回归再进行训练,odm_loss获得anchor的坐标后先要加上arm_loc的回归,再加odm_loc的回归,这样再去进行loss计算.
name: "vgg_1/8" layer { name: "data" type: "AnnotatedData" top: "data" top: "label" include { phase: TRAIN } transform_param { mirror: true mean_value: 104.0 mean_value: 117.0 mean_value: 123.0 resize_param { prob: 1.0 resize_mode: WARP height: 352 704 interp_mode: LINEAR interp_mode: AREA interp_mode: NEAREST interp_mode: CUBIC interp_mode: LANCZOS4 } emit_constraint { emit_type: CENTER } distort_param { brightness_prob: 0.5 brightness_delta: 32.0 contrast_prob: 0.5 contrast_lower: 0.5 contrast_upper: 1.5 hue_prob: 0.5 hue_delta: 18.0 saturation_prob: 0.5 saturation_lower: 0.5 saturation_upper: 1.5 random_order_prob: 0.0 } expand_param { prob: 0.5 max_expand_ratio: 4.0 } } data_param { source:"examples/cityscapes/cityscapes_train_lmdb" batch_size: 1 backend: LMDB } annotated_data_param { batch_sampler { max_sample: 1 max_trials: 1 } batch_sampler { sampler { min_scale: 0.300000011921 max_scale: 1.0 min_aspect_ratio: 0.5 max_aspect_ratio: 2.0 } sample_constraint { min_jaccard_overlap: 0.10000000149 } max_sample: 1 max_trials: 50 } batch_sampler { sampler { min_scale: 0.300000011921 max_scale: 1.0 min_aspect_ratio: 0.5 max_aspect_ratio: 2.0 } sample_constraint { min_jaccard_overlap: 0.300000011921 } max_sample: 1 max_trials: 50 } batch_sampler { sampler { min_scale: 0.300000011921 max_scale: 1.0 min_aspect_ratio: 0.5 max_aspect_ratio: 2.0 } sample_constraint { min_jaccard_overlap: 0.5 } max_sample: 1 max_trials: 50 } batch_sampler { sampler { min_scale: 0.300000011921 max_scale: 1.0 min_aspect_ratio: 0.5 max_aspect_ratio: 2.0 } sample_constraint { min_jaccard_overlap: 0.699999988079 } max_sample: 1 max_trials: 50 } batch_sampler { sampler { min_scale: 0.300000011921 max_scale: 1.0 min_aspect_ratio: 0.5 max_aspect_ratio: 2.0 } sample_constraint { min_jaccard_overlap: 0.899999976158 } max_sample: 1 max_trials: 50 } batch_sampler { sampler { min_scale: 0.300000011921 max_scale: 1.0 min_aspect_ratio: 0.5 max_aspect_ratio: 2.0 } sample_constraint { max_jaccard_overlap: 1.0 } max_sample: 1 max_trials: 50 } label_map_file: "data/cityscapes/labelmap_cityscapes.prototxt" } } layer { name: "conv1_1" type: "Convolution" bottom: "data" top: "conv1_1" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 8 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu1_1" type: "ReLU" bottom: "conv1_1" top: "conv1_1" } layer { name: "conv1_2" type: "Convolution" bottom: "conv1_1" top: "conv1_2" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 8 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu1_2" type: "ReLU" bottom: "conv1_2" top: "conv1_2" } layer { name: "pool1" type: "Pooling" bottom: "conv1_2" top: "pool1" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "conv2_1" type: "Convolution" bottom: "pool1" top: "conv2_1" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu2_1" type: "ReLU" bottom: "conv2_1" top: "conv2_1" } layer { name: "conv2_2" type: "Convolution" bottom: "conv2_1" top: "conv2_2" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu2_2" type: "ReLU" bottom: "conv2_2" top: "conv2_2" } layer { name: "pool2" type: "Pooling" bottom: "conv2_2" top: "pool2" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "conv3_1" type: "Convolution" bottom: "pool2" top: "conv3_1" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu3_1" type: "ReLU" bottom: "conv3_1" top: "conv3_1" } layer { name: "conv3_2" type: "Convolution" bottom: "conv3_1" top: "conv3_2" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu3_2" type: "ReLU" bottom: "conv3_2" top: "conv3_2" } layer { name: "conv3_3" type: "Convolution" bottom: "conv3_2" top: "conv3_3" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu3_3" type: "ReLU" bottom: "conv3_3" top: "conv3_3" } layer { name: "pool3" type: "Pooling" bottom: "conv3_3" top: "pool3" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "conv4_1" type: "Convolution" bottom: "pool3" top: "conv4_1" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu4_1" type: "ReLU" bottom: "conv4_1" top: "conv4_1" } layer { name: "conv4_2" type: "Convolution" bottom: "conv4_1" top: "conv4_2" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu4_2" type: "ReLU" bottom: "conv4_2" top: "conv4_2" } layer { name: "conv4_3" type: "Convolution" bottom: "conv4_2" top: "conv4_3" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu4_3" type: "ReLU" bottom: "conv4_3" top: "conv4_3" } layer { name: "pool4" type: "Pooling" bottom: "conv4_3" top: "pool4" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "conv5_1" type: "Convolution" bottom: "pool4" top: "conv5_1" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu5_1" type: "ReLU" bottom: "conv5_1" top: "conv5_1" } layer { name: "conv5_2" type: "Convolution" bottom: "conv5_1" top: "conv5_2" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu5_2" type: "ReLU" bottom: "conv5_2" top: "conv5_2" } layer { name: "conv5_3" type: "Convolution" bottom: "conv5_2" top: "conv5_3" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu5_3" type: "ReLU" bottom: "conv5_3" top: "conv5_3" } layer { name: "pool5" type: "Pooling" bottom: "conv5_3" top: "pool5" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "fc6" type: "Convolution" bottom: "pool5" top: "fc6" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 128 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu6" type: "ReLU" bottom: "fc6" top: "fc6" } layer { name: "fc7" type: "Convolution" bottom: "fc6" top: "fc7" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 128 kernel_size: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu7" type: "ReLU" bottom: "fc7" top: "fc7" } layer { name: "conv6_1" type: "Convolution" bottom: "fc7" top: "conv6_1" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 0 kernel_size: 1 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "conv6_1_relu" type: "ReLU" bottom: "conv6_1" top: "conv6_1" } layer { name: "conv6_2" type: "Convolution" bottom: "conv6_1" top: "conv6_2" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 stride: 2 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "conv6_2_relu" type: "ReLU" bottom: "conv6_2" top: "conv6_2" } layer { name: "conv4_3_norm_mbox_loc" type: "Convolution" bottom: "conv4_3" top: "conv4_3_norm_mbox_loc" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "conv4_3_norm_mbox_loc_perm" type: "Permute" bottom: "conv4_3_norm_mbox_loc" top: "conv4_3_norm_mbox_loc_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "conv4_3_norm_mbox_loc_flat" type: "Flatten" bottom: "conv4_3_norm_mbox_loc_perm" top: "conv4_3_norm_mbox_loc_flat" flatten_param { axis: 1 } } layer { name: "conv4_3_norm_mbox_conf" type: "Convolution" bottom: "conv4_3" top: "conv4_3_norm_mbox_conf" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 6 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "conv4_3_norm_mbox_conf_perm" type: "Permute" bottom: "conv4_3_norm_mbox_conf" top: "conv4_3_norm_mbox_conf_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "conv4_3_norm_mbox_conf_flat" type: "Flatten" bottom: "conv4_3_norm_mbox_conf_perm" top: "conv4_3_norm_mbox_conf_flat" flatten_param { axis: 1 } } layer { name: "conv4_3_norm_mbox_priorbox" type: "PriorBox" bottom: "conv4_3" bottom: "data" top: "conv4_3_norm_mbox_priorbox" prior_box_param { min_size: 16.0 aspect_ratio: 2.0 flip: true clip: false variance: 0.10000000149 variance: 0.10000000149 variance: 0.20000000298 variance: 0.20000000298 step: 8.0 offset: 0.5 } } layer { name: "conv5_3_norm_mbox_loc" type: "Convolution" bottom: "conv5_3" top: "conv5_3_norm_mbox_loc" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "conv5_3_norm_mbox_loc_perm" type: "Permute" bottom: "conv5_3_norm_mbox_loc" top: "conv5_3_norm_mbox_loc_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "conv5_3_norm_mbox_loc_flat" type: "Flatten" bottom: "conv5_3_norm_mbox_loc_perm" top: "conv5_3_norm_mbox_loc_flat" flatten_param { axis: 1 } } layer { name: "conv5_3_norm_mbox_conf" type: "Convolution" bottom: "conv5_3" top: "conv5_3_norm_mbox_conf" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 6 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "conv5_3_norm_mbox_conf_perm" type: "Permute" bottom: "conv5_3_norm_mbox_conf" top: "conv5_3_norm_mbox_conf_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "conv5_3_norm_mbox_conf_flat" type: "Flatten" bottom: "conv5_3_norm_mbox_conf_perm" top: "conv5_3_norm_mbox_conf_flat" flatten_param { axis: 1 } } layer { name: "conv5_3_norm_mbox_priorbox" type: "PriorBox" bottom: "conv5_3" bottom: "data" top: "conv5_3_norm_mbox_priorbox" prior_box_param { min_size: 32.0 aspect_ratio: 2.0 flip: true clip: false variance: 0.10000000149 variance: 0.10000000149 variance: 0.20000000298 variance: 0.20000000298 step: 16.0 offset: 0.5 } } layer { name: "fc7_mbox_loc" type: "Convolution" bottom: "fc7" top: "fc7_mbox_loc" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "fc7_mbox_loc_perm" type: "Permute" bottom: "fc7_mbox_loc" top: "fc7_mbox_loc_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "fc7_mbox_loc_flat" type: "Flatten" bottom: "fc7_mbox_loc_perm" top: "fc7_mbox_loc_flat" flatten_param { axis: 1 } } layer { name: "fc7_mbox_conf" type: "Convolution" bottom: "fc7" top: "fc7_mbox_conf" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 6 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "fc7_mbox_conf_perm" type: "Permute" bottom: "fc7_mbox_conf" top: "fc7_mbox_conf_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "fc7_mbox_conf_flat" type: "Flatten" bottom: "fc7_mbox_conf_perm" top: "fc7_mbox_conf_flat" flatten_param { axis: 1 } } layer { name: "fc7_mbox_priorbox" type: "PriorBox" bottom: "fc7" bottom: "data" top: "fc7_mbox_priorbox" prior_box_param { min_size: 64.0 aspect_ratio: 2.0 flip: true clip: false variance: 0.10000000149 variance: 0.10000000149 variance: 0.20000000298 variance: 0.20000000298 step: 32.0 offset: 0.5 } } layer { name: "conv6_2_mbox_loc" type: "Convolution" bottom: "conv6_2" top: "conv6_2_mbox_loc" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "conv6_2_mbox_loc_perm" type: "Permute" bottom: "conv6_2_mbox_loc" top: "conv6_2_mbox_loc_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "conv6_2_mbox_loc_flat" type: "Flatten" bottom: "conv6_2_mbox_loc_perm" top: "conv6_2_mbox_loc_flat" flatten_param { axis: 1 } } layer { name: "conv6_2_mbox_conf" type: "Convolution" bottom: "conv6_2" top: "conv6_2_mbox_conf" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 6 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "conv6_2_mbox_conf_perm" type: "Permute" bottom: "conv6_2_mbox_conf" top: "conv6_2_mbox_conf_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "conv6_2_mbox_conf_flat" type: "Flatten" bottom: "conv6_2_mbox_conf_perm" top: "conv6_2_mbox_conf_flat" flatten_param { axis: 1 } } layer { name: "conv6_2_mbox_priorbox" type: "PriorBox" bottom: "conv6_2" bottom: "data" top: "conv6_2_mbox_priorbox" prior_box_param { min_size: 128.0 aspect_ratio: 2.0 flip: true clip: false variance: 0.10000000149 variance: 0.10000000149 variance: 0.20000000298 variance: 0.20000000298 step: 64.0 offset: 0.5 } } layer { name: "arm_loc" type: "Concat" bottom: "conv4_3_norm_mbox_loc_flat" bottom: "conv5_3_norm_mbox_loc_flat" bottom: "fc7_mbox_loc_flat" bottom: "conv6_2_mbox_loc_flat" top: "arm_loc" concat_param { axis: 1 } } layer { name: "arm_conf" type: "Concat" bottom: "conv4_3_norm_mbox_conf_flat" bottom: "conv5_3_norm_mbox_conf_flat" bottom: "fc7_mbox_conf_flat" bottom: "conv6_2_mbox_conf_flat" top: "arm_conf" concat_param { axis: 1 } } layer { name: "arm_priorbox" type: "Concat" bottom: "conv4_3_norm_mbox_priorbox" bottom: "conv5_3_norm_mbox_priorbox" bottom: "fc7_mbox_priorbox" bottom: "conv6_2_mbox_priorbox" top: "arm_priorbox" concat_param { axis: 2 } } layer { name: "P3_mbox_loc_p" type: "Convolution" bottom: "conv4_3" top: "P3_mbox_loc" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "P3_mbox_loc_perm" type: "Permute" bottom: "P3_mbox_loc" top: "P3_mbox_loc_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "P3_mbox_loc_flat" type: "Flatten" bottom: "P3_mbox_loc_perm" top: "P3_mbox_loc_flat" flatten_param { axis: 1 } } layer { name: "P3_mbox_conf_p" type: "Convolution" bottom: "conv4_3" top: "P3_mbox_conf" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "P3_mbox_conf_perm" type: "Permute" bottom: "P3_mbox_conf" top: "P3_mbox_conf_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "P3_mbox_conf_flat" type: "Flatten" bottom: "P3_mbox_conf_perm" top: "P3_mbox_conf_flat" flatten_param { axis: 1 } } layer { name: "P4_mbox_loc_p" type: "Convolution" bottom: "conv5_3" top: "P4_mbox_loc" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "P4_mbox_loc_perm" type: "Permute" bottom: "P4_mbox_loc" top: "P4_mbox_loc_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "P4_mbox_loc_flat" type: "Flatten" bottom: "P4_mbox_loc_perm" top: "P4_mbox_loc_flat" flatten_param { axis: 1 } } layer { name: "P4_mbox_conf_p" type: "Convolution" bottom: "conv5_3" top: "P4_mbox_conf" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "P4_mbox_conf_perm" type: "Permute" bottom: "P4_mbox_conf" top: "P4_mbox_conf_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "P4_mbox_conf_flat" type: "Flatten" bottom: "P4_mbox_conf_perm" top: "P4_mbox_conf_flat" flatten_param { axis: 1 } } layer { name: "P5_mbox_loc_p" type: "Convolution" bottom: "fc7" top: "P5_mbox_loc" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "P5_mbox_loc_perm" type: "Permute" bottom: "P5_mbox_loc" top: "P5_mbox_loc_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "P5_mbox_loc_flat" type: "Flatten" bottom: "P5_mbox_loc_perm" top: "P5_mbox_loc_flat" flatten_param { axis: 1 } } layer { name: "P5_mbox_conf_p" type: "Convolution" bottom: "fc7" top: "P5_mbox_conf" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "P5_mbox_conf_perm" type: "Permute" bottom: "P5_mbox_conf" top: "P5_mbox_conf_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "P5_mbox_conf_flat" type: "Flatten" bottom: "P5_mbox_conf_perm" top: "P5_mbox_conf_flat" flatten_param { axis: 1 } } layer { name: "P6_mbox_loc_p" type: "Convolution" bottom: "conv6_2" top: "P6_mbox_loc" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "P6_mbox_loc_perm" type: "Permute" bottom: "P6_mbox_loc" top: "P6_mbox_loc_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "P6_mbox_loc_flat" type: "Flatten" bottom: "P6_mbox_loc_perm" top: "P6_mbox_loc_flat" flatten_param { axis: 1 } } layer { name: "P6_mbox_conf_p" type: "Convolution" bottom: "conv6_2" top: "P6_mbox_conf" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } convolution_param { num_output: 12 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "P6_mbox_conf_perm" type: "Permute" bottom: "P6_mbox_conf" top: "P6_mbox_conf_perm" permute_param { order: 0 order: 2 order: 3 order: 1 } } layer { name: "P6_mbox_conf_flat" type: "Flatten" bottom: "P6_mbox_conf_perm" top: "P6_mbox_conf_flat" flatten_param { axis: 1 } } layer { name: "odm_loc" type: "Concat" bottom: "P3_mbox_loc_flat" bottom: "P4_mbox_loc_flat" bottom: "P5_mbox_loc_flat" bottom: "P6_mbox_loc_flat" top: "odm_loc" concat_param { axis: 1 } } layer { name: "odm_conf" type: "Concat" bottom: "P3_mbox_conf_flat" bottom: "P4_mbox_conf_flat" bottom: "P5_mbox_conf_flat" bottom: "P6_mbox_conf_flat" top: "odm_conf" concat_param { axis: 1 } } layer { name: "arm_loss" type: "MultiBoxLoss" bottom: "arm_loc" bottom: "arm_conf" bottom: "arm_priorbox" bottom: "label" top: "arm_loss" include { phase: TRAIN } propagate_down: true propagate_down: true propagate_down: false propagate_down: false loss_param { normalization: VALID } multibox_loss_param { loc_loss_type: SMOOTH_L1 conf_loss_type: SOFTMAX loc_weight: 1.0 num_classes: 2 share_location: true match_type: PER_PREDICTION overlap_threshold: 0.5 use_prior_for_matching: true background_label_id: 0 use_difficult_gt: true neg_pos_ratio: 3.0 neg_overlap: 0.5 code_type: CENTER_SIZE ignore_cross_boundary_bbox: false mining_type: MAX_NEGATIVE objectness_score: 0.00999999977648 } } layer { name: "arm_conf_reshape" type: "Reshape" bottom: "arm_conf" top: "arm_conf_reshape" reshape_param { shape { dim: 0 dim: -1 dim: 2 } } } layer { name: "arm_conf_softmax" type: "Softmax" bottom: "arm_conf_reshape" top: "arm_conf_softmax" softmax_param { axis: 2 } } layer { name: "arm_conf_flatten" type: "Flatten" bottom: "arm_conf_softmax" top: "arm_conf_flatten" flatten_param { axis: 1 } } layer { name: "odm_loss" type: "MultiBoxLoss" bottom: "odm_loc" bottom: "odm_conf" bottom: "arm_priorbox" bottom: "label" bottom: "arm_conf_flatten" bottom: "arm_loc" top: "odm_loss" include { phase: TRAIN } propagate_down: true propagate_down: true propagate_down: false propagate_down: false propagate_down: false propagate_down: false loss_param { normalization: VALID } multibox_loss_param { loc_loss_type: SMOOTH_L1 conf_loss_type: SOFTMAX loc_weight: 1.0 num_classes: 4 share_location: true match_type: PER_PREDICTION overlap_threshold: 0.5 use_prior_for_matching: true background_label_id: 0 use_difficult_gt: true neg_pos_ratio: 3.0 neg_overlap: 0.5 code_type: CENTER_SIZE ignore_cross_boundary_bbox: false mining_type: MAX_NEGATIVE objectness_score: 0.00999999977648 } } layer { name: "conv1_1_t" type: "Convolution" bottom: "data" top: "conv1_1_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu1_1_t" type: "ReLU" bottom: "conv1_1_t" top: "conv1_1_t" } layer { name: "conv1_2_t" type: "Convolution" bottom: "conv1_1_t" top: "conv1_2_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu1_2_t" type: "ReLU" bottom: "conv1_2_t" top: "conv1_2_t" } layer { name: "pool1_t" type: "Pooling" bottom: "conv1_2_t" top: "pool1_t" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "conv2_1_t" type: "Convolution" bottom: "pool1_t" top: "conv2_1_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 128 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu2_1_t" type: "ReLU" bottom: "conv2_1_t" top: "conv2_1_t" } layer { name: "conv2_2_t" type: "Convolution" bottom: "conv2_1_t" top: "conv2_2_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 128 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu2_2_t" type: "ReLU" bottom: "conv2_2_t" top: "conv2_2_t" } layer { name: "pool2_t" type: "Pooling" bottom: "conv2_2_t" top: "pool2_t" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "conv3_1_t" type: "Convolution" bottom: "pool2_t" top: "conv3_1_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 256 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu3_1_t" type: "ReLU" bottom: "conv3_1_t" top: "conv3_1_t" } layer { name: "conv3_2_t" type: "Convolution" bottom: "conv3_1_t" top: "conv3_2_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 256 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu3_2_t" type: "ReLU" bottom: "conv3_2_t" top: "conv3_2_t" } layer { name: "conv3_3_t" type: "Convolution" bottom: "conv3_2_t" top: "conv3_3_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 256 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu3_3_t" type: "ReLU" bottom: "conv3_3_t" top: "conv3_3_t" } layer { name: "pool3_t" type: "Pooling" bottom: "conv3_3_t" top: "pool3_t" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "conv4_1_t" type: "Convolution" bottom: "pool3_t" top: "conv4_1_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 512 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu4_1_t" type: "ReLU" bottom: "conv4_1_t" top: "conv4_1_t" } layer { name: "conv4_2_t" type: "Convolution" bottom: "conv4_1_t" top: "conv4_2_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 512 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu4_2_t" type: "ReLU" bottom: "conv4_2_t" top: "conv4_2_t" } layer { name: "conv4_3_t" type: "Convolution" bottom: "conv4_2_t" top: "conv4_3_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 512 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } } } layer { name: "relu4_3_t" type: "ReLU" bottom: "conv4_3_t" top: "conv4_3_t" } layer { name: "pool4_t" type: "Pooling" bottom: "conv4_3_t" top: "pool4_t" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "conv5_1_t" type: "Convolution" bottom: "pool4_t" top: "conv5_1_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 512 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } dilation: 1 } } layer { name: "relu5_1_t" type: "ReLU" bottom: "conv5_1_t" top: "conv5_1_t" } layer { name: "conv5_2_t" type: "Convolution" bottom: "conv5_1_t" top: "conv5_2_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 512 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } dilation: 1 } } layer { name: "relu5_2_t" type: "ReLU" bottom: "conv5_2_t" top: "conv5_2_t" } layer { name: "conv5_3_t" type: "Convolution" bottom: "conv5_2_t" top: "conv5_3_t" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } convolution_param { num_output: 512 pad: 1 kernel_size: 3 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0.0 } dilation: 1 } } layer { name: "relu5_3_t" type: "ReLU" bottom: "conv5_3_t" top: "conv5_3_t" } layer { name: "conv5_3_m" type: "Convolution" bottom: "conv5_3" top: "conv5_3_m" propagate_down: true param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 512 kernel_size: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "relu5_3_m" type: "ReLU" bottom: "conv5_3_m" top: "conv5_3_m" } layer { name: "roi_pool_t" type: "ROIPooling" bottom: "conv5_3_t" bottom: "label" top: "pool_t" roi_pooling_param { pooled_w: 7 pooled_h: 7 } propagate_down: false propagate_down: false } layer { name: "roi_pool_s" type: "ROIPooling" bottom: "conv5_3_m" bottom: "label" top: "pool_s" roi_pooling_param { pooled_w: 7 pooled_h: 7 } propagate_down: true propagate_down: false } layer { name: "mimic_loss" type: "EuclideanLoss" bottom: "pool_t" bottom: "pool_s" top: "mimic_loss" propagate_down: false propagate_down: true loss_weight: 10 include { phase: TRAIN } }