class-aware detector 和 class-agnostic detector:https://blog.csdn.net/yeyang911/article/details/68484486
既解决多尺度,又解决小物体
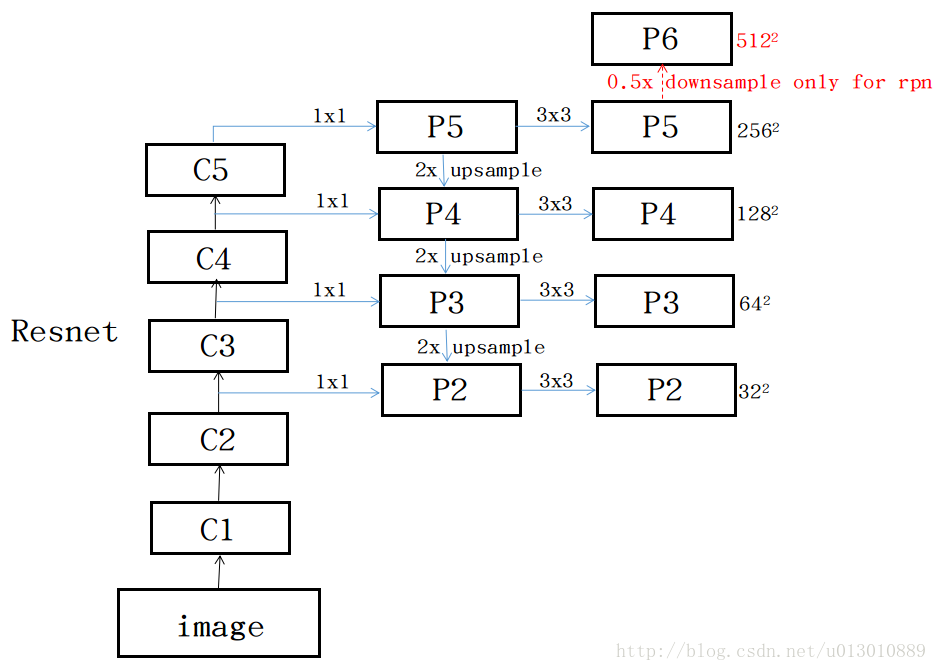
1.实现的细节:rpn阶段用了5个stage,fast阶段只用了4个stage,也就是p6这个stage只用来提取anchor,不参与分类和定位。github上这个代码,反卷积升维前还使用了1*1卷积,原论文中并没有提到这个。每个p阶段生成rpn的时候要跟faster一样,先3*3然后两个1*1分别做分类和定位。每个p阶段提取anchor的时候使用的相同的ratio,是1:2、1:1、2:1。每层设置一个scle,32^2, 64^2, 128^2, 256^2, 512^2分别对应p2到p5,但caffe的复现写的每层都是相同的两个scale。还有一个值得注意的地方,经过横向连接的p阶段的feature map,不是直接作为最后的特征层,而是都要经过一个3*3的卷积生成新的p,原论文说是为了减小上采样带来的混叠效应(“混叠”指的是高频信息在降采样的时候,重叠到低频段上面去的现象,目前也没有一个特别好的解释,暂时这个)。caffe的复现并没有这样做,而是直接拿p阶段的feature map当成最后的特征提取的feature map。
原论文中是使用的最近邻上采样,不是deconv
https://blog.csdn.net/stf1065716904/article/details/78450997
https://blog.csdn.net/u013010889/article/details/78658135
进一步问题:为什么p6只用来提取anchor?
为什么要乘以3*3再两个1*1做分类和定位?
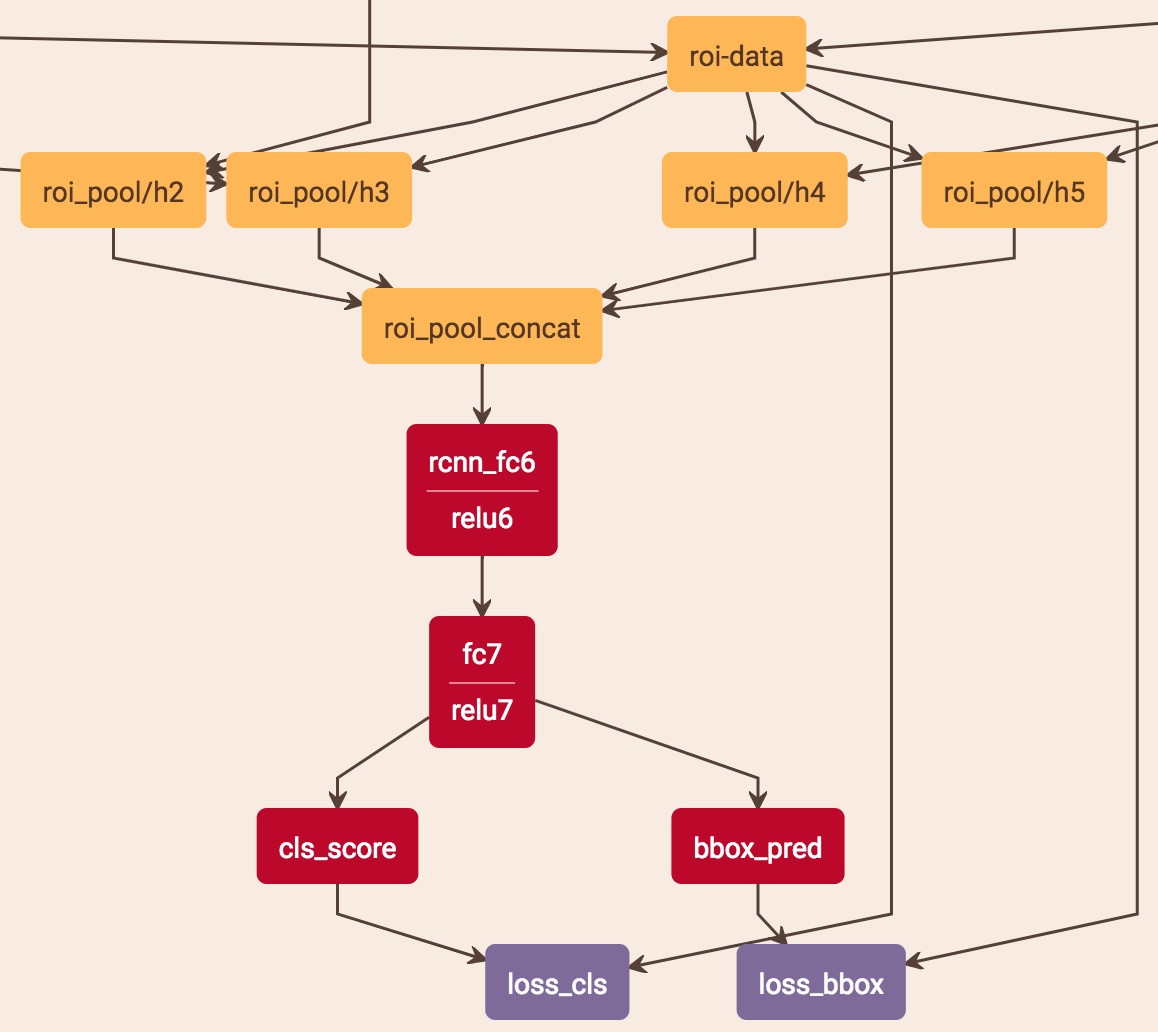
在最后的fast rcnn中,原论文的head部分采用了参数共享,即把从4个层的特征提取层pooling得到的结果用axis = 0 concat起来然后用两个fc:
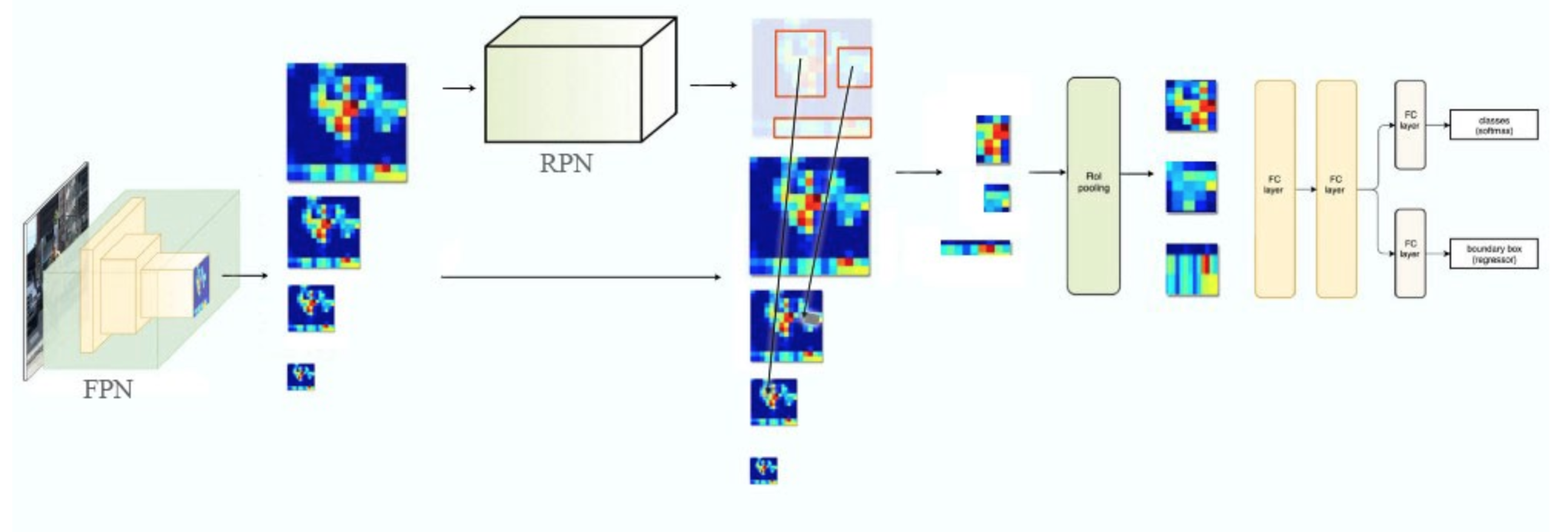
caffe的代码使用了两个版本,一个共享,一个不共享:
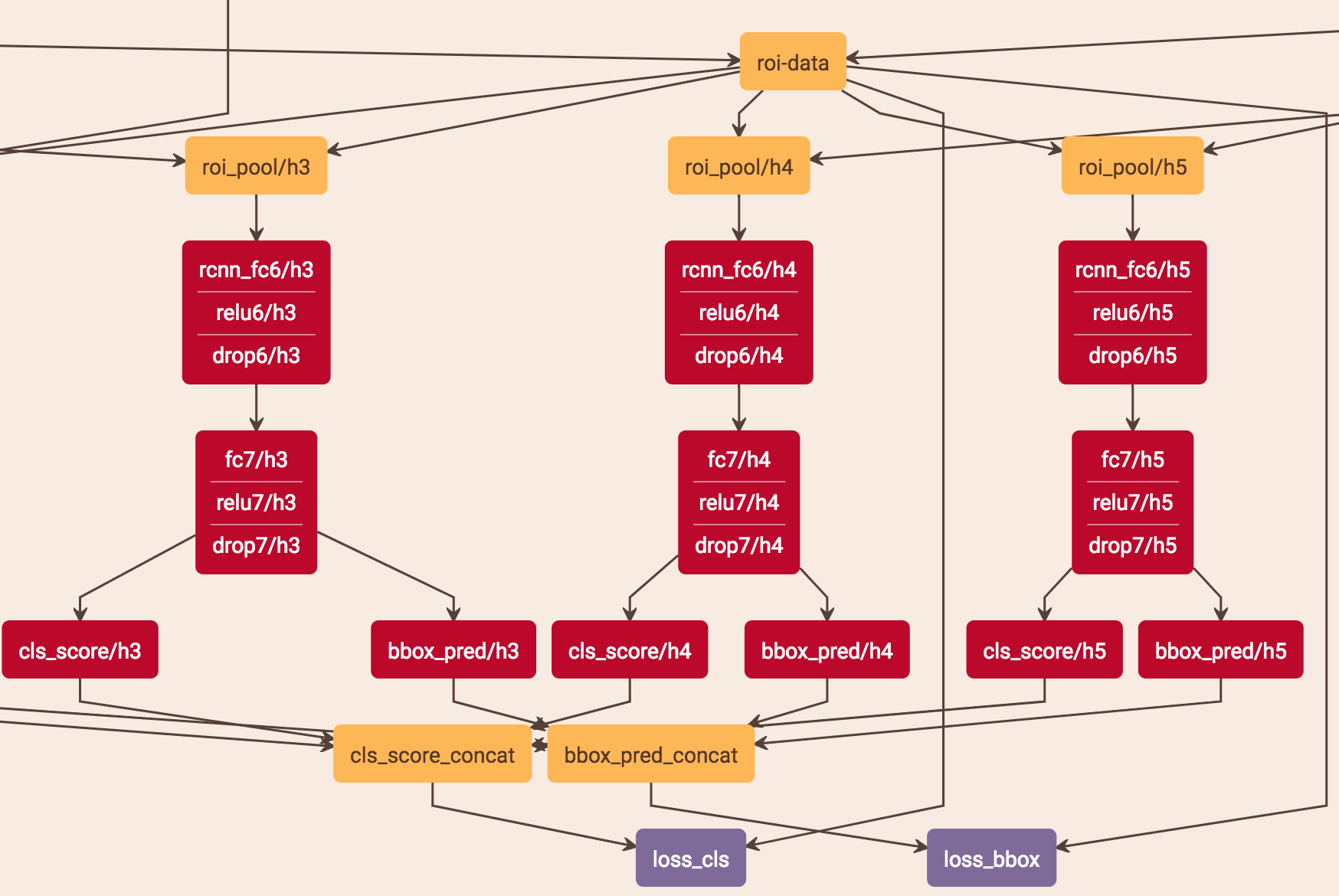
https://zhuanlan.zhihu.com/p/35854548这篇博客也提到要参数共享
2.roi怎么区分从哪个层里出来
通过roi本身的长宽判断。每个roi设置layer_index,layer_index通过下式获得:
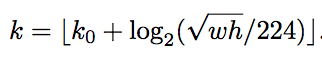
k0 = 4,wh为roi的长宽,相当于以第4层为基准进行加减。以w、h分别为224的1/2,那log出来的结果就是-1,就是第三层。
具体实现的细节:不可能所有的刚好都为224的整数倍,所以进行了向下取整。因为网络本身只用p2-p5,所以结果小于2的k为2,大于5的k为5,相当于更小的放在p2阶段,更大的放在p5阶段。总的分布情况是:(0,112)在p2,[112,224]在p3,(224,448)在p4,[448,+∞)在p5.
延伸问题:为什么要除以224?为什么要以p4为基准?为什么要向下取整?
向下取整?因为很多size肯定不能整除,但需要指定在哪一层,所以需要取整。向下的原因还没有想清楚
为什么要除以224?为什么要以p4为基准?
原论文说224是canonical Imagenet pre-training size,可以这样理解,pre-train的模型做分类识别就是识别的224size的图,现在的检测框相当于把整个图拿来做分类识别,并且网络的初始化参数来自于在imagenet上pre-train好的分类参数。
自己的一些拍脑袋想法:
我曾觉得会不会所有的anchor集中在某一个p stage,其他p stage没有anchor导致性能不好。对于一般的拥有大小物体的图片而言,应该是所有p stage可能都有的,不过也许可能出现正anchor集中在某一个p stage,其他p stage全是负样本,但是其他p stage也还是在学习的。换另一种idea想,即使就算你所有的正负anchor都集中在p2(比如只检测小物体,可能绝大部分就集中在p2),其他层也是会学到的,因为p2有一个分支会来自其他高层的横向连接,反向传播也会传递给这些高层,相当于stage2(是网路原本的backbone,不是1*1卷积生成的p2)部分,既要受到来自stage3个梯度,也要受到来自p2的梯度,两个梯度其实也相当于两个监督,就像mask那样,但是这个有有点不一样,因为这两个梯度来自于同一个loss。但是如果你既有p5的loss又有p2的loss,那stage2的梯度既有p2的,也有p5的,p5这部分的梯度又可以分为p2的和p5的。不过这里就牵涉到另一个idea,如果只有小物体作为训练,那是不是性能会比既有小又有大的变差,因为你的梯度变少,你的高层的语义信息可能训练的并没有那么好。
2.eltwise和concat的优缺点
concat首先容易出现问题,其次参数量增加
eltwise,即使a的值很大,b的值很小,相加后,是ab共同大的地方加起来依旧大,相应也就依旧保留,也就保留了这种位置信息,但concat好像并不能
3.横向连接的时候为什么要先1*1?
a.做降维保证都是256
b.缓冲作用,防止梯度直接影响bottom-up主干网络,更稳定
为什么要保证都是是同一个维度?
因为为了elemtwise相加
进一步问题:为什么要选择256?
4.几个重要的对比实验:
a.去掉top-down,类似于SSD在各个不同scale的feature上做预测。具体做法是:保留横向连接1*1,同时也保留3*3然后生成新的p stage。和基础model比,效果是rpn的召回率高了,但小物体的召回率反而降低了;ap值降低了,小、中、大都降低了。作者认为这是因为stage之间的语义差别特别大,特别是深层网络。证明了top-down的重要性。
b.砍掉横向连接,只保留自上而下放大 feature map 做预测(我自己之前以为只是说去掉1*1,浅层的还是要和高层的融合,这个想法是错误的)。这个做法出来的结果是召回率大大降低,ap相较于base模型提升了,相较于fpn降低了。其实这个做法相当于把网络加深,这样语义信息更加加强了,所以ap值会升高。这里实际上预测的层,feature map像素和fpn的像素是一样大的,按理说语义信息还提高了,但是ap却低与fpn,主要原因是位置信息不够精确,因为这些层经过了多次的上下采样。按理说,下采样才会到底位置信息不准确,上采样是怎么导致的?
c.这个是只用迭代到最后分辨率最高的P2,所有scale和比例的anchor都在P2取,由于P2比较大所有scale都在它上面取,anchor数量提升了很多,速度会慢。它的精度好于baseline但是低于原始的fpn。作者认为在金字塔不同level滑动能增加对尺寸不变性的鲁棒性。这种方式会生成比fpn更多的anchor,这个实验证明并不是越多的anchor性能就越好,个人觉得还是质量越高的anchor性能才越好。
5.作者还提出了一个重要观点:在RPN和object detection任务中,FPN中每一层的heads 参数都是共享的,作者认为共享参数的效果也不错就说明FPN中所有层的语义都相似
- heads的参数被所有的feature pyramid level共享,作者也测试了不共享的情况,发现结果相似。参数分享仍有好的结果说明pyramid的所有levels共享相似的语义levels,这个好处类比于featurized image pyramid中一个常见的head分类器可以被应用到任何图像尺度生成的特征上。https://www.ganwenyao.com/deepLearning/objectDetection/FPN
6.横向连接的时候直接使用1*1,而没有加非线性的激活函数,作者实验发现会有轻微影响。为什么会有?其实我需要的是准确的位置信息,但非线性其实提供的是一些特征提取,导致一些原始的信息丢失。
CVPR 现场 QA:
1. 不同深度的 feature map 为什么可以经过 upsample 后直接相加?
A:作者解释说这个原因在于我们做了 end-to-end 的 training,因为不同层的参数不是固定的,不同层同时给监督做 end-to-end training,所以相加训练出来的东西能够更有效地融合浅层和深层的信息。
2. 为什么 FPN 相比去掉深层特征 upsample(bottom-up pyramid) 对于小物体检测提升明显?(RPN 步骤 AR 从 30.5 到 44.9,Fast RCNN 步骤 AP 从 24.9 到 33.9)
A:作者在 poster 里给出了这个问题的答案

对于小物体,一方面我们需要高分辨率的 feature map 更多关注小区域信息,另一方面,如图中的挎包一样,需要更全局的信息更准确判断挎包的存在及位置。
3. 如果不考虑时间情况下,image pyramid 是否可能会比 feature pyramid 的性能更高?
A:作者觉得经过精细调整训练是可能的,但是 image pyramid 主要的问题在于时间和空间占用太大,而 feature pyramid 可以在几乎不增加额外计算量情况下解决多尺度检测问题。
fpn的速度加快了?
原始的resnet做faster,最后一层特征提取层是2048(或者是1024?),但现在的fpn的最后几层做pooling的feature map只有256,所以论文说速度加快了has a lighter weight head,因为per region 的计算变少了。不过作者也说Our method introduces small extra cost by the extra layers in the FPN。
这样说来,如果都是提取的相同的channel,fpn速度应该还是增加吧。不过考虑一个问题,faster是一个一个roi做pooling,但是fpn多个roi其实是可以做并行的?这个有待观察。
代码实现:https://github.com/unsky/FPN