1.producer端的基本数据结构
1.ProducerRecord
一个ProducerRecord封装了一条待发送的消息
public class ProducerRecord<K, V> { private final String topic; private final Integer partition; private final Headers headers; private final K key; private final V value; private final Long timestamp;
ProducerRecord允许用户再创建消息对象的时候直接指定要发送的分区
2.RecordMetadata
该数据结构表示Kafka服务端返回给客户端的消息的元数据信息
public final class RecordMetadata { /** * Partition value for record without partition assigned */ public static final int UNKNOWN_PARTITION = -1; private final long offset; // 位移信息 // The timestamp of the message. // If LogAppendTime is used for the topic, the timestamp will be the timestamp returned by the broker. // If CreateTime is used for the topic, the timestamp is the timestamp in the corresponding ProducerRecord if the // user provided one. Otherwise, it will be the producer local time when the producer record was handed to the // producer. private final long timestamp; // 消息时间戳 private final int serializedKeySize; // 序列化后的消息key字节数 private final int serializedValueSize; // 序列化后的消息value字节数 private final TopicPartition topicPartition; // 所属topic的分区 private volatile Long checksum; // 消息的CRC32码
2.工作流程
用户首先创建待发送的消息对象ProducerRecord,然后调用KafkaProducer#send方法进行发送,KafkaProducer接收到消息后首先对其序列化,然后结合本地缓存的元数据信息一起发送给partitioner去确定目标分区,最后追加写入内存中的消息缓冲池(accumulator),此时send方法成功返回。

KafkaProducer中有一个专门的Sender IO线程负责将缓冲池的消息分批发送给对应的broker,完成真正的发送逻辑
下面看一下KafkaProducer.send(ProducerRecord,callback)时kafka内部都发生了什么事情。
第一步,序列化+计算目标分区
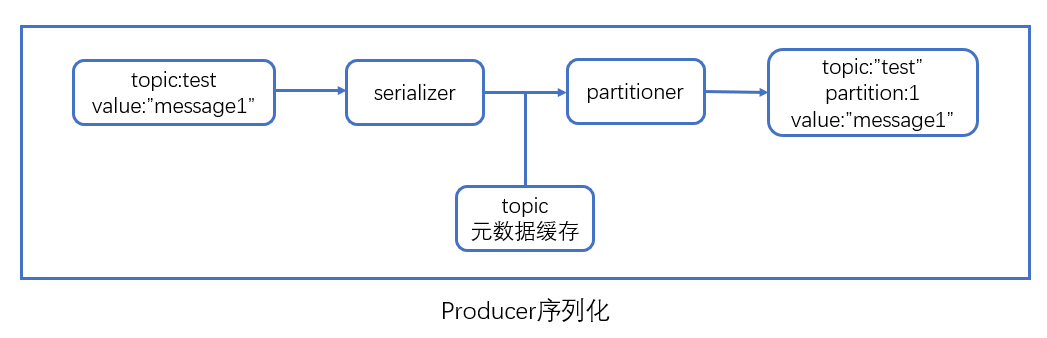
代码
byte[] serializedKey; try { serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key()); } catch (ClassCastException cce) { throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() + " specified in key.serializer", cce); } byte[] serializedValue; try { serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value()); } catch (ClassCastException cce) { throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() + " specified in value.serializer", cce); } int partition = partition(record, serializedKey, serializedValue, cluster);
第二步:追加写入消息缓冲区(accumulator)
producer创建时会创建一个默认32MB(buffer.memory指定)的accumulator缓冲区,专门保存待发送的消息。
accumulator的实现类是RecordAccumulator,我们看一下它的构造方法
public RecordAccumulator(LogContext logContext, int batchSize, long totalSize, CompressionType compression, long lingerMs, long retryBackoffMs, Metrics metrics, Time time, ApiVersions apiVersions, TransactionManager transactionManager) { this.log = logContext.logger(RecordAccumulator.class); this.drainIndex = 0; this.closed = false; this.flushesInProgress = new AtomicInteger(0); this.appendsInProgress = new AtomicInteger(0); this.batchSize = batchSize; this.compression = compression; this.lingerMs = lingerMs; this.retryBackoffMs = retryBackoffMs; this.batches = new CopyOnWriteMap<>(); String metricGrpName = "producer-metrics"; this.free = new BufferPool(totalSize, batchSize, metrics, time, metricGrpName); this.incomplete = new IncompleteBatches(); this.muted = new HashSet<>(); this.time = time; this.apiVersions = apiVersions; this.transactionManager = transactionManager; registerMetrics(metrics, metricGrpName); }
除了关键参数linger.ms和batch.size等,还有一个重要的集合消息:消息批次信息(batches),该集合本身的是一个hashMap,如下:
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
里面保存了每个topic分区下的batch队列,意思是前面所说的batches其实就是按照Topic-Partition进行分组的,这样发往不同分区的消息保存再对应分区下的batch队列中。
比如,假设消息M1、M2被发送到test的0分区但属于不同的batch,M3被发送到test的1分区,那么batches中包含的消息就是:{"test-0" -> [batch1, batch2], "test-1" -> [batch3]},可以看出,batches的key就是TopicPartition,而value就是所需发送的批次的队列。
单个topic分区下的batch队列中保存的是若干个消息批次,那么,上面队列中保存的每个ProducerBatch,其结构如下:
public final class ProducerBatch {
private enum FinalState { ABORTED, FAILED, SUCCEEDED } final long createdMs; final TopicPartition topicPartition; final ProduceRequestResult produceFuture; private final List<Thunk> thunks = new ArrayList<>(); // 保存消息回调逻辑的集合 private final MemoryRecordsBuilder recordsBuilder; // 负责执行追加写入操作 private final AtomicInteger attempts = new AtomicInteger(0); private final boolean isSplitBatch; private final AtomicReference<FinalState> finalState = new AtomicReference<>(null); int recordCount; // 每一批次的记录数 int maxRecordSize; // 每条记录的最大大小 private long lastAttemptMs; private long lastAppendTime; private long drainedMs; private String expiryErrorMessage; private boolean retry; private boolean reopened = false;
上面红色的为Batch中的重要组件。
第二步的目的就是将待发的信息写入消息缓冲池,具体流程就是:
(1)调用RecordAccumulator.append()方法
(2)调用ProducerBatch.tryAppend() 方法
(3)在ProducerBatch中调用MemoryRecordsBuilder.append方法,并且将回调结果放入thunks。
这一步执行完毕之后,send方法也执行完毕,主线程会等待回调结果。
代码:
在KafkaProducer的doSend() 方法中,序列化并计算partition以后,进行accumulator.append()操作:
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
Accumulator.append() 方法:
public RecordAppendResult append(TopicPartition tp, long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long maxTimeToBlock) throws InterruptedException { // We keep track of the number of appending thread to make sure we do not miss batches in // abortIncompleteBatches(). appendsInProgress.incrementAndGet();
// 这个buffer就用来保存一个batch的消息的 ByteBuffer buffer = null; if (headers == null) headers = Record.EMPTY_HEADERS; try { // check if we have an in-progress batch Deque<ProducerBatch> dq = getOrCreateDeque(tp); // 如果topic-partition对应的dequeue已经存在的话,直接调用tryAppend方法进行append操作 synchronized (dq) { if (closed) throw new IllegalStateException("Cannot send after the producer is closed."); RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq); if (appendResult != null) return appendResult; } // 下面的情况是,top-partition对应的deque是空的,需要创建一个新的batch加入进去 byte maxUsableMagic = apiVersions.maxUsableProduceMagic(); // 获取缓冲区大小 int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers)); log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition()); // 为topic-partition分配一个缓冲区,用于临时存放要发送的消息 buffer = free.allocate(size, maxTimeToBlock); synchronized (dq) { // Need to check if producer is closed again after grabbing the dequeue lock. if (closed) throw new IllegalStateException("Cannot send after the producer is closed."); // 如果dq是空的,还是会继续走下去,不会返回,这里是并发状态下的再次判断 RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq); if (appendResult != null) { // Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often... return appendResult; } // 创建一个MemoryRecordsBuilder,负责执行追加写入操作 MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic); // 创建一个新的Batch,存放本批次的消息 ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds()); // 调用batch.tryAppend()方法,把本次的消息加入 FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds())); // 把batch加入队列 dq.addLast(batch); incomplete.add(batch); // Don't deallocate this buffer in the finally block as it's being used in the record batch buffer = null; // 返回结果 return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true); } } finally { if (buffer != null) free.deallocate(buffer); appendsInProgress.decrementAndGet(); } }
ProducerBatch的tryAppend()方法:
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) { if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) { return null; } else { // 调用了MemoryRecordsBuilder.append()方法 Long checksum = this.recordsBuilder.append(timestamp, key, value, headers); this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(), recordsBuilder.compressionType(), key, value, headers)); this.lastAppendTime = now; FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount, timestamp, checksum, key == null ? -1 : key.length, value == null ? -1 : value.length); // we have to keep every future returned to the users in case the batch needs to be // split to several new batches and resent. // 回调的结果存进thunks thunks.add(new Thunk(callback, future)); this.recordCount++; return future; } }
MemoryRecordsBuilder最后会调用这两个方法之一,把消息写入到缓冲区,其中recordWritten()方法里面是处理位移的逻辑
private void appendDefaultRecord(long offset, long timestamp, ByteBuffer key, ByteBuffer value, Header[] headers) throws IOException { ensureOpenForRecordAppend(); int offsetDelta = (int) (offset - baseOffset); long timestampDelta = timestamp - firstTimestamp; int sizeInBytes = DefaultRecord.writeTo(appendStream, offsetDelta, timestampDelta, key, value, headers); recordWritten(offset, timestamp, sizeInBytes); } private long appendLegacyRecord(long offset, long timestamp, ByteBuffer key, ByteBuffer value) throws IOException { ensureOpenForRecordAppend(); if (compressionType == CompressionType.NONE && timestampType == TimestampType.LOG_APPEND_TIME) timestamp = logAppendTime; int size = LegacyRecord.recordSize(magic, key, value); AbstractLegacyRecordBatch.writeHeader(appendStream, toInnerOffset(offset), size); if (timestampType == TimestampType.LOG_APPEND_TIME) timestamp = logAppendTime; long crc = LegacyRecord.write(appendStream, magic, timestamp, key, value, CompressionType.NONE, timestampType); recordWritten(offset, timestamp, size + Records.LOG_OVERHEAD); return crc; }
第三步:Sender线程预处理及消息发送
严格来说,Sender线程自KafkaProducer创建以后就一直都在运行,它的基本工作流程如下:
(1)不断轮询缓冲区已经做好发送准备的分区
(2)将轮询获得的各个batch按照目标分区所在的leader broker 进行分组
(3)将分组后的batch通过底层创建Socket连接发送给各个broker
(4)等待服务端response回来
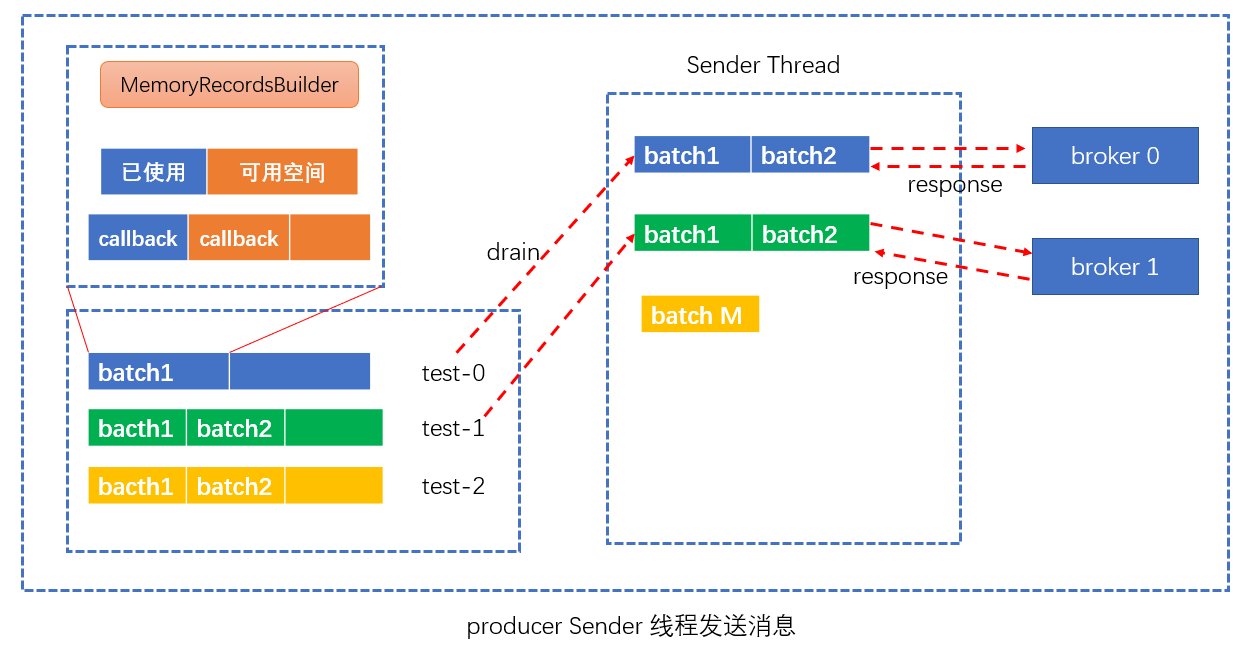
代码:
在Sender.sendProducerData()方法中,有这么一段:
// create produce requests Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now); if (guaranteeMessageOrder) { // Mute all the partitions drained for (List<ProducerBatch> batchList : batches.values()) { for (ProducerBatch batch : batchList) this.accumulator.mutePartition(batch.topicPartition); } }
// 最后按批次发送到各个broker节点
sendProduceRequests(batches, now);
通过accumulator.drain() 方法,获取所有 broker对应的batch: Map<Integer, List<ProducerBatch>> batches,其中key就是broker的ID,value就是发送到该broker的batch列表。
然后,在Sender.sendProduceRequests() 方法,遍历batches,按照 <broker:List<Batch>>发送:
private void sendProduceRequests(Map<Integer, List<ProducerBatch>> collated, long now) { for (Map.Entry<Integer, List<ProducerBatch>> entry : collated.entrySet()) sendProduceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue()); }
Sender.sendProduceRequest()方法:
/** * Create a produce request from the given record batches */ private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) { if (batches.isEmpty()) return; ...... String transactionalId = null; if (transactionManager != null && transactionManager.isTransactional()) { transactionalId = transactionManager.transactionalId(); } ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout, produceRecordsByPartition, transactionalId); // 这是一个回调处理逻辑 RequestCompletionHandler callback = new RequestCompletionHandler() { public void onComplete(ClientResponse response) { handleProduceResponse(response, recordsByPartition, time.milliseconds()); } }; String nodeId = Integer.toString(destination); // 封装一个发送请求 ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback); // 真正发送请求,底层用到了JavaNio的一些知识 client.send(clientRequest, now); log.trace("Sent produce request to {}: {}", nodeId, requestBuilder); }
第四步:Sender线程处理Response
broker处理完相应消息之后,会发送对应的PRODUCE response,一旦Sender线程接收到response,将依次调用batch中的回调方法,做完这一步,producer发送消息的工作就算完成了。
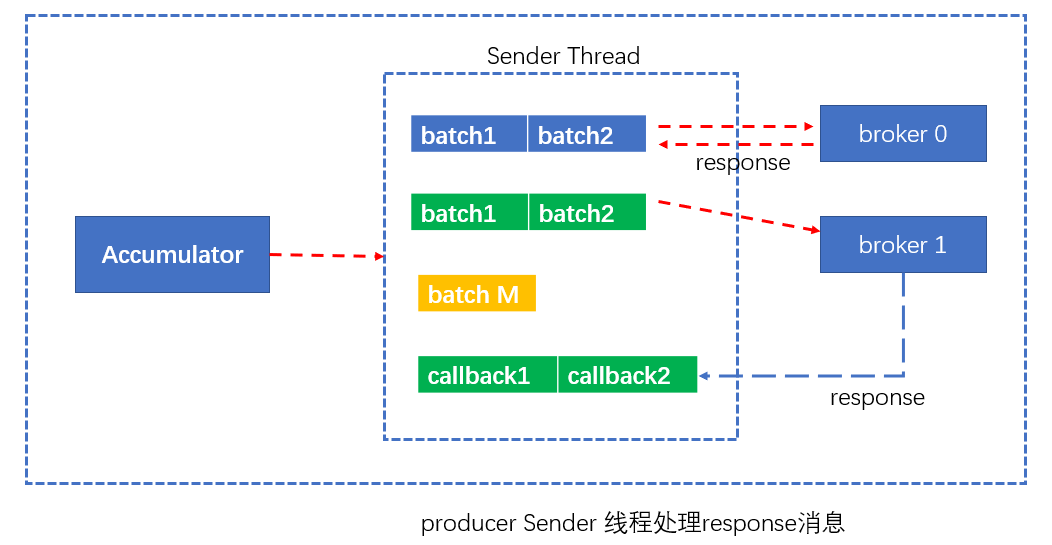
第三步的sendProduceRequest()方法中构建了一个resposneHander(红色代码):
RequestCompletionHandler callback = new RequestCompletionHandler() { public void onComplete(ClientResponse response) { handleProduceResponse(response, recordsByPartition, time.milliseconds()); } };
handleProduceResponse() 方法就封装了response的处理逻辑