一、目的
1、 掌握requests库和bs4库的使用方法;
2、 能熟练运用requests库和bs4库进行基本的数据爬取;
3、 掌握基于matplotlib库的数据可视化方法。
二、内容
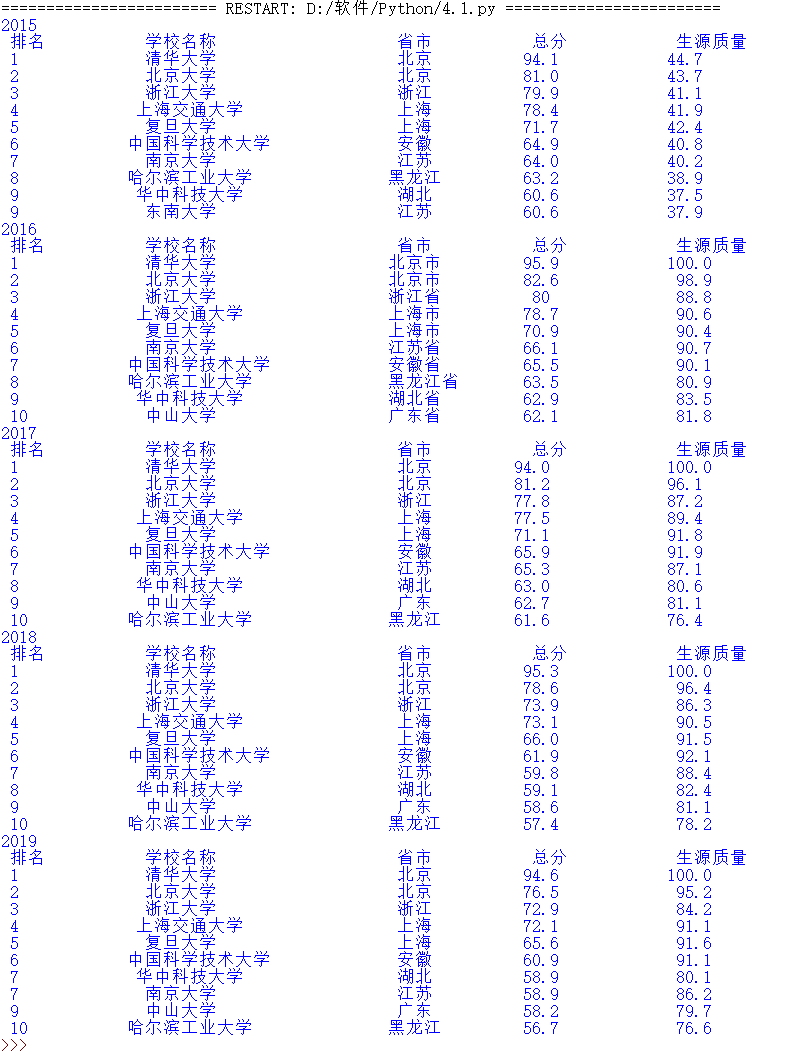
1、以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取,并按照排名先后顺序输出不同年份的前10位大学信息,要求对输出结果的排版进行优化。
代码:
1 import requests 2 from bs4 import BeautifulSoup 3 4 class Univ: 5 def __init__(self, url, num): 6 self.url=url 7 self.allUniv=[] 8 self.num=num 9 def get_htmltext(self): 10 try: 11 r=requests.get(self.url,timeout=30) 12 r.raise_for_status() 13 r.encoding='utf8' 14 return r.text 15 except: 16 return '' 17 def fillUnivList(self,soup): 18 data=soup.find_all('tr') 19 for tr in data: 20 ltd=tr.find_all('td') 21 if len(ltd)==0: 22 continue 23 singleUniv=[] 24 for td in ltd: 25 singleUniv.append(td.string) 26 self.allUniv.append(singleUniv) 27 def printUnivList(self): 28 print("{:^4} {:^20} {:^10} {:^8} {:^10} ".format("排名","学校名称","省市","总分","生源质量")) 29 for i in range(self.num): 30 u=self.allUniv[i] 31 if u[0]: 32 print("{:^4} {:^20} {:^10} {:^8} {:^10} ".format(u[0],u[1],u[2],u[3],u[4])) 33 else: 34 print("{:^4} {:^20} {:^10} {:^8} {:^10} ".format(i+1,u[1],u[2],u[3],u[4])) 35 def main(self): 36 html=self.get_htmltext() 37 soup=BeautifulSoup(html,'html.parser') 38 self.fillUnivList(soup) 39 self.printUnivList() 40 if __name__ == "__main__": 41 url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2015_0.html" 42 print('2015') 43 u=Univ(url,10) 44 u.main() 45 years=["2016","2017","2018","2019"] 46 for year in years: 47 url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming"+year+".html" 48 print(year) 49 u=Univ(url,10) 50 u.main()
运行结果:
2、豆瓣图书评论数据爬取。在豆瓣图书上自行选择一本书,编写程序爬取豆瓣图书上针对该图书的短评信息,要求:
(1)对不同页码的短评信息均可以进行爬取;
(2)爬取的数据包含用户名、短评内容、评论时间和评分;
(3)能够根据选择的排序方式进行爬取,并针对热门排序,输出前10个短评信息(包括用户名、短评内容、评论时间和评分);
(4)结合中文分词和词云生成,对前3页的短评内容进行文本分析,并生成一个属于自己的词云图形。
图书选取:生存还是毁灭作者: [南非] 大卫·贝纳塔
代码:
1 import requests 2 import re 3 import imageio 4 import jieba 5 import wordcloud 6 from bs4 import BeautifulSoup 7 from fake_useragent import UserAgent 8 class com: 9 def __init__(self, no,num,page): 10 self.no=no 11 self.page=page 12 self.num=num 13 self.url=None 14 self.header=None 15 self.bookdata=[] 16 self.txt='' 17 def set_header(self): 18 ua = UserAgent() 19 self.header={"User-Agent":ua.random} 20 def set_url(self,page): 21 self.url='https://book.douban.com/subject/{0}/comments/hot?p={1}'.format(str(self.no),str(page+1)) 22 def get_html(self): 23 try: 24 r=requests.get(self.url,headers=self.header,timeout=30) 25 r.raise_for_status() 26 r.encoding='utf8' 27 return r.text 28 except: 29 return '' 30 def fill_bookdata(self,soup): 31 commentinfo=soup.find_all('span','comment-info') 32 pat1=re.compile(r'allstar(d+) rating') 33 pat2=re.compile(r'<span>(dddd-dd-dd)</span>') 34 comments=soup.find_all('span','short') 35 for i in range(len(commentinfo)): 36 p=re.findall(pat1,str(commentinfo[i])) 37 t=re.findall(pat2,str(commentinfo[i])) 38 self.bookdata.append([commentinfo[i].a.string,comments[i].string,p,t[0]]) 39 def printList(self, num): 40 for i in range(num): 41 u=self.bookdata[i] 42 try: 43 print("序号: {} 用户名: {} 评论内容: {} 时间:{} 评分: {}星 ".format(i+1,u[0],u[1],u[3],int(eval(u[2][0])/10))) 44 except: 45 print("序号: {} 用户名: {} 评论内容: {} ".format(i+1,u[0],u[1])) 46 def comment(self): 47 self.set_header() 48 self.set_url(0) 49 html=self.get_html() 50 soup=BeautifulSoup(html,'html.parser') 51 self.fill_bookdata(soup) 52 self.printList(self.num) 53 def txtcloud(self): 54 self.set_header() 55 for i in range(self.page): 56 self.bookdata=[] 57 self.set_url(i) 58 html=self.get_html() 59 soup=BeautifulSoup(html,'html.parser') 60 self.fill_bookdata(soup) 61 for j in range(len(self.bookdata)): 62 self.txt+=self.bookdata[j][1] 63 image=imageio.imread("钻石.jpg") 64 w=wordcloud.WordCloud(width=1000,font_path="msyh.ttc",height=700, 65 mask=image,background_color="white") 66 w.generate(self.txt) 67 w.to_file("comment.png") 68 def main(self): 69 self.comment() 70 self.txtcloud() 71 if __name__ == "__main__": 72 com(35019783,10,10).main()
运行结果:

选取图片:

词云图片:

三、实验总结
通过本次实验,对Python有了更深一步的了解,能熟练掌握Python网络爬虫与数据处理,掌握了requests库和bs4库的使用方法;能熟练运用requests库和bs4库进行基本的数据爬取;掌握基于matplotlib库的数据可视化方法。