最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel。
- 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据
- 使用语言:python
- 工具:PyCharm
- 涉及库:requests、re、openpyxl(高版本excel操作库)
实现代码

# -*- coding: utf-8 -*- # @Author : yocichen # @Email : yocichen@126.com # @File : maoyan100.py # @Software: PyCharm # @Time : 2019 # @UpdateTime : 2020/4/26 import requests from requests import RequestException import re import openpyxl import traceback # Get page's html by requests module def get_one_page(url): try: headers = { 'user-agent': 'Mozilla / 5.0(Windows NT 10.0; WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 53.0.2785.104Safari / 537.36Core / 1.53.4882.400QQBrowser / 9.7.13059.400' } # Sometimes, the proxies need to be replaced. # You can get them by accessing https://www.kuaidaili.com/free/inha/ proxies = { 'http': '60.190.250.120:8080' } # use headers to avoid 403 Forbidden Error(reject spider) response = requests.get(url, headers=headers, proxies=proxies) if response.status_code == 200 : return response.text return None except RequestException: traceback.print_exc() return None # Get useful info from html of a page by re module def parse_one_page(html): try: pattern = re.compile('<dd>.*?board-index.*?>(d+)<.*?<a.*?title="(.*?)"' +'.*?data-src="(.*?)".*?</a>.*?star">[\s]*(.*?)[\n][\s]*</p>.*?' +'releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?' +'fraction">(.*?)</i>.*?</dd>', re.S) items = re.findall(pattern, html) return items except Exception: traceback.print_exc() return [] # Main call function def main(url): page_html = get_one_page(url) parse_res = parse_one_page(page_html) return parse_res # Write the useful info in excel(*.xlsx file) def write_excel_xlsx(items): wb = openpyxl.Workbook() ws = wb.active rows = len(items) cols = len(items[0]) # First, write col's title. ws.cell(1, 1).value = '编号' ws.cell(1, 2).value = '片名' ws.cell(1, 3).value = '宣传图片' ws.cell(1, 4).value = '主演' ws.cell(1, 5).value = '上映时间' ws.cell(1, 6).value = '评分' # Write film's info for i in range(0, rows): for j in range(0, cols): if j != 5: ws.cell(i+2, j+1).value = items[i][j] else: ws.cell(i+2, j+1).value = items[i][j]+items[i][j+1] break # Save the work book as *.xlsx wb.save('maoyan_top100.xlsx') if __name__ == '__main__': print('spider working...') res = [] url = 'https://maoyan.com/board/4?' for i in range(0, 10): if i == 0: res = main(url) else: newUrl = url+'offset='+str(i*10) res.extend(main(newUrl)) print('writing into excel...') write_excel_xlsx(res) print('work done! Note: the data is in the current directory.')
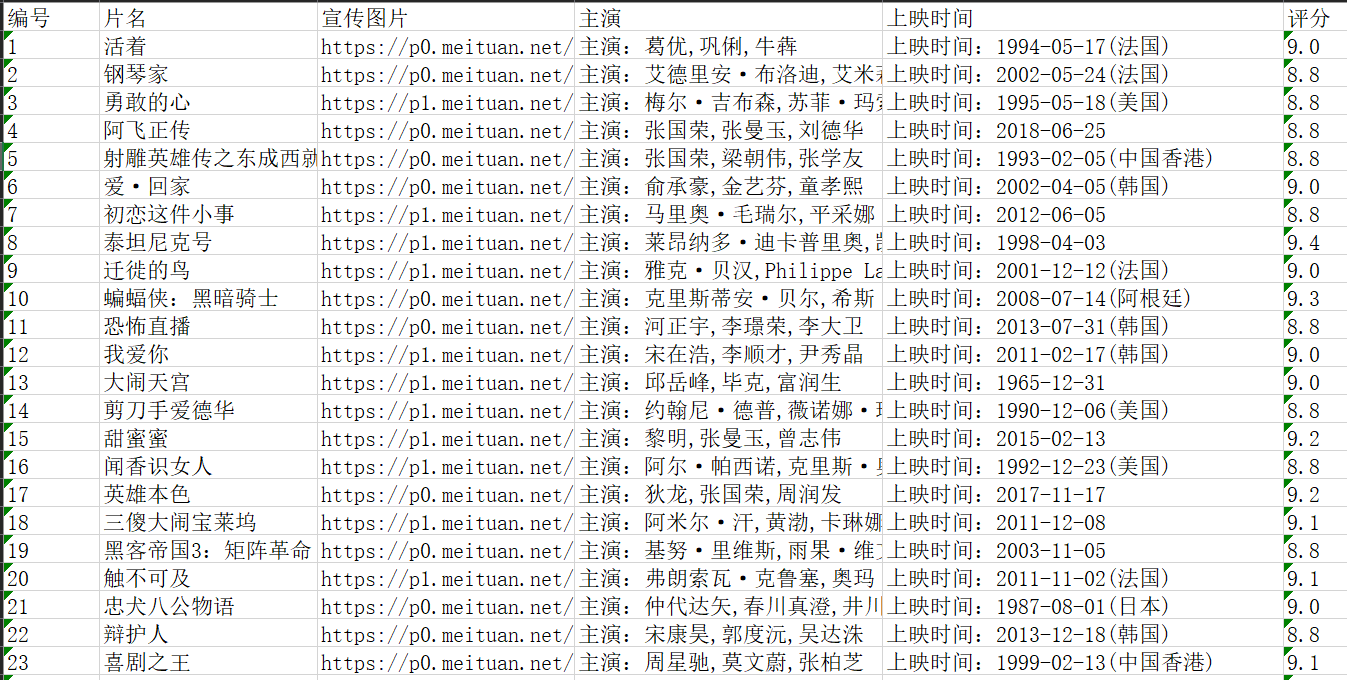
更新效果图:
后记
入门了一点后发现,如果使用正则表达式和requests库来实行进行数据爬取的话,分析HTML页面结构和正则表达式的构造是关键,剩下的工作不过是替换url罢了。
补充一个分析HTML构造正则的例子
审查元素我们会发现每一项都是<dd>****</dd>格式
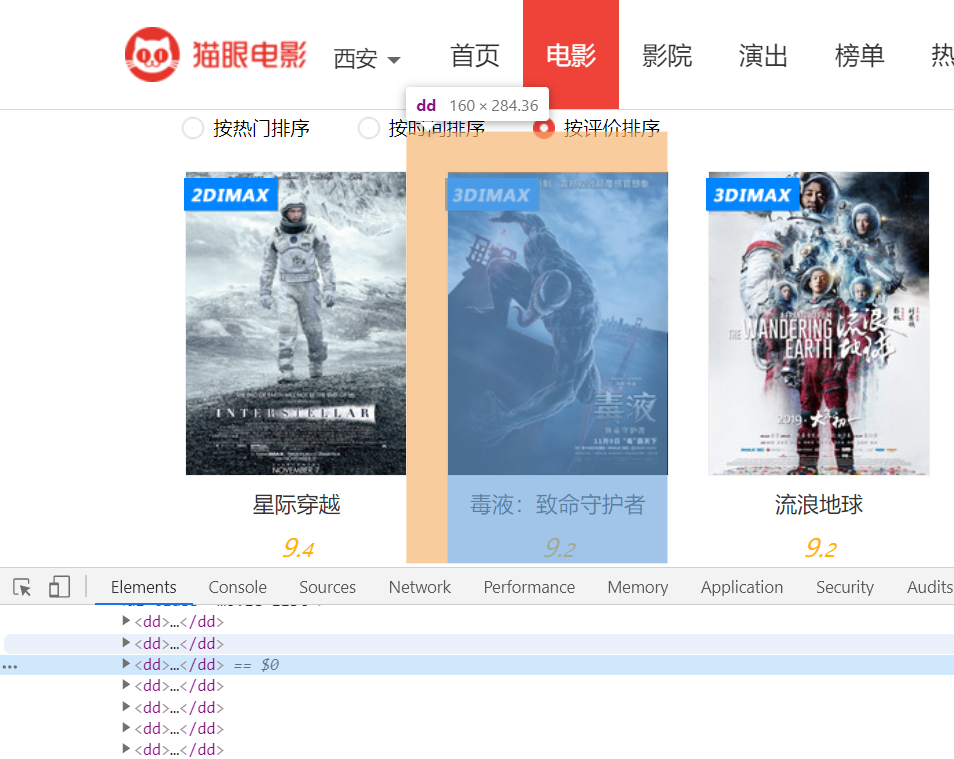
我想要获取电影名称和评分,先拿出HTML代码看一看

试着构造正则
'.*?<dd>.*?movie-item-title.*?title="(.*?)">.*?integer">(.*?)<.*?fraction">(.*?)<.*?</dd>' (随手写的,未经验证)
参考资料
【B站视频 2018年最新Python3.6网络爬虫实战】https://www.bilibili.com/video/av19057145/?p=14
【猫眼电影robots】https://maoyan.com/robots.txt (最好爬之前去看一下,那些可爬那些不允许爬)