6.1 SQL语句类别
- DDL:数据定义语言语句。这样的语句有CREATE、TRUNCATE和ALTER,它们用于建立数据库中的结构,设置许可等。用户可以使用它们维护Oracle数据词典。
- DML:数据操作语言语句。这些语句可以修改或者访问信息,包括INSERT、UPDATE和DELETE。
- 查询:这是用户的标准SELECT语句。查询是指那么返回数据但是不修改数据的语句,是DML语句的子集。
6.2 怎样执行语句
相对于查询和DML语句,DDL更像是Oracle的一个内部命令。它不是在一些表上生成的查询,而是完成一些工作的命令。例如,如果用户使用:
Create table t(x int primary key, y date);
然而有意思的是,CREATE TABLE语句也可以在其中包含SELECT。我们可以使用:
Create table t as select * from scott.emp;
就像DML可以包含查询一样,DDL也可以这样做。当DDL包含查询的时候,查询部分会像任何其它查询一样接受处理。Oracle执行这些语句的4个步骤,它们是:
- 解析
- 优化
- 行源生成
- 执行语句
对于DDL,通常实际上只会应用第一个和最后一个步骤,它将会解析语句,然后执行它。“优化”CREATE语句毫无意义(只有一种方法可以建立内容),也不需要建立一般的方案(建立表的过程众所周知,已经在Oracle中直接编码)。应该注意到,如果CREATE语句包含了查询,那么就会按照处理其它查询的方式处理这个查询——采用以上所有步骤。
6.2.1 解析
这是Oracle中任何语句处理过程的第一个步骤。解析(parsing)是将已经提交的语句分解,判定它是哪种类型的语句(查询、DML或者DDL),并且在其上执行各种检验操作。
解析过程会执行三个主要的功能:
- 语法检查。这个语句是正确表述的语句么?它符合SQL参考手册中记录的SQL语法么?它遵循SQL的所有规则么?
- 语义分析。这个语句是否正确参照了数据库中的对象,它所引用的表和列存在么?用户可以访问这些对象,并且具有适当的特权么?语句中有歧义么?。
- 检查共享池。这个语句是否已经被另外的会话处理?
以下便是语法错误:
SQL> select from where 2; select from where 2 * ERROR 位于第 1 行: ORA-00936: 缺少表达式
总而言之,如果赋予正确的对象和特权,语句就可以执行,那么用户就遇到了语义错误;如果语句不能够在任何环境下执行,那么用户就遇到了语法错误。
解析操作中的下一步是要查看我们正在解析的语句是否牵线 些会话处理过。如果处理过,那么我们就很幸运,因为它可能已经存储于共享池。在这种情况下,就可以执行软解析(soft parse),换句话说,可以避免优化和查询方案生成阶段,直接进入执行阶段。这将极大地缩短执行查询的过程。另一方面,如果我们必须对查询进行解析、优化和生成执行方案,那么就要执行所谓的硬解析(hard parse)。这种区别十分重要。当开发应用的时候,我们会希望有非常高的比例的查询进行软解析,以跳过优化/生成阶段,因为这些阶段非常占用CPU。如果我们必须硬解析大量的查询,那么系统就会运行得非常缓慢。
-
Oracle怎样使用共享池
正如我们已经看到的,当Oracle解析了查询,并且通过了语法和语义检查之后,就会查看SGA的共享池组件,来寻找是否有另外的会话已经处理过完全相同的查询。为此,当Oracle接收到我们的语句之后,就会对其进行散列处理。散列处理是获取原始SQL文本,将其发往一下函数,并且获取一个返回编号的过程。如果我们访问一些V$表,就可以实际看到这些V$表在Oracle中称为动态性能表(dynamic performance tables),服务器会在那里为我们存储一些有用的信息。
可能通过如下方式实现访问V$表:
为用户账号赋予SELECT_CATALOG_ROLE
使用另一个具有SELECT_CATALOG_ROLE的角色(例如DBA)
如果用户不能访问V$表以及V$SQL视图,那么用户就不能完成所有的“试验”,但是掌握所进行的处理非常容易。
试验:观察不同的散列值
(1) 首先,我们将要执行2个对大家来讲意图和目的都相同的查询:
SQL> select * from dual; D - X SQL> select * from DUAL; D - X
(2) 我们可以查询动态性能视图V$SQL来查看这些内容,它可以向我们展示刚才运行的2个查询的散列值:
SQL> select sql_text,hash_value from v$sql 2 where upper(sql_text)='SELECT * FROM DUAL'; SQL_TEXT ------------------------------------------------ HASH_VALUE ---------- select * from DUAL 1708540716 select * from dual 4035109885
通常不需要实际查看散列值,因为它们在Oracle内部使用。当生成了这些值之后,Oracle就会在共享池中进行搜索,寻找具有相同散列值的语句。然后将它找到的SQL_TEXT与用户提交的SQL语句进行比较,以确保共享池中的文本完全相同。这个比较步骤很重要,因为散列函数的特性之一就是2个不同的字符串也可能散列为相同的数字。
注意:
散列不是字符串到数字的唯一映射。
总结到目前为止我们所经历的解析过程,Oracle已经:
- 解析了查询
- 检查了语法
- 验证了语义
- 计算了散列值
- 找到了匹配
- 验证与我们的查询完全相同的查询(它引用了相同的对象)
在Oracle从解析步骤中返回,并且报告已经完成软解析之前,还要执行最后一项检查。最后的步骤就是要验证查询是否是在相同的环境中解析。环境是指能够影响查询方案生成的所有会话设置,例如SORT_AREA_SIZE或者OPTIMIZER_MODE。SORT_AREA_SIZE会通知Oracle,它可以在不使用磁盘存储临时结果的情况下,为排序数据提供多少内存。圈套的SORT_AREA_SIZE会生成与较小的设置不同的优化查询方案。例如,Oracle可以选择一个排序数据的方案,而不是使用索引读取数据的方案。OPTIMIZER_MODE可以通知Oracle实际使用的优化器。
SQL> alter session set OPTIMIZER_MODE=first_rows; 会话已更改。 SQL> select * from dual; D - X SQL> select sql_text,hash_value,parsing_user_id 2 from v$sql 3 where upper(sql_text)='SELECT * FROM DUAL' 4 / SQL_TEXT ------------------------------------------------- HASH_VALUE PARSING_USER_ID ---------- --------------- select * from DUAL 1708540716 5 select * from dual 4035109885 5 select * from dual 4035109885 5
这2个查询之间的区别是第一个查询使用默认的优化器(CHOOSE),刚才执行的查询是在FIRST_ROWS模式中解析。
SQL> select sql_text,hash_value,parsing_user_id,optimizer_mode 2 from v$sql 3 where upper(sql_text)='SELECT * FROM DUAL' 4 / SQL_TEXT -------------------------------------------------------------- HASH_VALUE PARSING_USER_ID OPTIMIZER_ ---------- --------------- ---------- select * from DUAL 1708540716 5 CHOOSE select * from dual 4035109885 5 CHOOSE select * from dual 4035109885 5 FIRST_ROWS
在这个阶段的最后,当Oracle完成了所有工作,并且找到了匹配查询,它就可以从解析过程中返回,并且报告已经进行了一个软解析。我们无法看到这个报告,因为它由Oracle在内部使用,来指出它现在完成了解析过程。如果没有找到匹配查询,就需要进行硬解析。
6.2.2 优化
当重用SQL的时候,可以路过这个步骤,但是每个特有的查询/DML语句都要至少实现一次优化。
优化器的工作表面上看起来简单,它的目标就是找到最好的执行用户查询的途径,尽可能地优化代码。尽管它的工作描述非常简单,但是实际上所完成的工作相当复杂。执行查询可能会有上千种的方式,它必须找到最优的方式。为了判断哪一种查询方案最适合:Oracle可能会使用2种优化器:
- 基于规则的优化器(Rule Based Optimizer,RBO)——这种优化器基于一组指出了执行查询的优选方法的静态规则集合来优化查询。这些规则直接编入了Oracle数据库的内核。RBO只会生成一种查询方案,即规则告诉它要生成的方案。
- 基于开销的优化器(Cost Based Optimizer,CBO)——这种优化器人基于所收集的被访问的实际数据的统计数据来优化查询。它在决定最优方案的时候,将会使用行数量、数据集大小等信息。CBO将会生成多个(可能上千个)可能的查询方案,解决查询的备选方式,并且为每个查询方案指定一个数量开销。具有最低开销的查询方案将会被采用。
OPTIMIZER_MODE是DBA能够在数据库的初始化文件中设定的系统设置。默认情况下,它的值为CHOOSE,这可以让Oracle选取它要使用的优化器(我们马上就会讨论进行这种选择的规则)。DBA可以选择覆盖这个默认值,将这个参数设置为:
- RULE:规定Oracle应该在可能情况下使用RBO。
- FIRST_ROWS:Oracle将要使用CBO,并且生成一个尽可能快地获取查询返回的第一行的查询方案。
- ALL_ROWS:Oracle将要使用CBO,并且生成一个尽可能快地获取查询所返回的最后一行(也就获得所有的行)的查询方案。
正如我们在上面看到的,可以通过ALTER SESSION命令在会话层次覆写这个参数。这对于开发者希望规定它们想要使用的优化器以及进行测试的应用都非常有用。
现在,继续讨论Oracle怎样选择所使用的优化器,及其时机。当如下条件为真的时候,Oracle就会使用CBO:
- 至少有一个查询所参考的对象存在统计数据,而且OPTIMIZER_MODE系统或者会话参数没有设置为RULE。
- 用户的OPTIMIZER_MODE系统/会话参数设置为RULE或者CHOOSE以外的值。
- 用户查询要访问需要CBO的对象,例如分区表或者索引组织表。
- 用户查询包含了RULE提示(hint)以外的其它合法提示。
- 用户使用了只有CBO才能够理解的特定的SQL结构,例如CONNECT BY。
目前,建议所有的应用都使用CBO。自从Oracle第一次发布就已经使用的RBO被认为是过时的查询优化方法,使用它的时候很多新特性都无法利用。例如,如果用户想要使用如下特性的时候,就不能够使用RBO:
- 分区表
- 位图索引
- 索引组织表
- 规则的细粒度审计
- 并行查询操作
- 基于函数的索引
CBO不像RBO那样容易理解。根据定义,RBO会遵循一组规则,所以非常容易预见结果。而CBO会使用统计数据来决定查询所使用的方案。
为了分析和展示这种方法,可以使用一个简单的救命。我们将会在SQL*Plus中,从SCOTT模式复制EMP和DEPT表,并且向这些表增加主键/外键。将会使用SQL*Plus产品中内嵌工具AUTOTRACE,比较RBO和CBO的方案。
试验:比较优化器
(1) 用户确保作为SCOTT以外的其它用户登录到数据库上,然后使用CREATE TABLE命令复制SCOTT.EMP和SCOTT.DEPT表:
SQL> create table emp 2 as 3 select * from scott.emp; 表已创建。 SQL> create table dept 2 as 3 select * from scott.dept; 表已创建。
(2) 向EMP和DEPT表增加主键
SQL> alter table emp 2 add constraint emp_pk primary key(empno); 表已更改。 SQL> alter table dept 2 add constraint dept_pk primary key(deptno); 表已更改。
(3) 添加从EMP到DEPT的外键
SQL> alter table emp 2 add constraint emp_fk_dept 3 foreign key(deptno) references dept; 表已更改。
(4) SQL*Plus中启用AUTOTRACE工具。我们正在使用的AUTOTRACE命令会向我们展示Oracle可以用来执行查询经过优化的查询方案(它不会实际执行查询):
SQL> set autotrace traceonly explain
如果启动失败,解决方法如下:
SQL> set autotrace traceonly explain SP2-0613: 无法验证 PLAN_TABLE 格式或实体 SP2-0611: 启用EXPLAIN报告时出错
解决方法:
1.以当前用户登录
SQL> connect zhyongfeng/zyf@YONGFENG as sysdba; 已连接。
2.运行utlxplain.sql(在windows的C:\oracle\ora92\rdbms\admin下),即创建PLAN_TABLE
SQL> rem SQL> rem $Header: utlxplan.sql 29-oct-2001.20:28:58 mzait Exp $ xplainpl.sql SQL> rem SQL> Rem Copyright (c) 1988, 2001, Oracle Corporation. All rights reserved. SQL> Rem NAME SQL> REM UTLXPLAN.SQL SQL> Rem FUNCTION SQL> Rem NOTES SQL> Rem MODIFIED SQL> Rem mzait 10/26/01 - add keys and filter predicates to the plan table SQL> Rem ddas 05/05/00 - increase length of options column SQL> Rem ddas 04/17/00 - add CPU, I/O cost, temp_space columns SQL> Rem mzait 02/19/98 - add distribution method column SQL> Rem ddas 05/17/96 - change search_columns to number SQL> Rem achaudhr 07/23/95 - PTI: Add columns partition_{start, stop, id} SQL> Rem glumpkin 08/25/94 - new optimizer fields SQL> Rem jcohen 11/05/93 - merge changes from branch 1.1.710.1 - 9/24 SQL> Rem jcohen 09/24/93 - #163783 add optimizer column SQL> Rem glumpkin 10/25/92 - Renamed from XPLAINPL.SQL SQL> Rem jcohen 05/22/92 - #79645 - set node width to 128 (M_XDBI in gendef) SQL> Rem rlim 04/29/91 - change char to varchar2 SQL> Rem Peeler 10/19/88 - Creation SQL> Rem SQL> Rem This is the format for the table that is used by the EXPLAIN PLAN SQL> Rem statement. The explain statement requires the presence of this SQL> Rem table in order to store the descriptions of the row sources. SQL> SQL> create table PLAN_TABLE ( 2 statement_id varchar2(30), 3 timestamp date, 4 remarks varchar2(80), 5 operation varchar2(30), 6 options varchar2(255), 7 object_node varchar2(128), 8 object_owner varchar2(30), 9 object_name varchar2(30), 10 object_instance numeric, 11 object_type varchar2(30), 12 optimizer varchar2(255), 13 search_columns number, 14 id numeric, 15 parent_id numeric, 16 position numeric, 17 cost numeric, 18 cardinality numeric, 19 bytes numeric, 20 other_tag varchar2(255), 21 partition_start varchar2(255), 22 partition_stop varchar2(255), 23 partition_id numeric, 24 other long, 25 distribution varchar2(30), 26 cpu_cost numeric, 27 io_cost numeric, 28 temp_space numeric, 29 access_predicates varchar2(4000), 30 filter_predicates varchar2(4000));
3.将plustrace赋给用户(因为是当前用户,所以这步可省略)
SQL> grant all on plan_table to zhyongfeng; 授权成功。
4.通过执行plustrce.sql(C:\oracle\ora92\sqlplus\admin\ plustrce.sql),如下
SQL> @C:\oracle\ora92\sqlplus\admin\plustrce.sql;
会有以下结果:
SQL> create role plustrace; 角色已创建 SQL> SQL> grant select on v_$sesstat to plustrace; 授权成功。 SQL> grant select on v_$statname to plustrace; 授权成功。 SQL> grant select on v_$session to plustrace; 授权成功。 SQL> grant plustrace to dba with admin option; 授权成功。 SQL> SQL> set echo off
5.授权plustrace到用户(因为是当前用户,这步也可以省略)
SQL> grant plustrace to zhyongfeng; 授权成功。
(5) 启用了AUTORACE,在我们的表上运行查询:
SQL> set autotrace on; SQL> set autotrace traceonly explain; SQL> select * from emp,dept 2 where emp.deptno=dept.deptno; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 NESTED LOOPS 2 1 TABLE ACCESS (FULL) OF 'EMP' 3 1 TABLE ACCESS (BY INDEX ROWID) OF 'DEPT' 4 3 INDEX (UNIQUE SCAN) OF 'DEPT_PK' (UNIQUE)
由于没有收集任何统计信息(这是新建立的表),所以我们当前在这个例子中要使用RBO;我们无法访问任何需要CBO的特殊对象,我们的优化器目标要设置为CHOOSE。我们也能够从输出中表明我们正在使用RBO。在这里,RBO优化器会选择一个将要在EMP表上进行FULL SCAN的方案。为了执行连接,对于在EMP表中找到的每一行,它都会获取DEPTNO字段,然后使用DEPT_PK索引寻找与这个DEPTNO相匹配的DEPT记录。
如果我们简单分析已有的表(目前它实际上非常小),就会发现通过使用CBO,将会获得一个非常不同的方案。
注意:
设置Autotrace的命令
|
序号 |
列名 |
解释 |
|
1 |
SET AUTOTRACE OFF |
此为默认值,即关闭Autotrace |
|
2 |
SET AUTOTRACE ON |
产生结果集和解释计划并列出统计 |
|
3 |
SET AUTOTRACE ON EXPLAIN |
显示结果集和解释计划不显示统计 |
|
4 |
SETAUTOTRACE TRACEONLY |
显示解释计划和统计,尽管执行该语句,但您将看不到结果集 |
|
5 |
SET AUTOTRACE TRACEONLY STATISTICS |
只显示统计 |
Autotrace执行计划的各列的涵义
|
序号 |
列名 |
解释 |
|
1 |
ID_PLUS_EXP |
每一步骤的行号 |
|
2 |
PARENT_ID_PLUS_EXP |
每一步的Parent的级别号 |
|
3 |
PLAN_PLUS_EXP |
实际的每步 |
|
4 |
OBJECT_NODE_PLUS_EXP |
Dblink或并行查询时才会用到 |
AUTOTRACE Statistics常用列解释
|
序号 |
列名 |
解释 |
|
1 |
db block gets |
从buffer cache中读取的block的数量 |
|
2 |
consistent gets |
从buffer cache中读取的undo数据的block的数量 |
|
3 |
physical reads |
从磁盘读取的block的数量 |
|
4 |
redo size |
DML生成的redo的大小 |
|
5 |
sorts (memory) |
在内存执行的排序量 |
|
6 |
sorts (disk) |
在磁盘上执行的排序量 |
(6) ANALYZE通常是由DBA使用的命令,可以收集与我们的表和索引有关的统计值——它需要被运行,以便CBO能够具有一些可以参照的统计消息。我们现在来使用它:
SQL> analyze table emp compute statistics; 表已分析。 SQL> analyze table dept compute statistics; 表已分析。
(7) 现在,我们的表已经进行了分析,将要重新运行查询,查看Oracle这次使用的查询方案:
SQL> select * from emp,dept 2 where emp.deptno=dept.deptno; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=5 Card=14 Bytes=700) 1 0 HASH JOIN (Cost=5 Card=14 Bytes=700) 2 1 TABLE ACCESS (FULL) OF 'DEPT' (Cost=2 Card=5 Bytes=90) 3 1 TABLE ACCESS (FULL) OF 'EMP' (Cost=2 Card=14 Bytes=448)
在这里,CBO决定在2个表进行FULL SCAN(读取整个表),并且HASH JOIN它们。这主要是因为:
- 我们最终要访问2个表中的所有行
- 表很小
- 在小表中通过索引访问每一行(如上)要比完全搜索它们慢
工作原理
CBO在决定方案的时候会考虑对象的规模。从RBO和CBO的AUTOTRACE输出中可以发现一个有意思的现象是,CBO方案包含了更多的信息。在CBO生成的方案中,将会看到的内容有:
- COST——赋予这个步骤的查询方案的数量值。它是CBO比较相同查询的多个备选方案的相对开销,寻找具有最低整体开销的方案时所使用的内部数值。
- CARD——这个步骤的核心数据,换句话说,就是这个步骤将要生成的行的估计数量。例如,可以发现DEPT的TABLE ACCESS(FULL)估计要返回4条记录,因为DEPT表只有4条记录,所以这个结果很正确。
- BYTES——方案中的这个步骤气概生成的数据的字节数量。这是附属列集合的平均行大小乘以估计的行数。
用户将会注意到,当使用RBO的时候,我们无法看到这个信息,因此这是一种查看所使用优化器的方法。
如果我们“欺骗”CBO,使其认为这些表比它们实际的要大,就可以得到不同的规模和当前统计信息。
试验:比较优化器2
为了完成这个试验,我们将要使用称为DBMS_STATS的补充程序包。通过使用这个程序包,就可以在表上设置任意统计(可能要完成一些测试工作,分析各种环境下的生成方案)。
(1) 我们使用DBMS_STATS来欺骗CBO,使其认为EMP表具有1000万条记录,DEPT表具有100万条记录:
SQL> begin 2 dbms_stats.set_table_stats 3 (user,'EMP',numrows=>10000000,numblks=>1000000); 4 dbms_stats.set_table_stats 5 (user,'DEPT',numrows=>1000000,numblks=>100000); 6 end; 7 / PL/SQL 过程已成功完成。
(2) 我们将要执行与前面完全相同的查询,查看新统计信息的结果:
SQL> select * from emp,dept 2 where emp.deptno=dept.deptno; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=79185 Card=200000000 0000 Bytes=100000000000000) 1 0 HASH JOIN (Cost=79185 Card=2000000000000 Bytes=10000000000 0000) 2 1 TABLE ACCESS (FULL) OF 'DEPT' (Cost=6096 Card=1000000 By tes=18000000) 3 1 TABLE ACCESS (FULL) OF 'EMP' (Cost=60944 Card=10000000 B ytes=320000000)
用户可以发现,优化器选择了完全不同于以前的方案。它不再散列这些明显很大的表,而是会MERGE(合并)它们。对于较小的DEPT表,它将会使用索引排序数据,由于在EMP表的DEPTNO列上没有索引,为了将结果合并在一起,要通过DEPTNO排序整个EMP。
(3) 如果将OPTIMIZER_MODE参数设置为RULE,就可以强制使用RBO(即使我们有这些统计数据),可以发现它的行为是完全可以预期的:
SQL> alter session set OPTIMIZER_MODE=RULE; 会话已更改。 SQL> select * from emp,dept 2 where emp.deptno=dept.deptno; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=RULE 1 0 NESTED LOOPS 2 1 TABLE ACCESS (FULL) OF 'EMP' 3 1 TABLE ACCESS (BY INDEX ROWID) OF 'DEPT' 4 3 INDEX (UNIQUE SCAN) OF 'DEPT_PK' (UNIQUE)
注意:
无论附属表中的数据数量如何,如果给定相同的数据对象集合(表和索引),RBO每次都会生成完全相同的方案。
6.2.3 行源生成器
行源生成器是Oracle的软件片段,它可以从优化器获取输出,并且将其格式化为的执行方案。例如,在这部分之前我们看到了SQL*Plus中的AUTOTRACE工具所生成的查询方案。那个树状结构的方案就是行源生成器的输出;优化器会生成方案,而行源生成器会将其转换成为Oracle系统的其余部分可以使用的数据结构。
6.2.4 执行引擎
执行引擎(execution engine)是获取行源生成器的输出,并且使用它生成结果集或者对表进行修改的进程。例如,通过使用以上最后生成的AUTOTRACE方案,执行引擎就可以读取整个EMP表。它会通过执行INDEX UNIQUE SCAN读取各行,在这个步骤中,Oracle会在DEPT_PK索引上搜索UNIQUE索引找到特定值。然后使用它所返回的值去寻找特定DEPTNO的ROWID(包含文件、数据文件、以及数据块片段的地址,可以利用这个地址找到数据行)。然后它就可以通过ROWID访问DEPT表。
执行引擎是整个进程的骨干,它是实际执行所生成的查询方案的部分。它会执行I/O,读取数据、排序数据、连接数据以及在需要的时候在临时表中存储数据。
6.2.5 语句执行汇总
在语句执行部分中,我们已经分析了为了进程处理,用户提交给Oracle的语句气概经历的4个阶段。图6-1是汇总这个流程的流程图:

图6-1 语句处理过程流图
当向Oracle提交SQL语句的时候,解析器就要确定它是需要进行硬解析还是软解析。
如果语句要进行软解析,就可以直接进行SQL执行步骤,获得输出。
如果语句必须要进行硬解析,就需要将其发往优化器,它可以使用RBO或者CBO处理查询。当优化器生成它认为的最优方案之后,就会将方案转递给行源生成器。
行源生成器会将优化器的结果转换为Oracle系统其余部分能够处理的格式,也就是说,能够存储在共享池中,并且被执行的可重复使用的方案。这个方案可以由SQL引擎使用,处理查询并且生成答案(也就是输出)。
6.3 查询全过程
现在,我们来讨论Oracle处理查询的全过程。为了展示Oracle实现查询过程的方式,我们将要讨论2个非常简单,但是完全不同的查询。我们的示例要着重于开发者经常会问及的一个普通问题,也就是说:“从我的查询中将会返回多少行数据?”答案很简单,但是通常直到用户实际获取了最后一行数据,Oracle才知道返回了多少行。为了更好理解,我们将会讨论获取离最后一行很远的数据行的查询,以及一个必须等待许多(或者所有)行已经处理之后,可以返回记录的查询。
对于这个讨论,我们将要使用2个查询:
SELECT * FROM ONE_MILLION_ROW_TABLE;
以及
SELECT * FROM ONE_MILLION_ROW_TABLE ORDER BY C1;
在这里,假定ONE_MILLION_ROW_TABLE是我们放入了100行的表,并且在这个表上没有索引,它没有采用任何方式排序,所以我们第二个查询中的ORDYER BY要有很多工作去做。
第一个查询SELECT * FROM ONE_MILLION_ROW_TABLE将会生成一个非常简单的方案,它只有一个步骤:
TABLE ACCESS(FULL) OF ONE_MILLION_ROW_TABLE
这就是说Oracle将要访问数据库,从磁盘或者缓存读取表的所有数据块。在掌击的环境中(没有并行查询,没有表分区),将会按照从第一个盘区到它的最后一个盘区读取表。幸运的是,我们立即就可以从这个查询中获取返回数据。只要Oracle能够读取信息,我们的客户应用就可以获取数据行。这就是我们不能在获得最后一行之前,确定查询将会返回多少行的原因之一—甚至Oracle也不知道要返回多少行。当Oracle开始处理这个查询的时候,它所知道的就是构成这个表的盘区,它并不知道这些盘区中的实际行数(它能够基于统计进行猜测,但是它不知道)。在这里,我们不必等待最后一行接受处理,就可以获取第一行,因此我们只有实际完成之后才能够精确的行数量。
第二个查询会有一些不同。在大多数环境中,它都会分为2个步骤进行。首先是一个ONE_MILLION_ROW_TABLE的TABLE ACCESS(FULL)步骤,它人将结果反馈到SORT(ORDER BY)步骤(通过列C1排序数据库)。在这里,我们将要等候一段时间才可以获得第一行,因为在获取数据行之前必须要读取、处理并且排序所有的100万行。所以这一次我们不能很快获得第一行,而是要等待所有的行都被处理之后才行,结果可能要存储在数据库中的一些临时段中(根据我们的SORT_AREA_SIZE系统/会话参数)。当我们要获取结果时,它们将会来自于这些临时空间。
总而言之,如果给定查询约束,Oracle就会尽可能快地返回答案。在以上的示例中,如果在C1上有索引,而且C1定义为NOT NULL,那么Oracle就可以使用这个索引读取表(不必进行排序)。这就可以尽可能快地响应我们的查询,为我们提供第一行。然后,使用这种过程获得最后一行就比较慢,因为从索引中读取100万行会相当慢(FULL SCAN和SORT可能会更有效率)。所以,所选方案会依赖于所使用的优化器(如果存在索引,RBO总会倾向于选择使用索引)和优化目标。例如,运行在默认模式CHOOSE中,或者使用ALL_ROWS模式的CBO将使用完全搜索和排序,而运行于FIRST_ROWS优化模式的CBO将可能要使用索引。
6.4 DML全过程
现在,我们要讨论怎样处理修改的数据库的DML语句。我们将要讨论怎样生成REDO和UNDO,以及怎样将它们用于DML事务处理及其恢复。
作为示例,我们将会分析如下事务处理会出现的情况:
INSERT INTO T(X,Y) VALUES (1,1); UPDATE T SET X=X+1 WHERE X=1; DELETE FROM T WHERE X=2;
最初对T进行的插入将会生成REDO和UNDO。如果需要,为了对ROLLBACK语句或者故障进行响应,所生成的UNDO数据将会提供足够的信息让INSERT“消失”。如果由于系统故障要再次进行操作,那么所生成的UNDO数据将会为插入“再次发生”提供足够的信息。UNDO数据可能会包含许多信息。
所以,在我们执行了以上的INSERT语句之后(还没有进行UPDATE或者DELETE)。我们就会拥有一个如图6-2所示的状态。
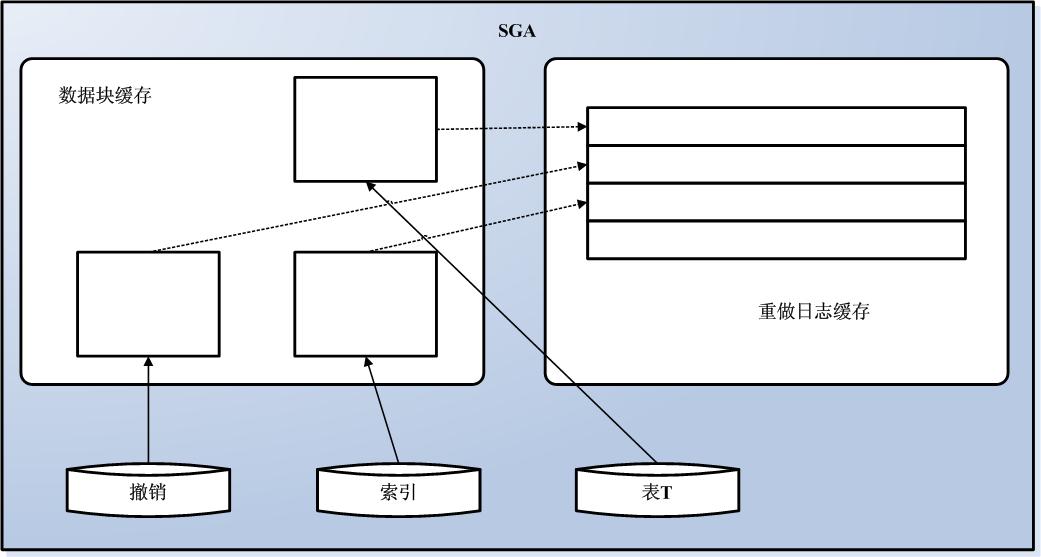
图6-2 执行INSERT语句之后的状态
这里有一些已经缓存的,经过修改的UNDO(回滚)数据块、索引块,以及表数据块。所有这些都存储在数据块缓存中。所有这些经过修改的数据块都会由重做日志缓存中的表项保护。所有这些信息现在都受到缓存。
现在来考虑一个在这个阶段出现系统崩溃的场景。SGA会受到清理,但是我们实际上没有使用这里列举的项,所以当我们臭不可闻启动的时候,就好像这个事务处理过程从来没有发生过样。所有发生改变的数据块都没有写入磁盘,REDO信息也没有写入磁盘。
在另一个场景中,缓存可能已经填满。在这种情况下,DBWR必须要腾出空间,清理我们已经改变的数据块。为了完成这项工作,DBWR首先会要求LGWR清理保护数据库数据块的REDO块。
注意:
在DBWR将已经改变的数据块定稿磁盘之前,LGWR必须清理与这些数据块相关联的REDO信息。
在我们的处理过程中,这时要清理重做日志缓存(Oracle会反复清理这个缓存),缓存中的一些改变也要写入磁盘。在这种情况下,即如图6-3所示。
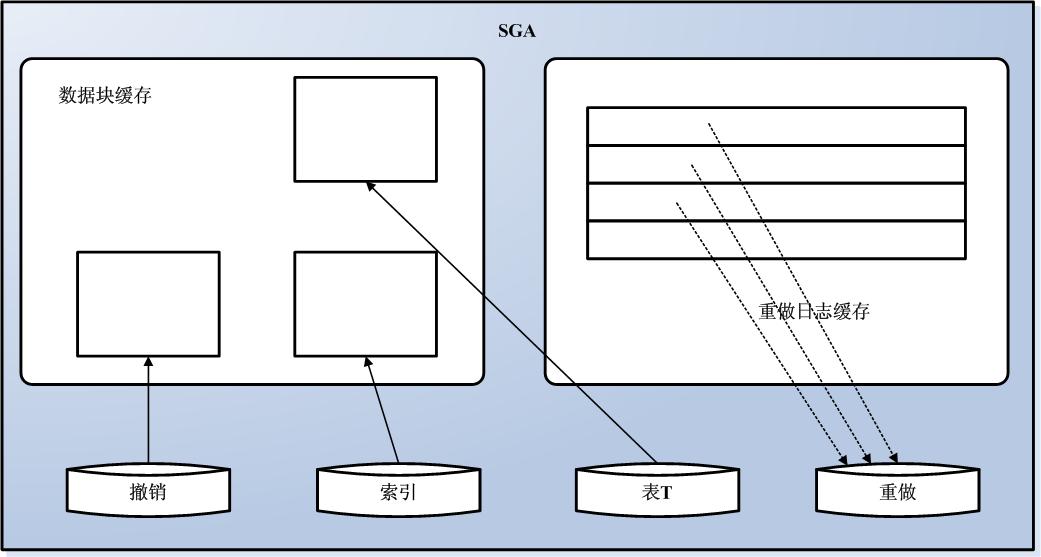
图6-3 清理重做日志缓存的状态
接下来,我们要进行UPDATE。这会进行大体相同的操作。这一次,UNDO的数据将会更大,我们会得到图6-4所示情况。
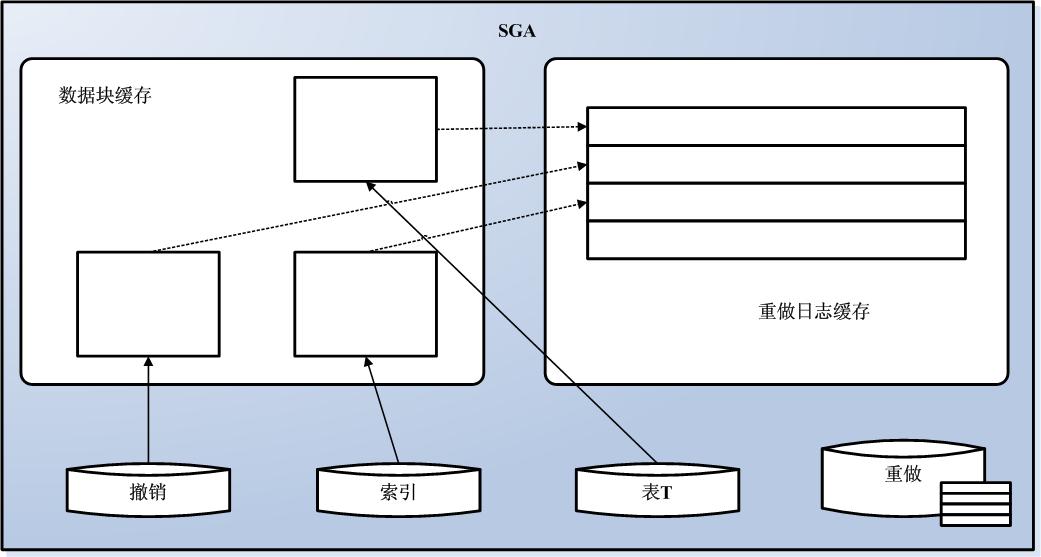
图6-4 UPDATE图示
我们已经将更多的新UNDO数据块增加到了缓存中。已经修改了数据库表和索引数据块,所以我们要能够在需要的时候UNDO(撤销)已经进行的UPDATE。我们还生成了更多的重做日志缓存表项。到目前为止,已经生成的一些重做日志表项已经存入了磁盘,还有一些保留在缓存中。
现在,继续DELETE。这里会发生大体相同的情况。生成UNDO,修改数据块,将REDO发往重做日志缓存。事实上,它与UPDATE非常相似,我们要对其进行COMMIT,在这里,Oracle会将重做日志缓存清理到磁盘上,如图6-5所示。
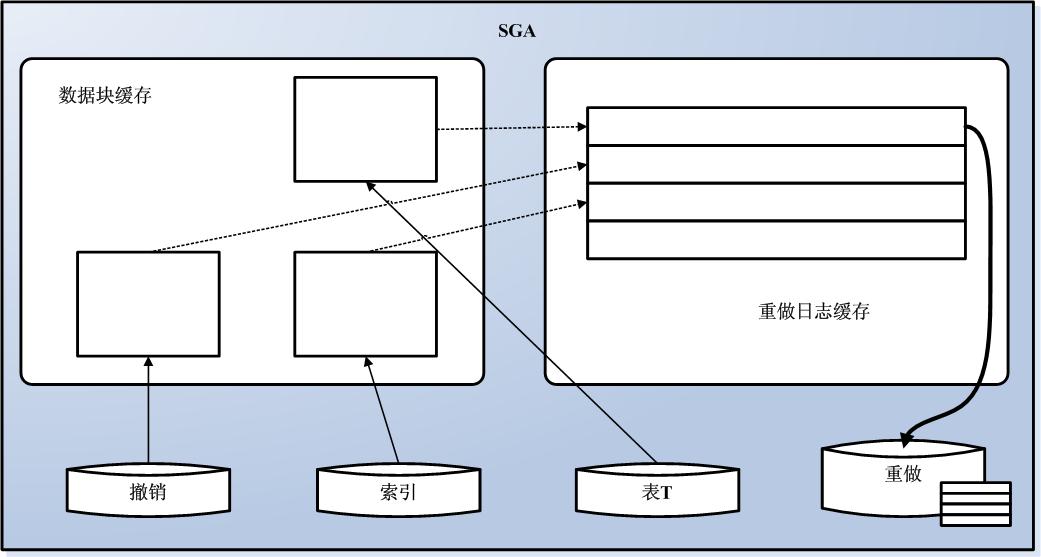
图6-5 DELETE操作后图示
有一些已经修改的数据块保留在缓存中,还有一些可能会被清理到磁盘上。所有可以重放这个事务处理的REDO信息都会安全地放在磁盘上,现在改变已永久生效。
6.5 DDL处理
最后,我们来讨论Oracle怎样处理DDL。DDL是用户修改Oracle数据词典的方式。为了建立表,用户不能编写INSERT INTO USER_TABLES语句,而是要使用CREATE TABLE语句。在后台,Oracle会为用户使用大量的SQL(称为递归SQL,这些SQL会对其它SQL产生副作用)。
执行DDL活动将会在DDL执行之前发出一个COMMIT,并且在随后立即使用一个COMMIT或者ROLLBACK。这就是说,DDL会像如下伪码一样执行:
COMMIT; DDL-STATEMENT; IF (ERROR) THEN ROLLBACK; ELSE COMMIT; END IF;
用户必须注意,COMMIT将要提交用户已经处理的重要工作——即,如果用户执行:
INSERT INTO SOME_TABLE VALUES(‘BEFORE’); CREATE TABLE T(X INT ); INSERT INTO SOME_TABLE VALUES(‘AFTER’); ROLLBACK;
由于第一个INSERT已经在Oracle尝试CREATE TABLE语句之前进行了提交,所以只有插入AFTER的行会进行回滚。即使CREATE TABLE失败,所进行的BEFORE插入也会提交。
6.6 小结
- Oracle怎样解析查询、从语法和语义上验证它的正确性。
- 软解析和硬解析。在硬解析情况下,我们讨论了处理语句所需的附加步骤,也就是说,优化和行源生成。
- Oracle优化器以及它的2种模式RULE和COST。
- 用户能够怎样在SQL*Plus中使用AUTOTRACE查看所使用的优化器模式。
- Oracle怎样使用REDO和UNDO提供故障保护。
文章根据自己理解浓缩,仅供参考。
摘自:《Oracle编程入门经典》 清华大学出版社 http://www.tup.com.cn/
