信息论基础
信息
i(x) = -log(p(x))
如果说概率p是对确定性的度量
那么信息就是对不确定性的度量
独立事件的信息
如果两个事件X和Y独立,即p(xy)=p(x)p(y) ,假定X和y的信息量分别为i(x)和i(y),则二者同时发生的信息量应该为i(x^y)=i(x)+i(y)
熵:自信息的期望
熵是对平均不确定性的度量

对熵的理解:
熵是随机变量不确定性的度量,不确定性越大,熵值越大;若随机变量退化为定值,熵为0.
该不确定性度量的本质即为信息量的期望
均匀分布是“最不确定的”的分布
熵其实定义了一个函数(概率分布函数)到一个值(信息熵)的映射
对于一个两点分布的变量,其熵为:

对于一个三点分布的变量,其熵为:

他们的熵函数均是凸函数,同时我们可以发行这些熵函数也是交叉熵损失函数
互信息

可以理解为:
它度量知道这两个变量其中一个,对另一个不确定度减少的程度。
如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。
互信息是非负的,而且是对称的

先验分布:根据一般的经验认为随机变量应该满足的分布
后验分布:通过当前训练数据修正的随机变量的分布,比先验分布更符合当前数据
似然估计:已知训练数据,给定了模型,通过让似然性极大化估计模型参数的一种方法
后验分布往往是基于先验分布和极大似然估计计算出来的。
平均互信息
即互信息的期望
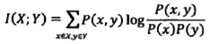
决策树中的信息增益其实就是平均互信息
条件熵:

联合熵:

平均互信息与联合熵、条件熵的关系

条件熵和平均互信息的关系

条件熵的另一种理解

相对熵(KL散度)
也是衡量两个概率分布的差异性
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异
即如果用P来描述目标问题,而不是用Q来描述目标问题,得到的信息增量。
在机器学习中,P往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q用来表示模型所预测的分布,比如[0.7,0.2,0.1]
直观的理解就是如果用P来描述样本,那么就非常完美。而用Q来描述样本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和P一样完美的描述。如果我们的Q通过反复训练,也能完美的描述样本,那么就不再需要额外的“信息增量”,Q等价于P。

n为事件的所有可能性。
DKL的值越小,表示q分布和p分布越接近
交叉熵
对上式变形可以得到
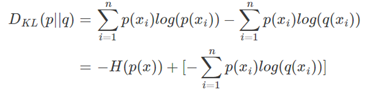
等式的前一部分恰巧就是p的熵,等式的后一部分,就是交叉熵:

在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即DKL(y||y^),由于KL散度中的前一部分−H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。
衡量各个熵之间的关系
