1.常亮与变量
- 1.1.
常量[Python中建议定义变量名称时使用所有字母大写(潜规则)]
不轻易改变的变量[例如:服务的root目录]
- 1.2.
变量[Python中建议定义变量名称时使用驼峰写法或下划线写法,不建议使用全部字母大写]
频繁使用及修改的变量[例如:购物车]
- 1.3.
注意[在Python中常亮默认规则为变量名称所有字母大写(潜规则)]
其实Python没有常量的特殊定义其实可以被修改,但是不建议修改
2.安装模块的2种方式
- 2.1.pip
安装[pip install <第三方库名称>]
卸载[pip uninstall <已安装的第三方库名称>]
- 2.2.easy_install
安装[easy_install <第三方库名称>]
卸载[easy_install -mxN <已安装的第三方库名称>]
3.环境变量
#!/usr/bin/env python
#_*_coding:utf-8 _*_
import sys
path_dir=sys.path
print(path_dir)
输出
['/Data', '/usr/local/python-3.5.11/lib/python35.zip', '/usr/local/python-3.5.11/lib/python3.5', '/usr/local/python-3.5.11/lib/python3.5/plat-linux', '/usr/local/python-3.5.11/lib/python3.5/lib-dynload', '/usr/local/python-3.5.11/lib/python3.5/site-packages']
#简要说明:列表的第一位置永远是当前目录,搜索调用的模块时按照列表索引顺序查找,找到即调用,不会再继续往下寻找
注意
#操作系统不同,导致默认模板的存放位置不同,建议存放到指定位置,方便其他用户调用
[Centos] --> site-packages #Centos默认模块存放位置
or
[Ubuntu] --> dist-packages #Ubuntu默认模块存放位置
4.Python简要名词释义
#Python基于虚拟机的语言[先编译后解释的语言,执行时自动编译]
#注意:Python再次调用当前Python文件时会直接使用pyc文件[当文件被修改后对比修改时间,永远使用最新的文件]
#注意:手动执行Python时不会生成pyc文件[被别人导入的才会生成字节码文件]
PyCodeObject :编译的结果保存位于内存中的PyCodeObject中
pyc后缀文件:编译器真正编译好的结果,字节码文件[Python解释器能读懂]
5.数据类型-数字(int)
整型(int)长整型(int)浮点数(float)复数(int)
6.数据类型-布尔值(bool)
True(真)
#经过判断1为真
>>> 1==True
True
>>> 0==True
False
Flase(假)
#经过判断0为假
>>> 1==False
False
>>> 0==False
True
7.数据类型-字符串(str)
字符串:字符串或串(String)是由数字、字母、下划线组成的一串字符
万恶的字符串拼接:python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空间,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的"+"号每出现一次就会在内从中重新开辟一块空间.所以不建议使用“+”号拼接字符串
常用字符串命令
#字符串格式化
str.format()
#剥除前后的空格、Tab、换行
str.strip()
#默认按空格切分成列表
str.split()
#格式化输出字符串首字母大写
str.capitalize()
#查找索引位置
str.find()
#字符串替换
str.replace()
#字符串切片
str[1:-1]
#字符串居中补全
str.center()
#判断字符串是不是数字
str.isdigit()
#判断字符串中是否包含特殊字符串
str.isalnum()
#判断字符串是否为匹配的开头
str.startswith()
#判断字符串是否为匹配的结尾
str.endswith()
#将字符串完全转换成大写
str.upper()
#将字符串完全转换成小写
str.lower()
- str.format()
#指定传参的名称
>>> "Welcome to {address}.My name is {name}".format(address="tianjian",name="Yorick")
'Welcome to tianjian.My name is Yorick'
#默认按顺序传参
>>> "Welcome to {}.My name is {}".format("tianjian","Yorick")
'Welcome to tianjian.My name is Yorick'
#默认按顺序传参
>>> "Welcome to {0}.My name is {1}".format("tianjian","Yorick")
'Welcome to tianjian.My name is Yorick'
- str.strip()
>>> celebrate=" Welcome to beijing "
#使用strip之前
>>> print("start|" + celebrate + "|end")
start| Welcome to beijing |end
#使用strip之后
>>> print("start|" + celebrate.strip() + "|end")
start|Welcome to beijing|end
- str.split()
>>> celebrate="Welcome to beijing. My name is Yorick."
#将字符串转换成列表
>>> celebrate.split()
['Welcome', 'to', 'beijing.', 'My', 'name', 'is', 'Yorick.']
>>> type(celebrate.split())
<class 'list'>
- str.capitalize()
>>> celebrate="hello world"
#首字母转换成大写
>>> celebrate.capitalize()
'Hello world'
- str.find()
>>> celebrate="hello world"
#查找d的索引位置
>>> celebrate.find("d")
10
- str.replace()
>>> celebrate="Welcome to beijing. My name is Yorick."
#将Yorick替换成Bill
>>> celebrate.replace("Yorick","Bill")
'Welcome to beijing. My name is Bill.'
- str[1:-1]
>>> celebrate="Welcome to beijing. My name is Yorick."
#提取索引位置11-18之间的字符(注意:顾头不顾尾)
>>> celebrate[11:18]
'beijing'
- str.center()
#40个字符,包含字符串的长度,不够的用“-”补全,字符串居中
>>> "Hello world".center(40,"-")
'--------------Hello world---------------'
- str.isdigit()
#判断字符串能不能转换成数字
>>> "abc12345!".isdigit()
False
>>> "88298123".isdigit()
True
- str.isalnum()
#判断字符串包含不包含特殊字符
>>> "88298123".isalnum()
True
>>> "88298123!2".isalnum()
False
>>> "882sdfasdf2".isalnum()
True
- str.startswith()
#判断字符串是否是以指定的字符开头
>>> "hello world".startswith("llo")
False
>>> "hello world".startswith("hell")
True
- str.ensswith()
#判断字符串是否是以指定的字符结尾
>>> "hello world".endswith("llo")
False
>>> "hello world".endswith("ld")
True
- str.upper()
#将字符串全部转换成大写
>>> "hello world".upper()
'HELLO WORLD'
- str.lower()
#将字符串全部转换成小写
>>> "HELLO WORLD".lower()
'hello world'
8.元组
元组:不可变列表
常用元组用法
#查看元素的索引位置
tuple.index()
#统计相同元素的个数
tuple.count()
#元组支持查看具体索引位置的元素信息
tuple[0]
- tuple.index()
#查看123的索引位置
>>> (1,2,3,123,12,2,3,3,3,12,32,1,23,23,123,123,123,3123,).index(123)
3
- tuple.count()
#统计与123元素相同的个数
>>> (1,2,3,123,12,2,3,3,3,12,32,1,23,23,123,123,123,3123,).count(123)
4
- tuple[0]
#查看元组索引所在位置的元素
>>> (1,2,3,123,12,2,3,3,3,12,32,1,23,23,123,123,123,3123,)[4]
12
9.列表
列表:一个中括号开始,一个中括号结束,中间的内容为元素[列表中可以存储任何数据类型]
注意:所有元素的索引[下标]值一定都是从0开始的
常用列表用法
#列表的索引
list[0]
#列表的修改
list[0]="test"
#列表的切片
list[1:3]
#列表的步长
list[::1]、list[::-1]、list[::2]
#列表的插入
list.insert()
#列表的追加
list.append()
#列表的移除
list.remove()
#列表中相同元素的统计
list.count()
#列表中元素的索引
list.index()
#清空列表
list.clear()
#扩展列表
list.extend()
#列表的反转
list.reverse()
#列表的排序
list.sort()
#指点索引删除元素
list.pop()
#列表的浅拷贝
list.copy()
#列表的深拷贝
copy.deepcopy()
#列表索引位置及元祖同时输出
enumerate(list)
#列表粘合成字符串
" ".join(list)
- list[0]
#列表中索引位置为4的元素
>>> [1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,][4]
5
- list[0]="test"
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
>>> new_list
[1, 2, 3, 4, 5, 5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33]
#将列表的索引位置为4的元素替换成“test”
>>> new_list[4]="test"
>>> new_list
[1, 2, 3, 4, 'test', 5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33]
- list[1:3]
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
#获取列表从开头到索引位置为4的元素[注意:切片时结尾的索引号写的位置永远不会被包含在切片呢]
>>> new_list[:5]
[1, 2, 3, 4, 5]
#索引位置填写最后一个,但切片时不显示最后一个元素“33”
>>> new_list[5:-1]
[5, 6, 6, 6, 6, 3, 3, 2, 2, 3]
#列表切片原则顾头不顾尾
>>> new_list[5:]
[5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33]
- list[::1]、list[::-1]、list[::2]
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
#列表的步长默认为1
>>> new_list[::1]
[1, 2, 3, 4, 5, 5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33]
#如果使用步长为“-1”就从后往前打印列表
>>> new_list[::-1]
[33, 3, 2, 2, 3, 3, 6, 6, 6, 6, 5, 5, 4, 3, 2, 1]
#设置步长为2,一次迈2步,列表的偶数元素不显示
>>> new_list[::2]
[1, 3, 5, 6, 6, 3, 2, 3]
- list.insert()
>>> [1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,].insert(2,"test")
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
#在索引3的位置插入“test”其他元素依次后退一个索引位
>>> new_list.insert(3,"test")
>>> new_list
[1, 2, 3, 'test', 4, 5, 5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33]
- list.append()
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
#在列表的最后附加一个元素
>>> new_list.append("test")
>>> new_list
[1, 2, 3, 4, 5, 5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33, 'test']
- list.remove()
[1, 2, 3, 4, 5, 5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33, 'test']
#移除匹配元素[可以指定开始索引和结束索引]
>>> new_list.remove("test")
>>> new_list
[1, 2, 3, 4, 5, 5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33]
- list.count()
#统计列表中“6”的个数
>>> [1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,].count(6)
4
- list.index()
#返回第一个“6”所在的索引[可以指定开始索引和结束索引]
>>> [1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,].index(6)
6
- list.clear()
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
#清空列表
>>> new_list.clear()
>>> new_list
[]
- list.extend()
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
>>> old_list=["test","Yorick","Bill"]
#将old列表附加到新里列表中,old列表不变
>>> new_list.extend(old_list)
>>> new_list
[1, 2, 3, 4, 5, 5, 6, 6, 6, 6, 3, 3, 2, 2, 3, 33, 'test', 'Yorick', 'Bill']
>>> old_list
['test', 'Yorick', 'Bill']
- list.reverse()
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
#让列表倒叙显示
>>> new_list.reverse()
>>> new_list
[33, 3, 2, 2, 3, 3, 6, 6, 6, 6, 5, 5, 4, 3, 2, 1]
- list.sort()
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
#针对列表进行排序[python3.0 不支持数字与字符串同时排序,需要单独排序]
>>> new_list.sort()
>>> new_list
[1, 2, 2, 2, 3, 3, 3, 3, 4, 5, 5, 6, 6, 6, 6, 33]
- list.pop()
>>> new_list=[1,2,3,4,5,5,6,6,6,6,3,3,2,2,3,33,]
#删除最后一个元素
>>> new_list.pop()
33
>>> new_list
[1, 2, 3, 4, 5, 5, 6, 6, 6, 6, 3, 3, 2, 2, 3]
#删除啊索引为4的元素
>>> new_list.pop(4)
5
- list.copy()
>>> new_list=[1,2,3,4,[5,6,7,8,],]
#浅拷贝
>>> new_list2=new_list.copy()
#查看列表内容及列表内容中的内存地址,可以看到第二层内容引用统一个内存地址
>>> new_list,id(new_list),id(new_list[-1])
([1, 2, 3, 4, [5, 6, 7, 8]], 139641885027848, 139641885626312)
>>> new_list2,id(new_list2),id(new_list2[-1])
([1, 2, 3, 4, [5, 6, 7, 8]], 139641885626056, 139641885626312)
- copy.deepcopy()
>>> import copy
>>> new_list=[1,2,3,4,[5,6,7,8,],]
#使用copy函数深度拷贝
>>> new_list2=copy.deepcopy(new_list)
#查看第一层列表、第一层内存信息、第二层内存信息(完全独立的两个列表)
>>> new_list,id(new_list),id(new_list[-1])
([1, 2, 3, 4, [5, 6, 7, 8]], 139641758272008, 139641755648072)
>>> new_list2,id(new_list2),id(new_list2[-1])
([1, 2, 3, 4, [5, 6, 7, 8]], 139641885027848, 139641758272776)
- enumerate(list)
#通过enumerate提取对应的索引号及元素,依次提取两个变量
>>> for key_id,key_value in enumerate(["test","Yorick","Bill"]):
... print(key_id,key_value)
...
0 test
1 Yorick
2 Bill
- " ".join(list)
#以空格为间隔符,将列表组合起来
>>> " ".join(["hello","world","real"])
'hello world real'
10.字典
字典:可变容器模型,且可存储任意类型对象,字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中[字典是无序的]
常用列表用法
#根据key获取value元素
dict[key]
#修改key对应的value元素
dict[key]=value
#删除字典中的某一个key
del dict[key]
#删除字典中的某一个key(内核函数)
dict.pop(key)
#友好的获取value信息,当不存在是返回None
dict.get(key)
#将字典转换成字典列表
dict.items()
#打印字典里所有key信息
dict.keys()
#打印字典里的所有value信息
dict.values()
#如果没有即添加,如果有就覆盖
dict.update()
#如果存在key则返回value值,如果不存在即添加一个默认的键值对
dict.setdefault()
#将可迭代的元组或列表中每一个元素,当做字典的一个key
dict.fromkeys()
#随机删除字典中的一对key-value
dict.popitem()
- dict[key]
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
#获取key值为1的value信息
>>> new_dict[1]
'Alex'
- dict[key]=value
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
#修改key值为1的 value信息
>>> new_dict[1]="Jason"
>>> new_dict
{1: 'Jason', 2: 'Yorick', 3: 'Aric', 4: 'Bill'}
- del dict[key]
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
#删除key为1的键值对
>>> del new_dict[1]
>>> new_dict
{2: 'Yorick', 3: 'Aric', 4: 'Bill'}
- dict.pop(key)
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
#回显删除的value信息,可做赋值使用
>>> new_dict.pop(1)
'Alex'
>>> new_dict
{2: 'Yorick', 3: 'Aric', 4: 'Bill'}
- dict.get(key)
>>> new_dict={1:"value",2:"value",3:"value",4:"value",}
#当获取无效的key时,直接引用key会报错
>>> new_dict[5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 5
#当获取无效的key时,使用get获取,会返回None
>>> print(new_dict.get(5))
None
#通过两种方式获取存在的key时
>>> new_dict[4]
'value'
>>> new_dict.get(4)
'value'
- dict.items()
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
#使用item会将字典生成字典列表(字典列表转换为列表需要list(dict_items))
>>> current=new_dict.items()
>>> type(new_dict),type(current)
(<class 'dict'>, <class 'dict_items'>)
- dict.keys()
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
#将字典中的所有key提取出来并组成一个字典列表
>>> new_dict.keys()
dict_keys([1, 2, 3, 4])
>>> type(new_dict.keys())
<class 'dict_keys'>
- dict.values()
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
#将字典中的所有value提取出来并组成一个字典列表
>>> new_dict.values()
dict_values(['Alex', 'Yorick', 'Aric', 'Bill'])
>>> type(new_dict.values())
<class 'dict_values'>
- dict.update()
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
>>> old_dict={4:"red",5:"yellow",6:"green"}
#新字典列附加旧字典列表,重复key将会被覆盖
>>> new_dict.update(old_dict)
>>> new_dict
{1: 'Alex', 2: 'Yorick', 3: 'Aric', 4: 'red', 5: 'yellow', 6: 'green'}
- dict.setdefault()
>>> new_dict={1:"Alex",2:"Yorick",3:"Aric",4:"Bill"}
#获取key为1的value信息
>>> new_dict.setdefault(1)
'Alex'
#获取key为5的value信息,如果不存在即赋值默认值为None
>>> new_dict.setdefault(5)
>>> new_dict
{1: 'Alex', 2: 'Yorick', 3: 'Aric', 4: 'Bill', 5: None}
#如果不存在对应的key信息,也可以指定添加内容
>>> new_dict.setdefault(6,"salary")
'salary'
>>> new_dict
{1: 'Alex', 2: 'Yorick', 3: 'Aric', 4: 'Bill', 5: None, 6: 'salary'}
- dict.fromkeys()
#将元组中每一个元素提取出来,分别与value组成字典
>>> new_dict=dict.fromkeys((1,2,3,4),"value")
>>> new_dict
{1: 'value', 2: 'value', 3: 'value', 4: 'value'}
#将列表中每一个元素提取出来,分别与value组成字典
>>> new_dict=dict.fromkeys([1,2,3,4],"value")
>>> new_dict
{1: 'value', 2: 'value', 3: 'value', 4: 'value'}
- dict.popitem()
>>> new_dict={0: 'default', 1: 'default', 2: 'default', 3: 'default', 4: 'default', 5: 'default', 6: 'default', 7: 'default', 8: 'default', 9: 'default', 10: 'default', 11: 'default', 12: 'default', 13: 'default', 14: 'default', 15: 'default', 16: 'default', 17: 'default', 18: 'default', 19: 'default', 20: 'default', 21: 'default', 22: 'default', 23: 'default', 24: 'default', 25: 'default', 26: 'default', 27: 'default', 28: 'default', 29: 'default', 30: 'default', 31: 'default', 32: 'default', 33: 'default', 34: 'default', 35: 'default', 36: 'default', 37: 'default', 38: 'default', 39: 'default', 40: 'default', 41: 'default', 42: 'default', 43: 'default', 44: 'default', 45: 'default', 46: 'default', 47: 'default', 48: 'default', 49: 'default', 50: 'default', 51: 'default', 52: 'default', 53: 'default', 54: 'default', 55: 'default', 56: 'default', 57: 'default', 58: 'default', 59: 'default', 60: 'default', 61: 'default', 62: 'default',}
#显示删除掉的信息
>>> new_dict.popitem()
(0, 'default')
11.单位的转换
8bit = 1byte(字节) [8个二进制位等于一个字节]
1024byte = 1kbyte
1024kbyte= 1mbyte
1024mbyte= 1gbyte
1024gbyte= 1tbyte
12.运算
12.1.算数运算
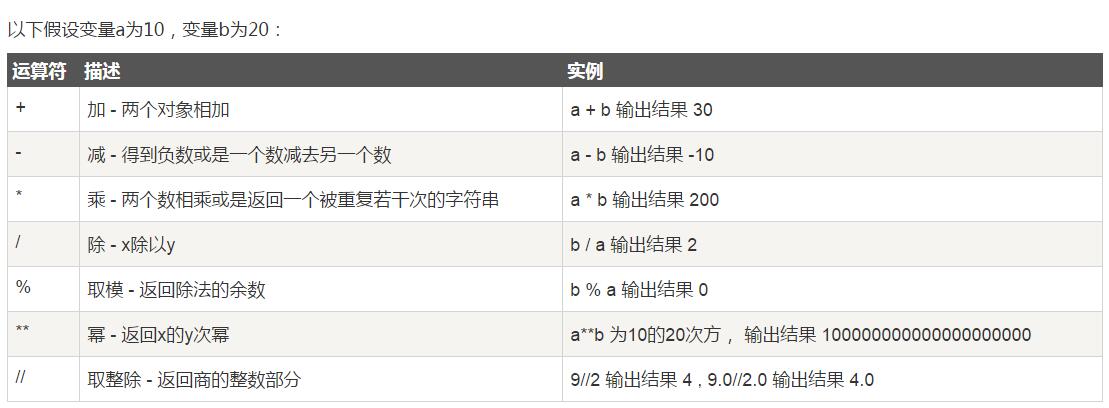
12.2.比较运算符
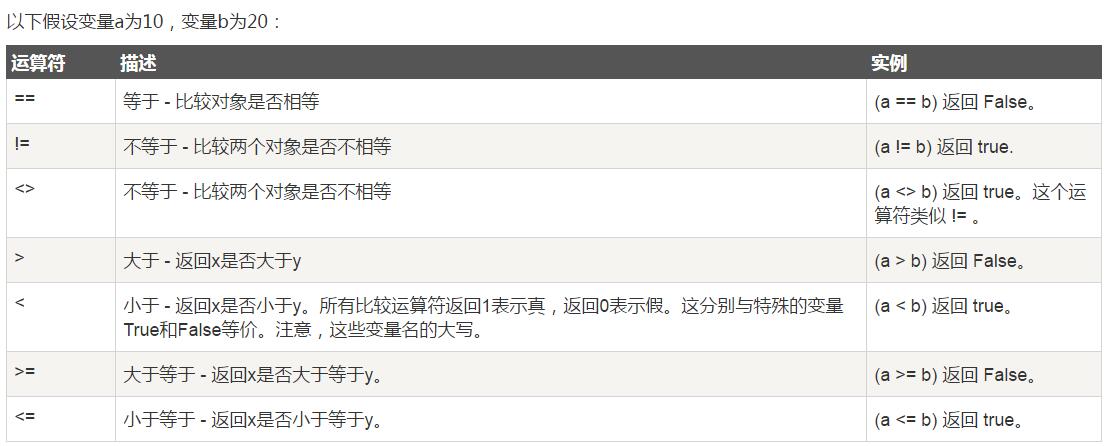
注意:python3中不支持"<>"
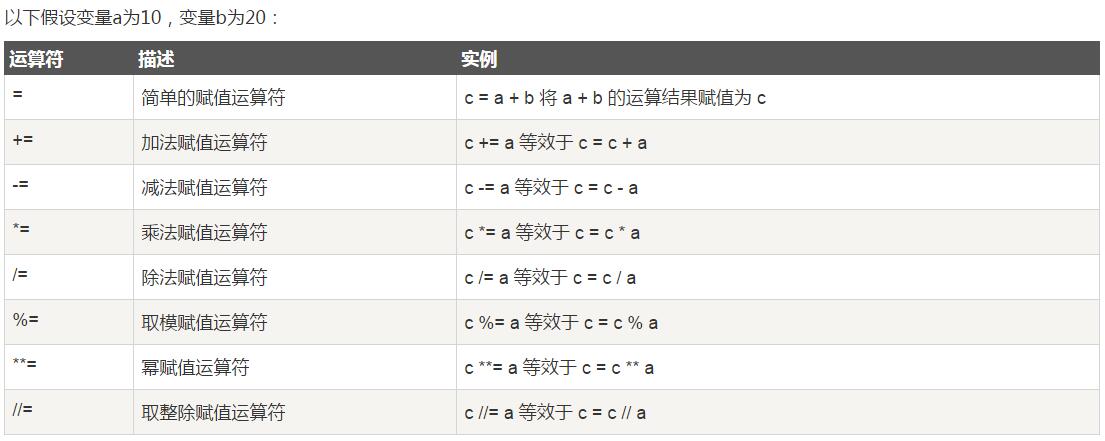
12.3.赋值运算符
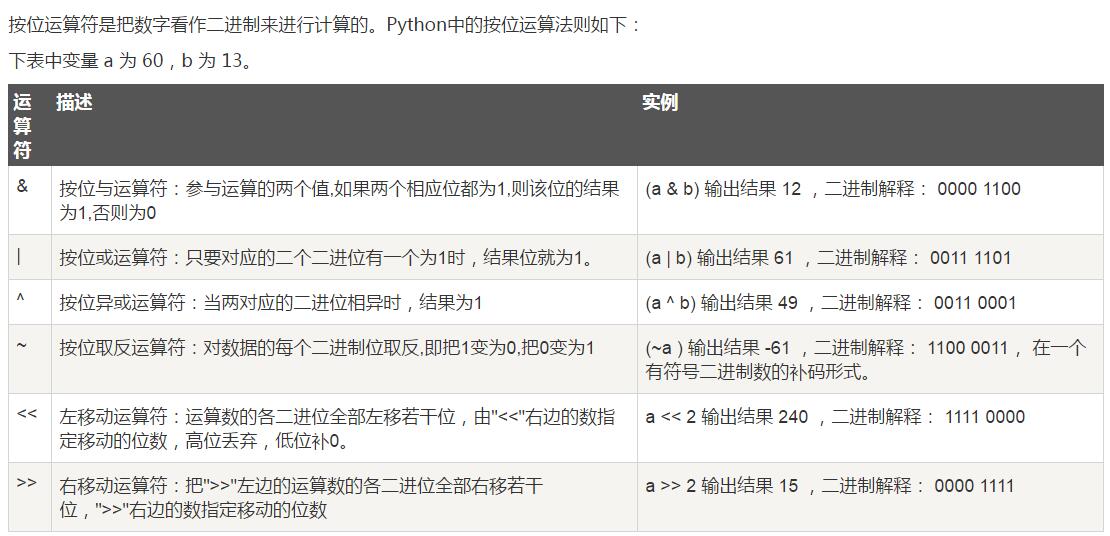
12.4.位运算
12.5.逻辑运算符

12.6.成员运算符

12.7.身份运算符

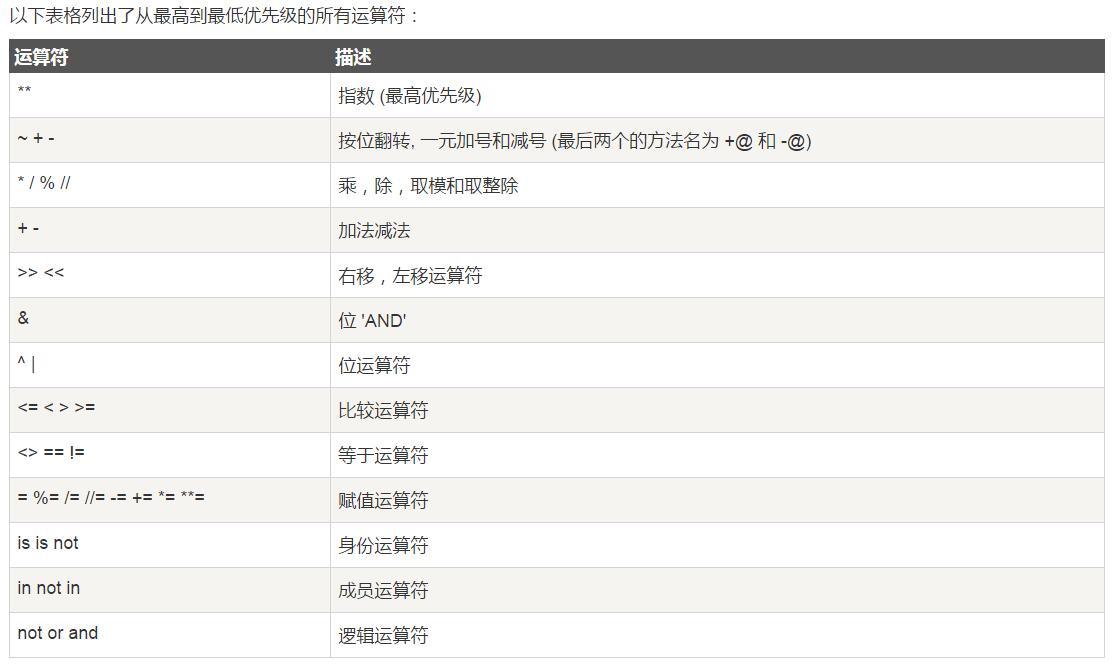
12.8.优先级运算
13.文件操作

#!/usr/bin/env python
#_*_ coding:utf-8 _*_
#以什么方式打开对象
file=open("login.db","w+")
#写入什么内容
file.write("root 123456 0")
#对打开对象的关闭,否则会一直占用内存空间
file.close