资源链接:链接: https://pan.baidu.com/s/1c1MIm1E 密码: gant
chapter2 : linear regression with one feature





************************************************************************************************************
************************************************************************************************************
chapter4:linear regression with multiple feature
- 在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛

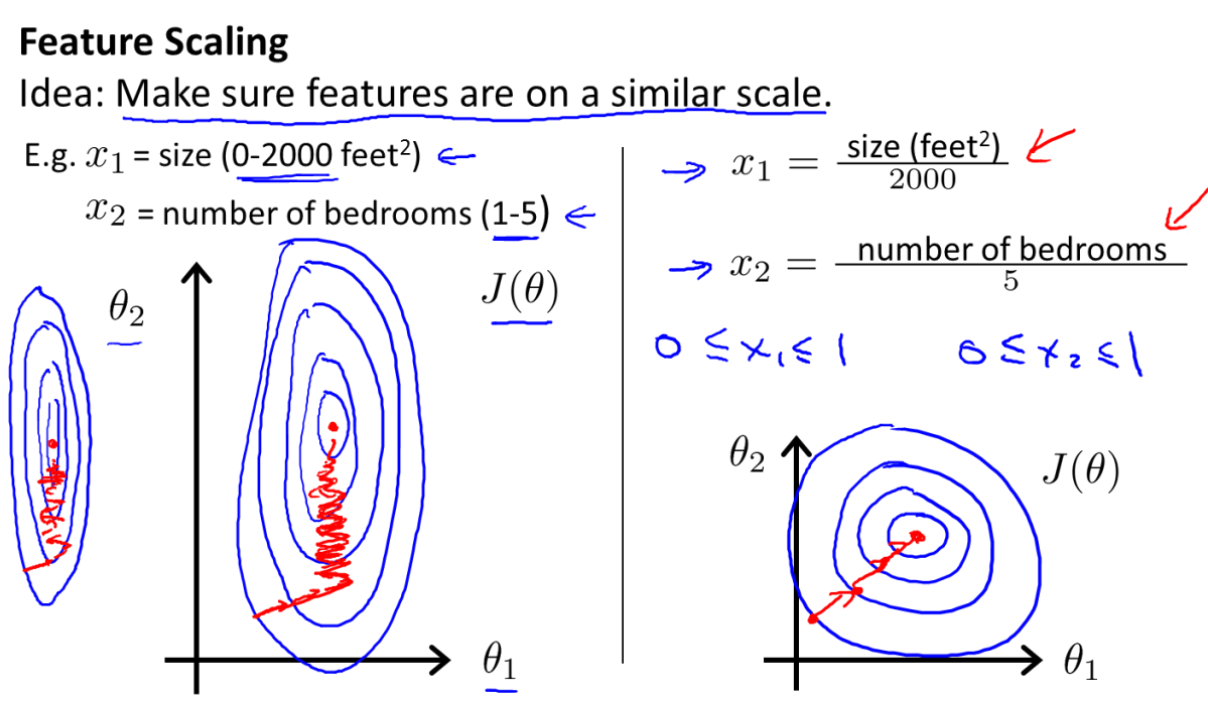

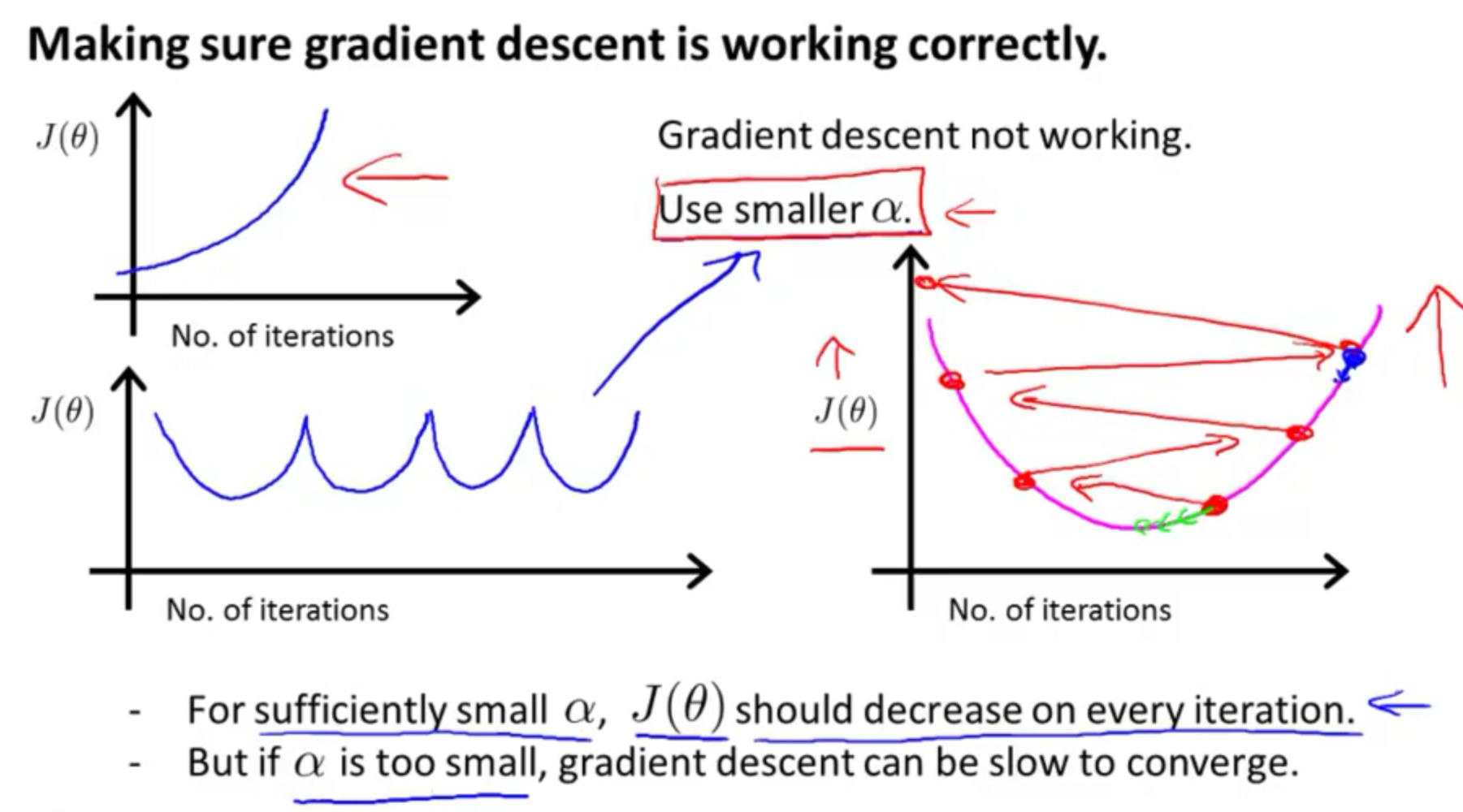
- 如果学习率 α 过小,则达到收敛所需的迭代次数会非常高;如果学习率 α 过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
************************************************************************************************************
************************************************************************************************************
chapter 5 : Octave
- 参考文献
- plot
 View Code
View Codex=[0:0.01:1]; y1=sin(2*pi*x); plot(x,y1); y2=cos(2*pi*x); hold on; plot(x,y2); xlabel('time'); ylabel('value'); title('my plot'); legend('sin','cos'); print -dpng 'my.png'; close; figure(1);plot(x,y1); figure(2);plot(x,y2); figure(3); subplot(1,2,1); plot(x,y1); subplot(1,2,2); plot(x,y2); axis([0.5 1 -1 1]); %change the axis of x and y clf; a=magic(5) imagesc(a); imagesc(a), colorbar,colormap gray;

*************************************************************************************************************
*************************************************************************************************************
chapter 6 : logistic regression and regularization
- 学习笔记



- for convex






************************************************************************************************************
************************************************************************************************************
chapter 7 : regularization

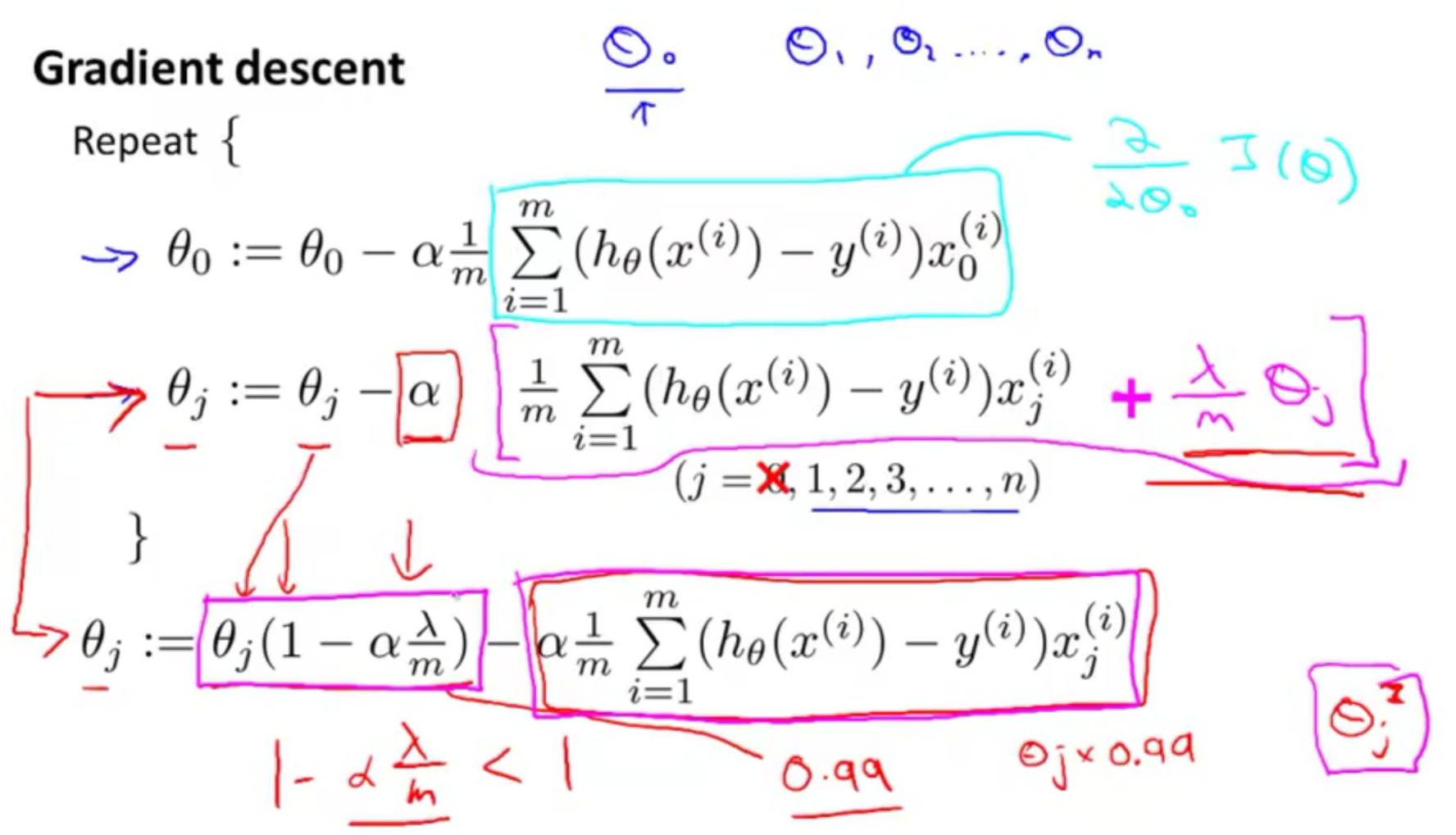


************************************************************************************************************
************************************************************************************************************
chapter 8 : neural network
- cost function


- forward propagation
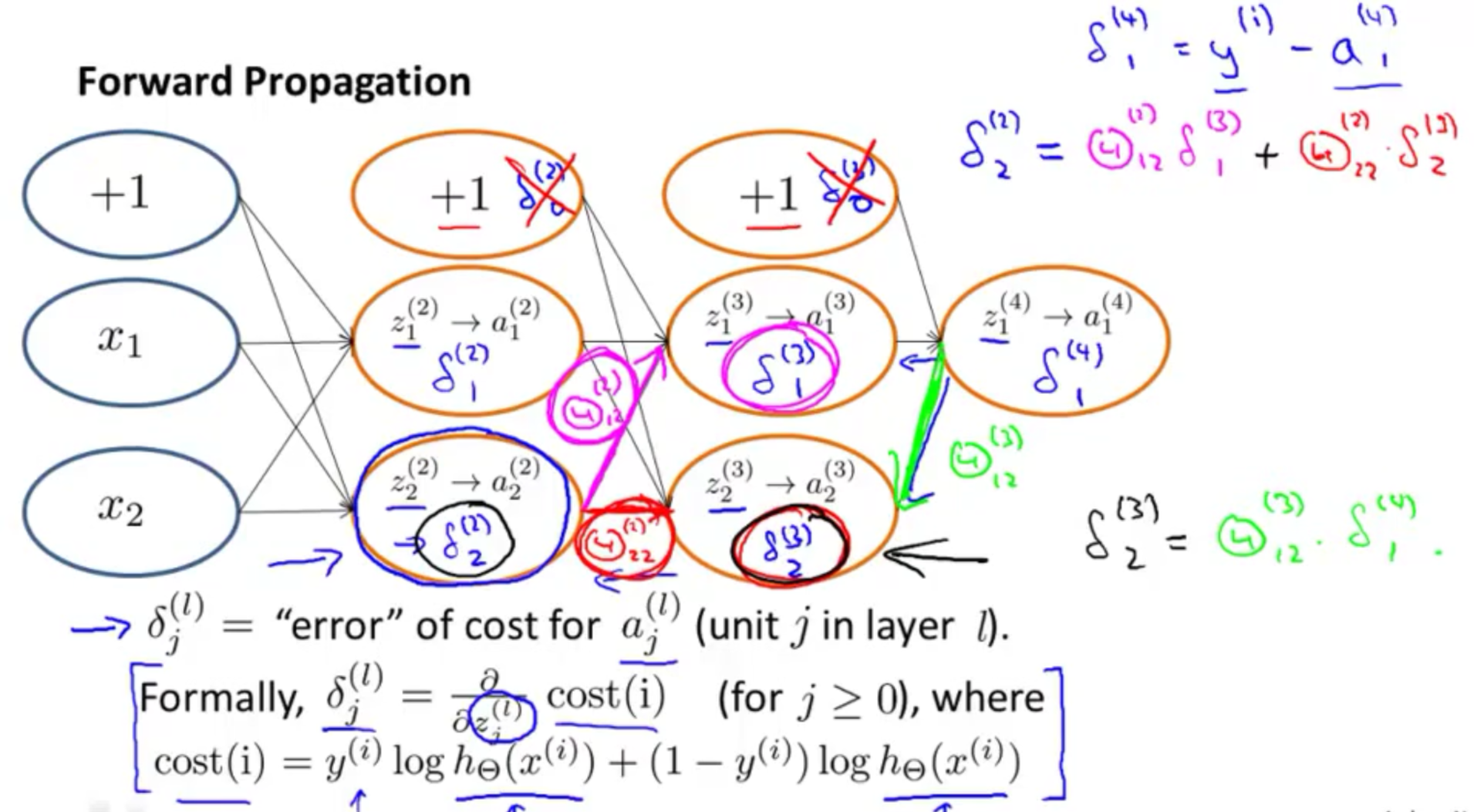
- backward propagation


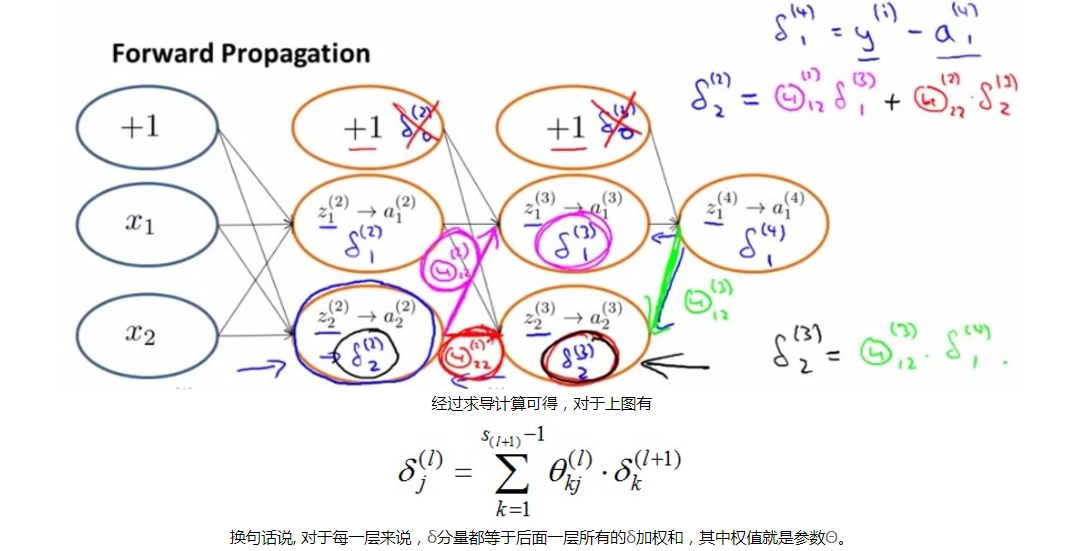
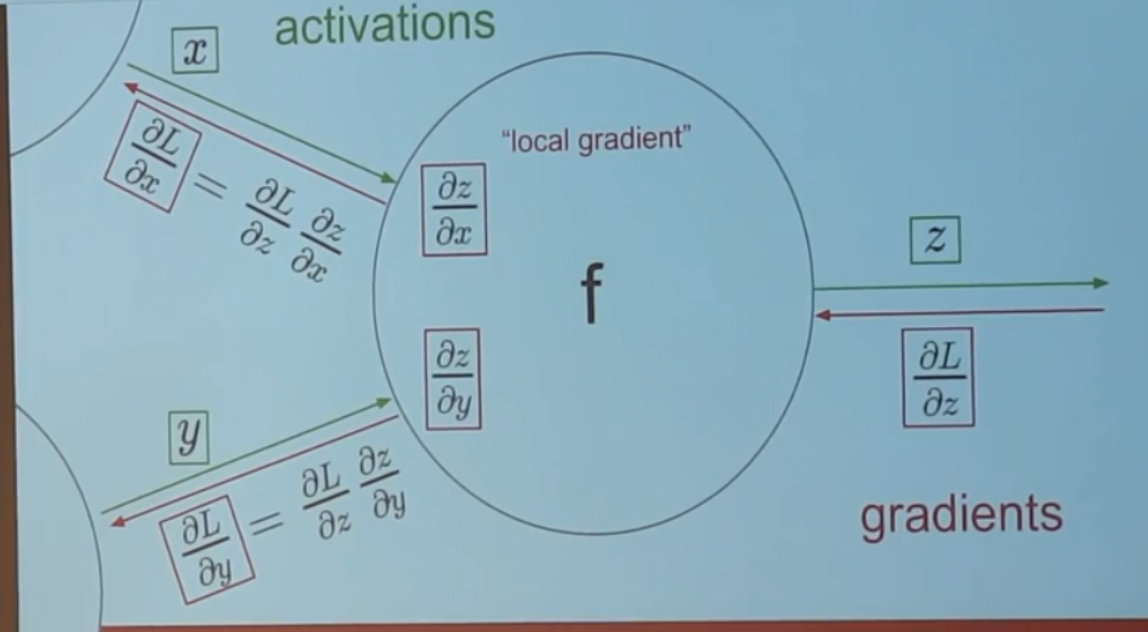
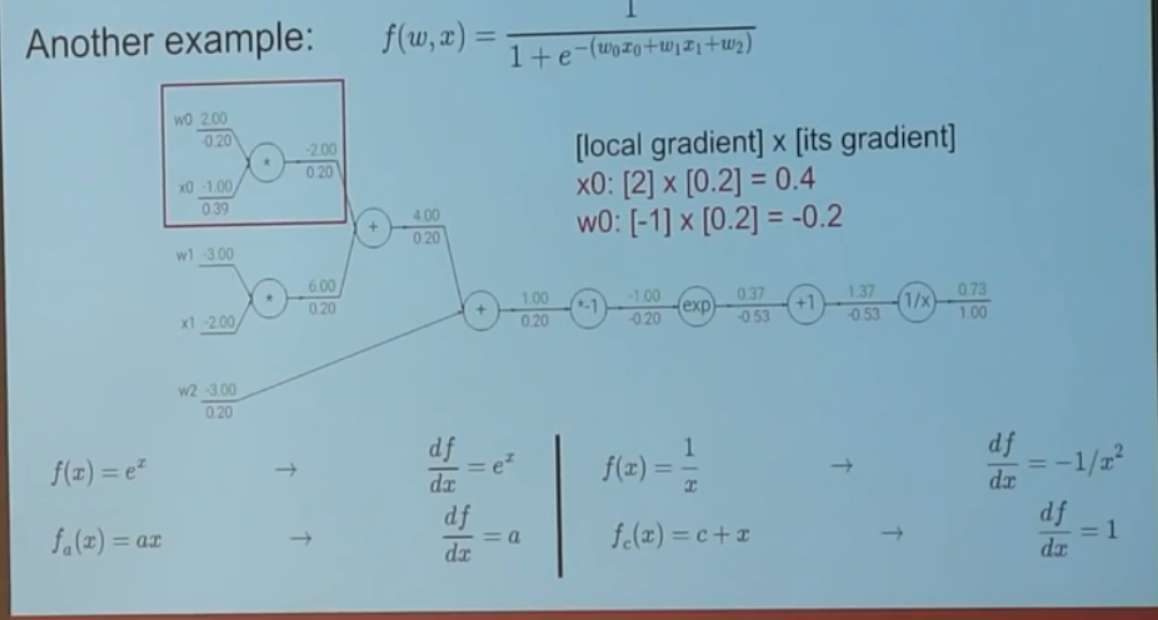
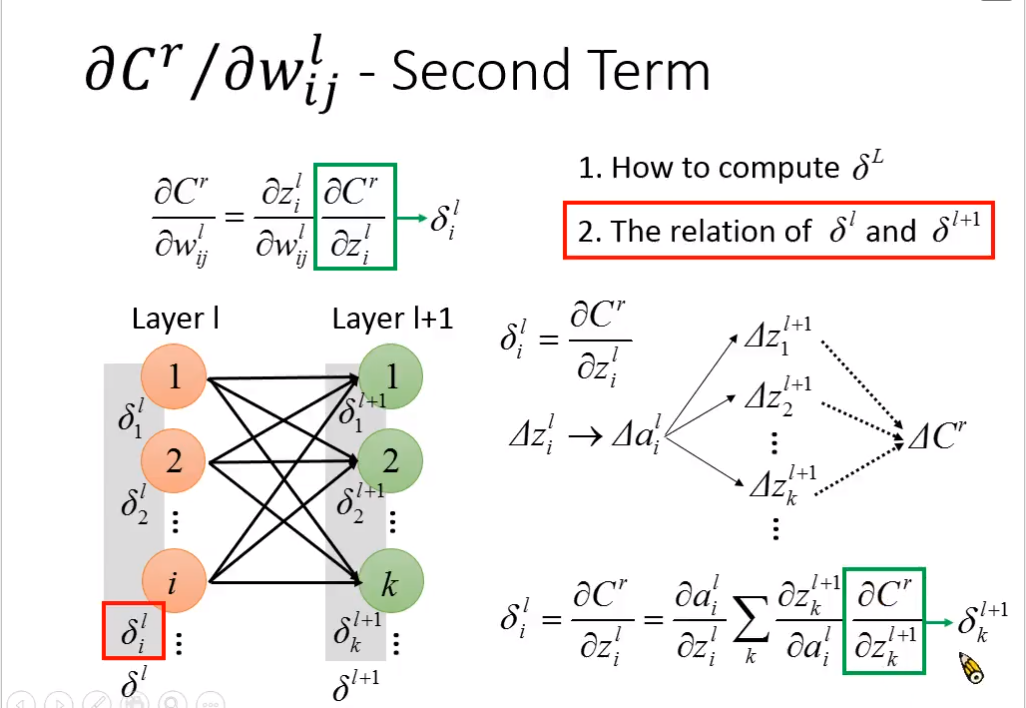
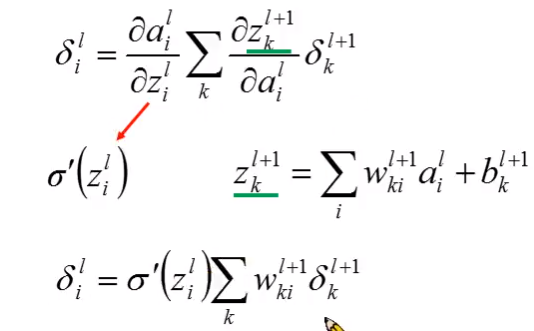

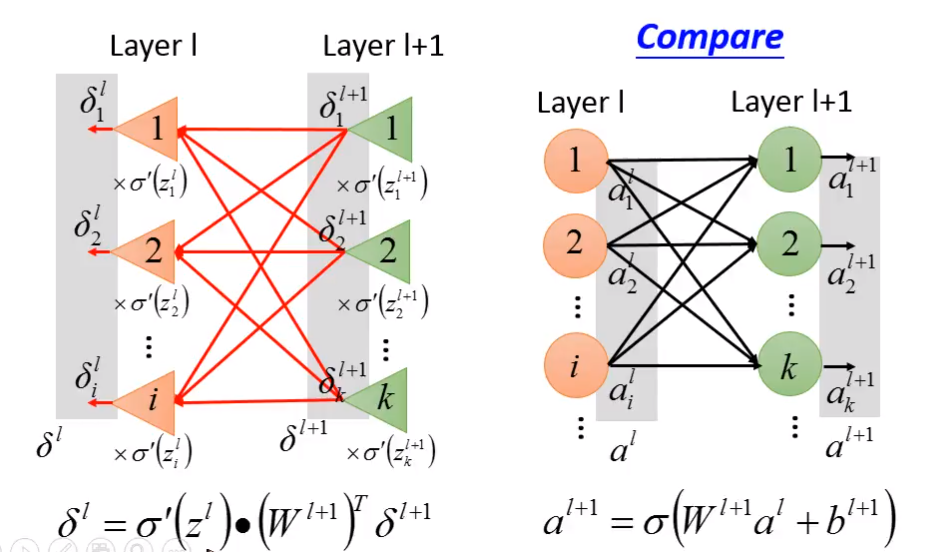
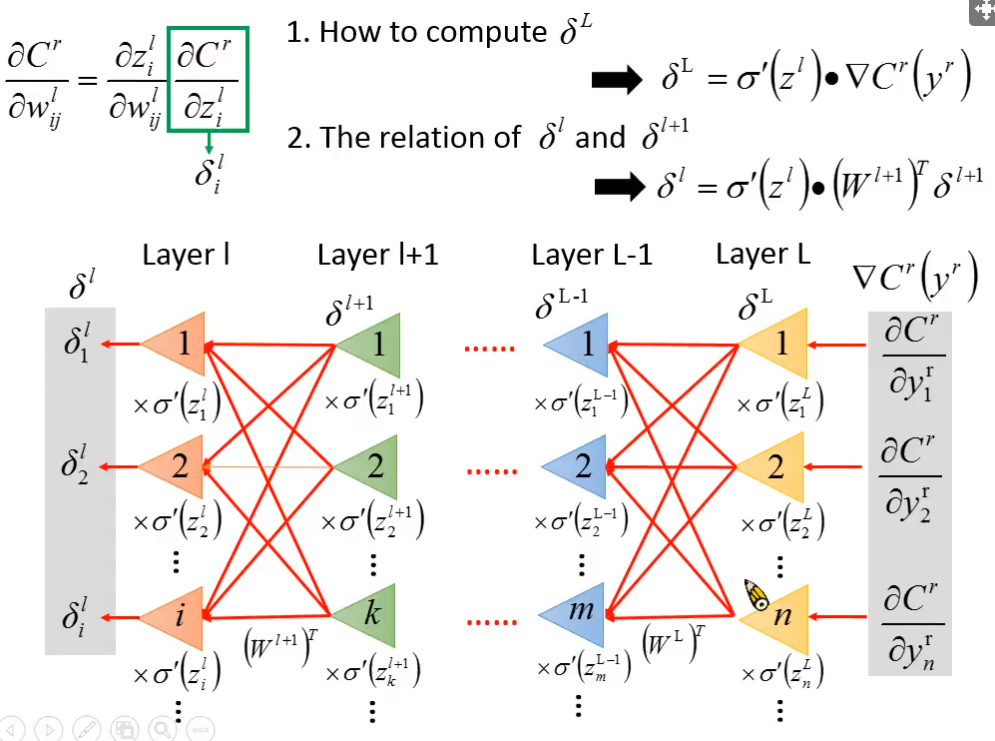

- 数学证明
- numerical estimation of gradient



- random initialization and the step of training a neural network



********************************************************************************************************
********************************************************************************************************
chapter 10 : Deciding what to try next
- evaluating a hypothesis with cross validation


-
Diagnosing bias and variance
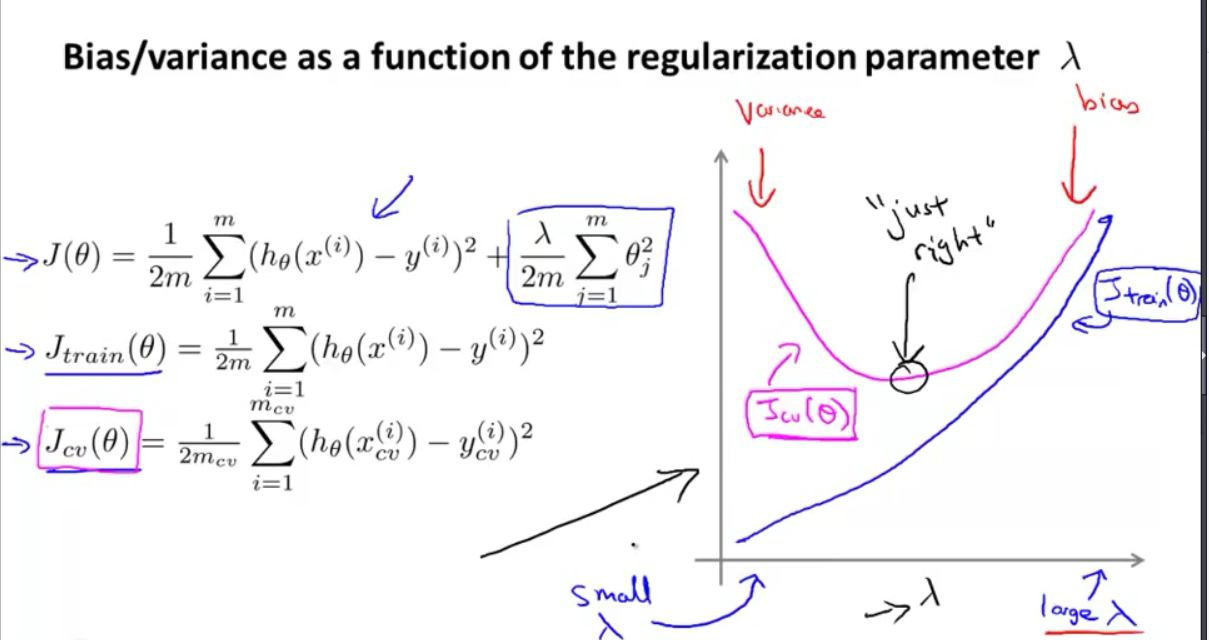
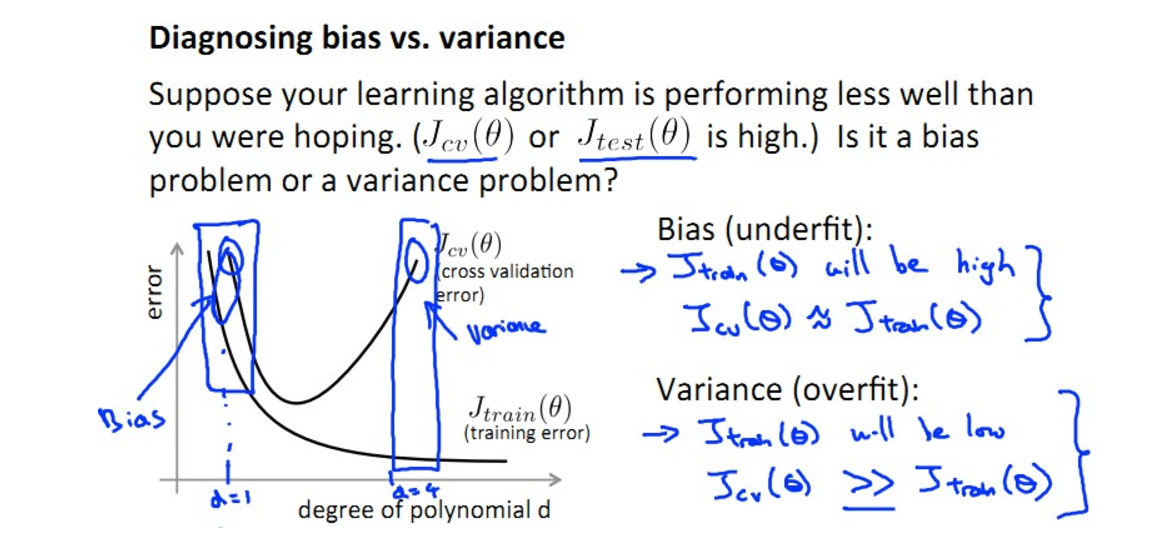
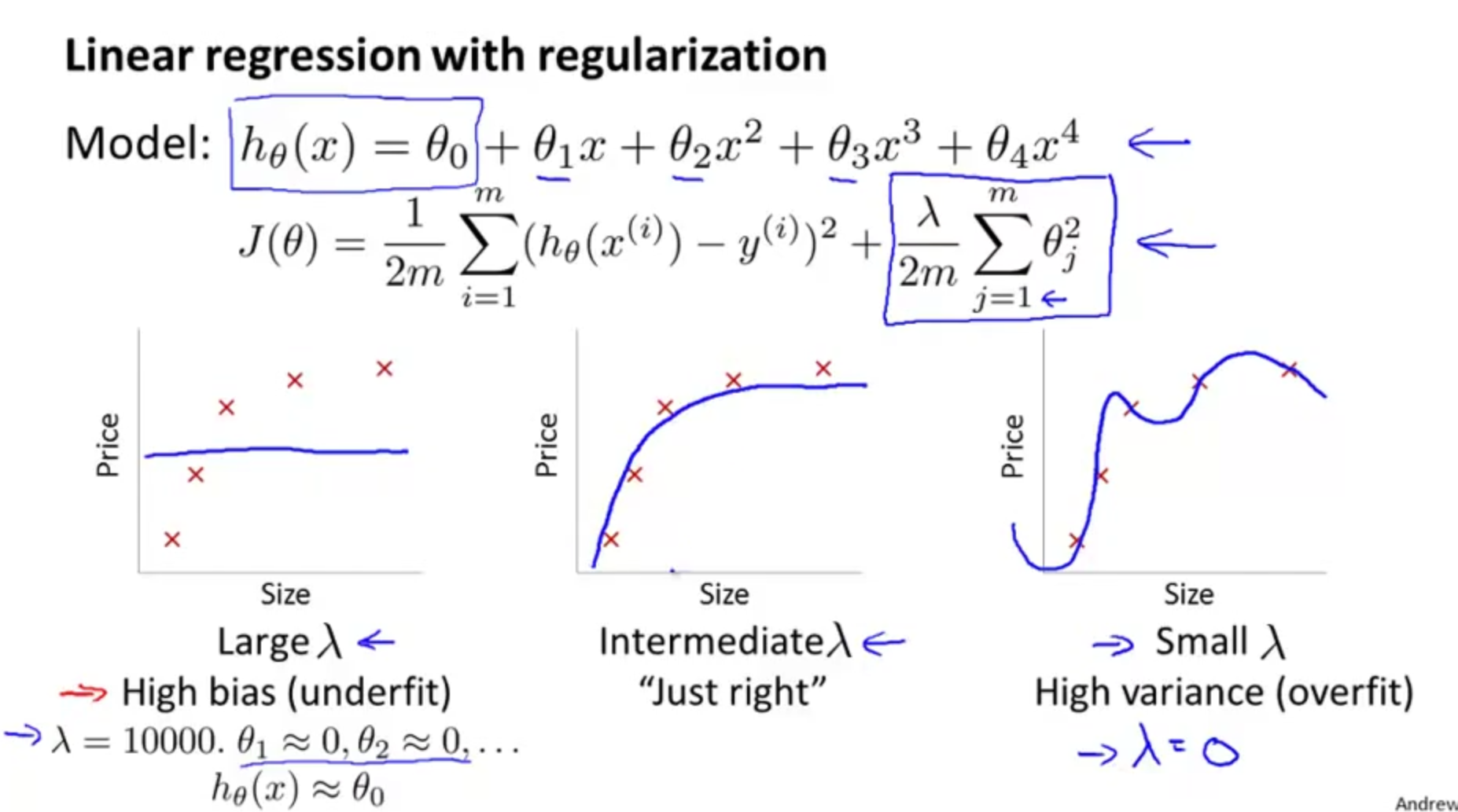

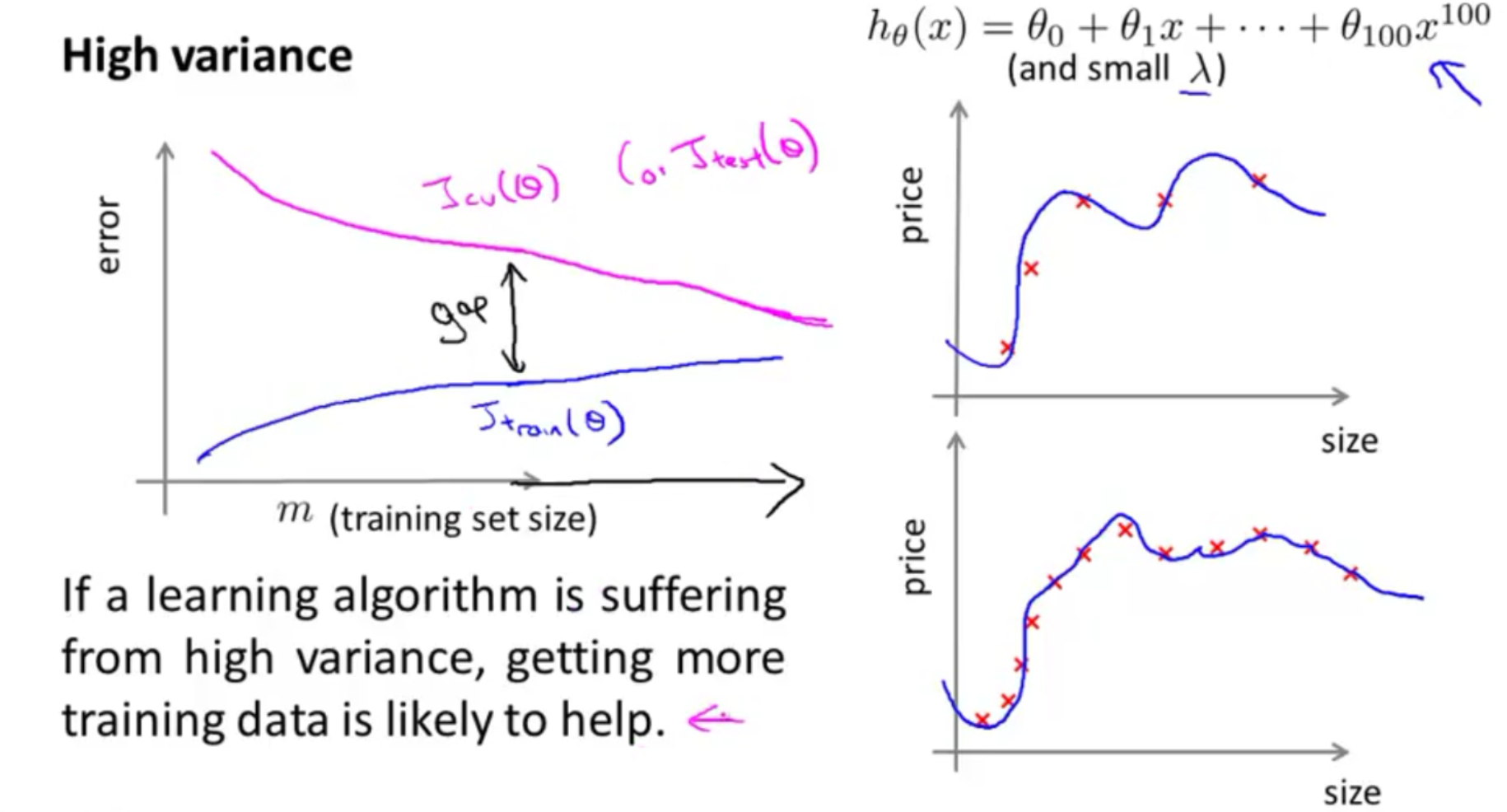
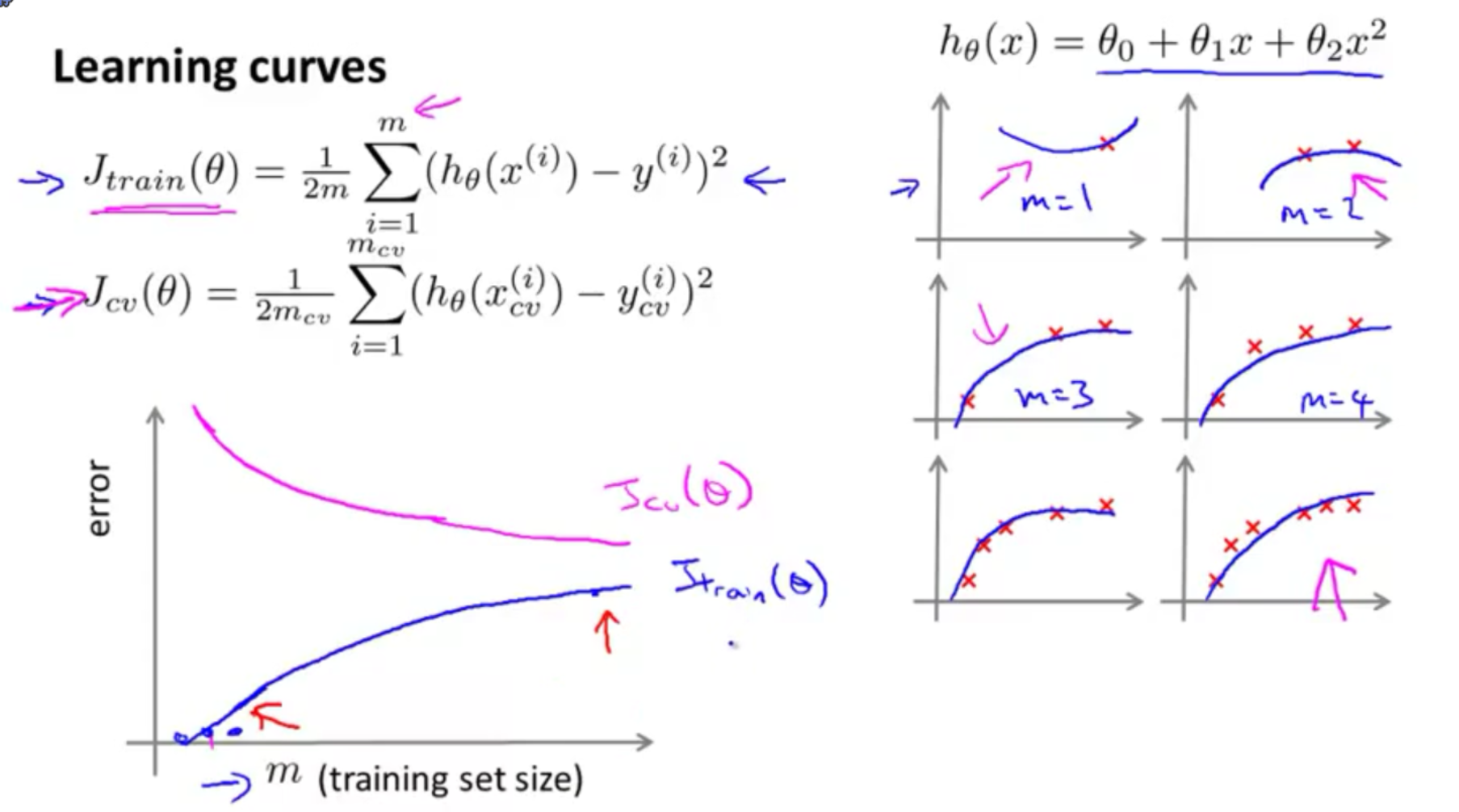
- learning curves and decide what to do next

**********************************************************************************************************
**********************************************************************************************************
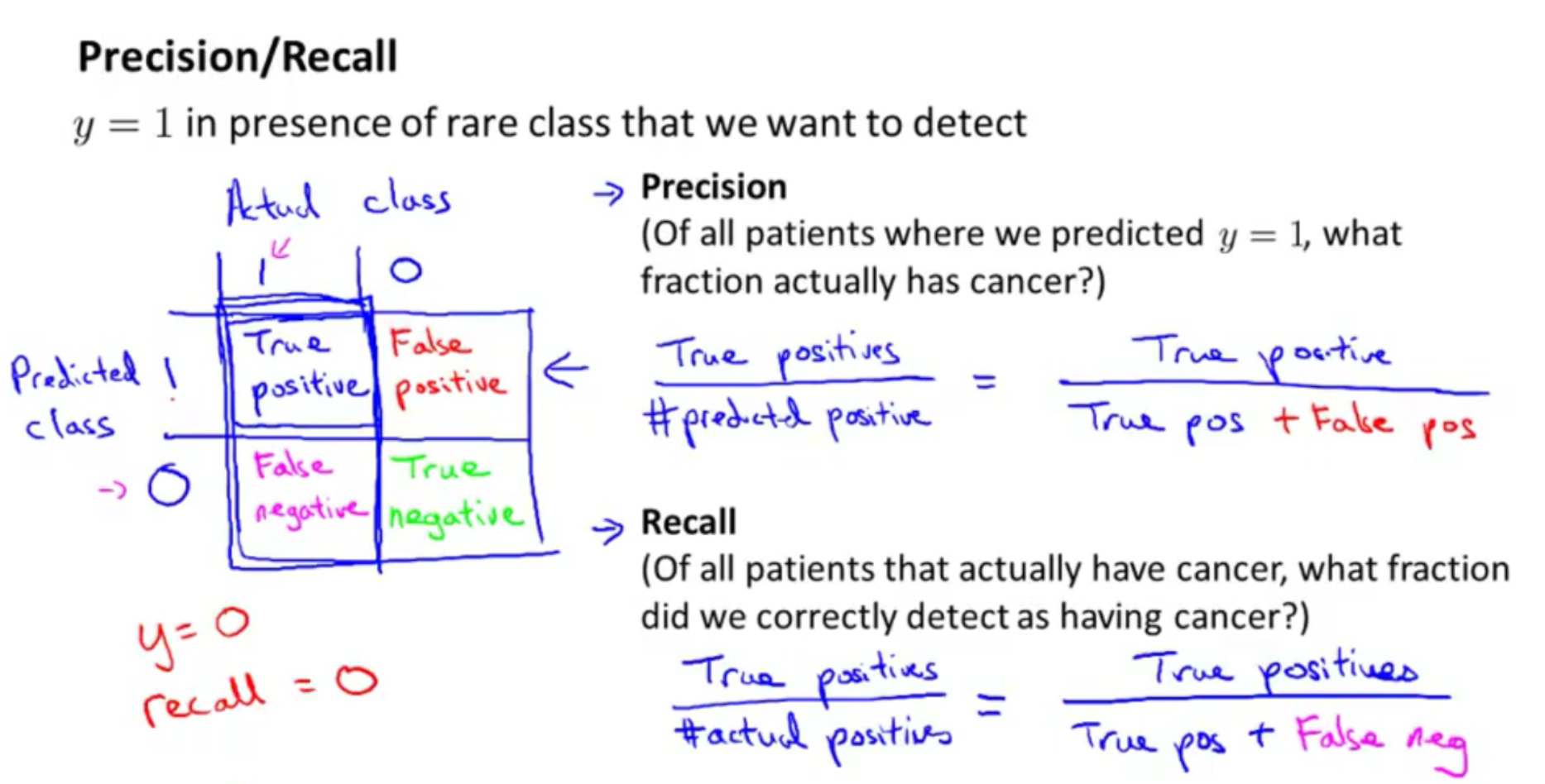
chapter 11 : precision and recall
- skewed data vs precision and recall

*********************************************************************************************************
*********************************************************************************************************
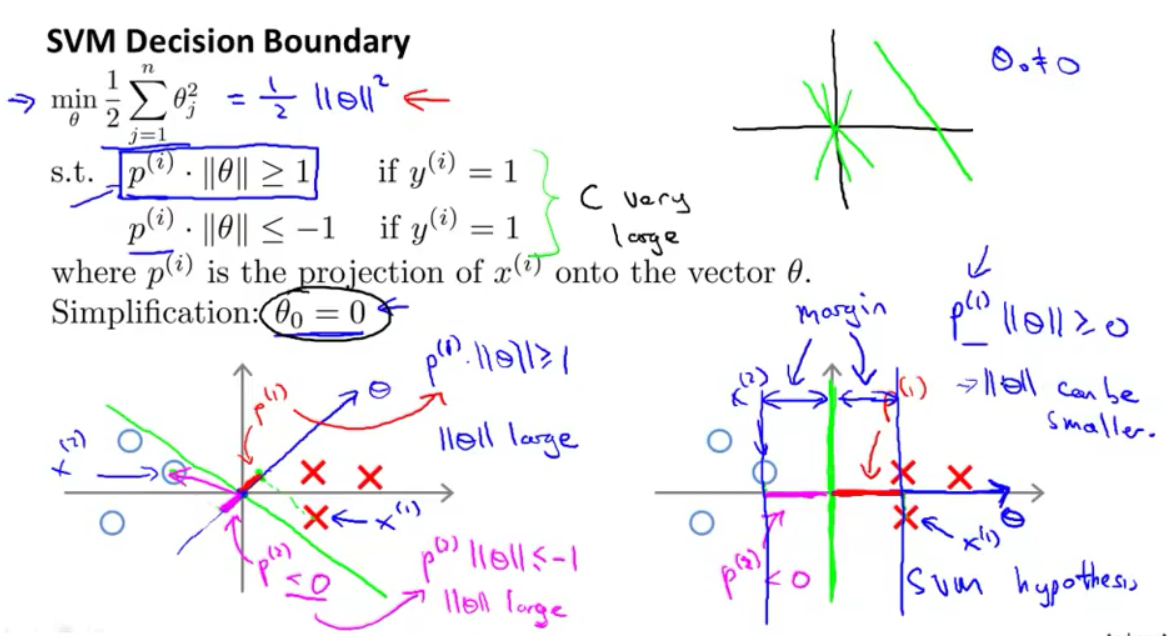
chapter 12 : SVM
- for enlagering the projection of X, then we get large margin


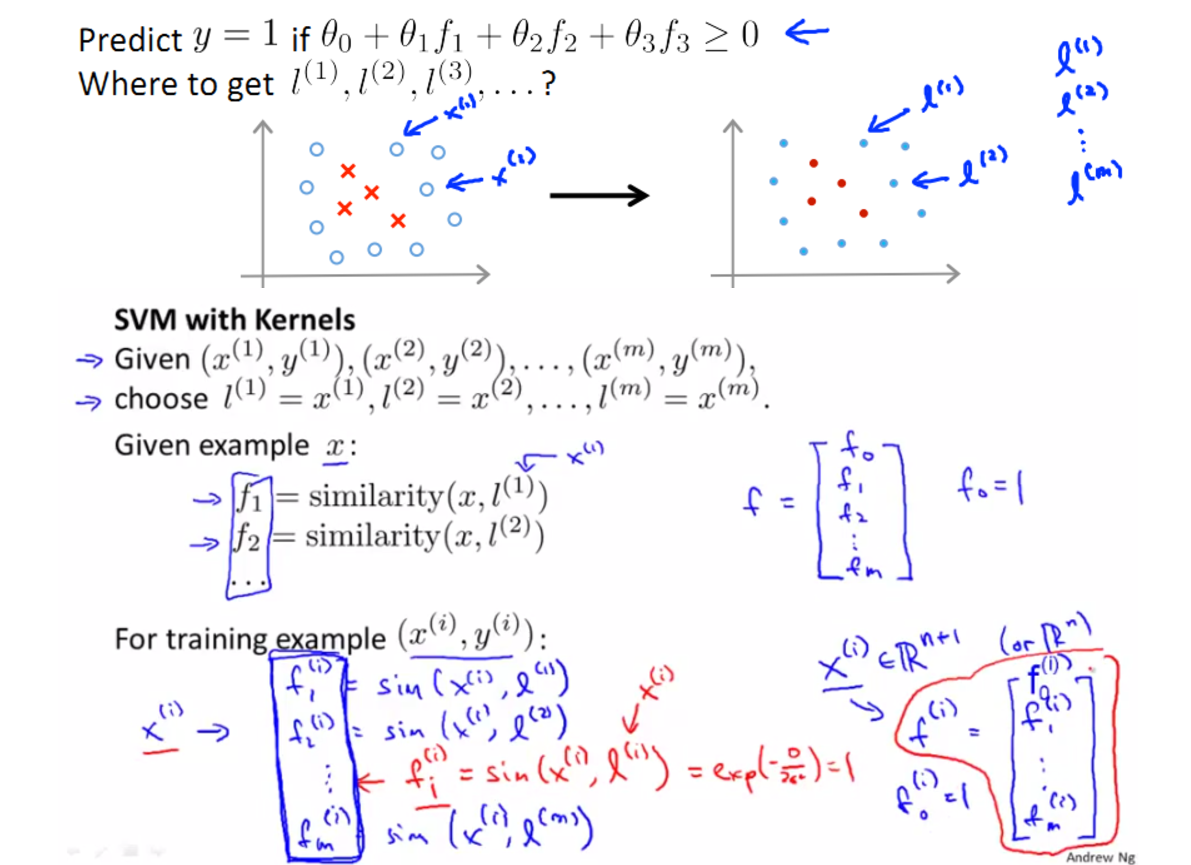
- kernel and do perform feature scalling before using the Gaussian kernel





-
Kernel need to satisfy technical condition called "Mercer's Theorem" to make sure SVM packages' optimizations run correctly, and do not diverge.
-
Polynomial kernel: (XTL+constant)degree
-
SVM has a convex optimization problem
- 大牛学习博客
*********************************************************************************************************
*********************************************************************************************************
chapter 13 : Unsupervised learning and clustering



*********************************************************************************************************
*********************************************************************************************************
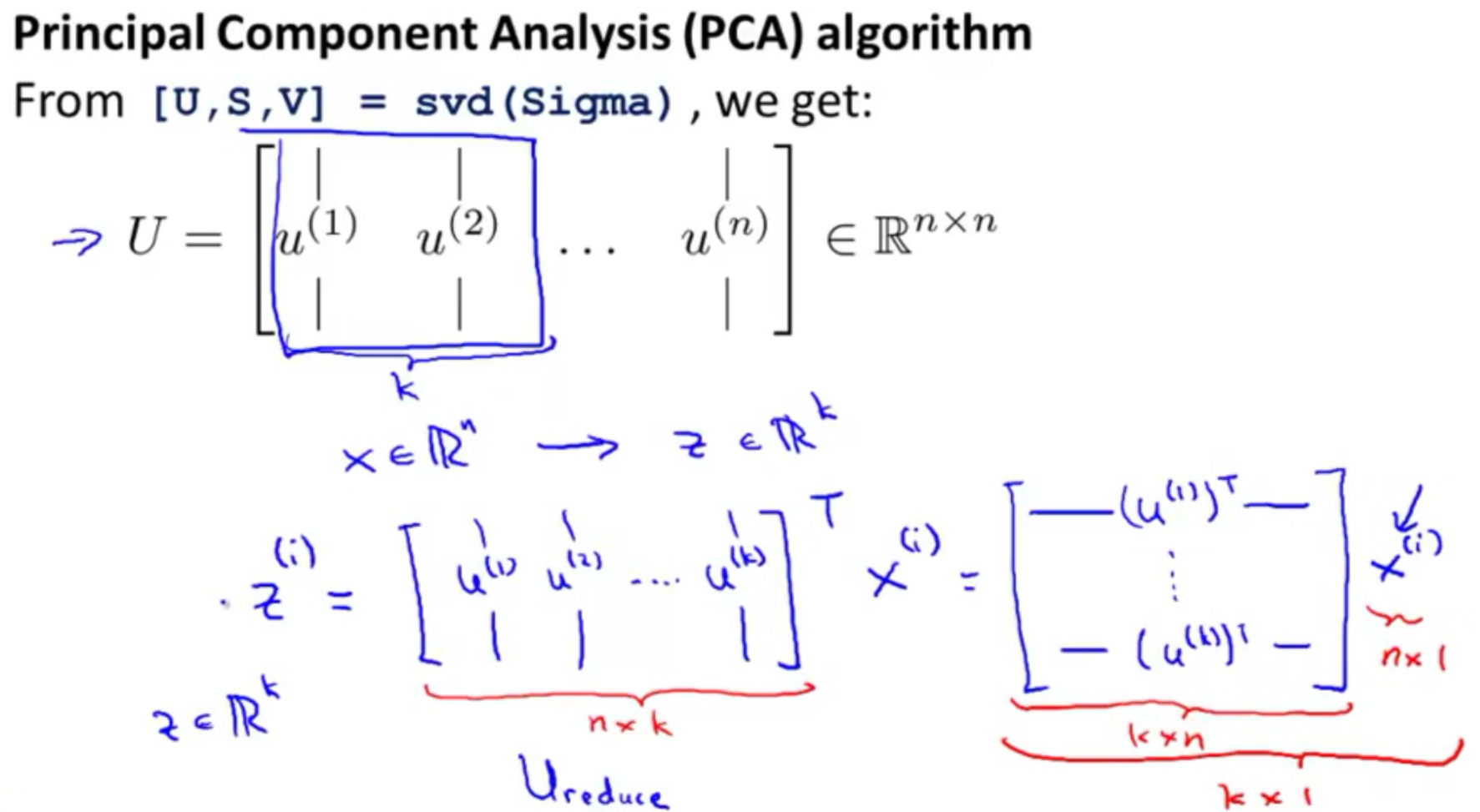
chapter 14 : PCA
- first perform mean normalization and feature scalling so that the feature should have zero mean and comparabel ranges of values.

- Data preprocessing

- PCA and SVD , the implementation of PCA , the choosing of K



-
getting the PCA parameter only on the training set and use them on the test and cross validation set



chapter 15 :