我们在安装数据库(DBMS)的时候,选择了数据库服务器的默认码表,一般都是选择 UTF8 ;
我们查询我们的数据库服务器的默认码表,我的是 UFT8 :
mysql> show variables like 'character_set%' ;
+--------------------------+--------------------------+
| Variable_name | Value |
+--------------------------+--------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | D:mysqlsharecharsets |
+--------------------------+--------------------------+
8 rows in set
而我们的客户端,使用黑窗口的时候,默认码表是 GBK ,这是改不掉的,跟着系统走的 ;
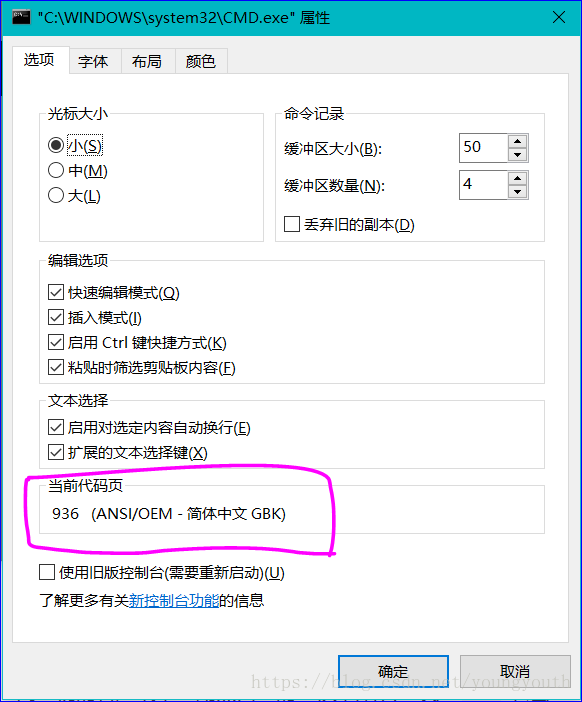
这样就造成 ,我们插入中文,在数据库的表中是乱码 ;
原因很简单:就是解码编码的问题;
首先,我们客户端将中文按照 GBK 编码成 0101010 ,然后传递给服务器,服务器收到这串 010101010 以后,服务器按照 UTF8 解码,就出现乱码了;
客户端的码表,我们无法更改(仅局限在dos窗口下),我们改下服务器对客户端默认的码表;
# 告诉 服务器 ,客户端的码表是 gbk ;
mysql> set character_set_client = gbk ;
Query OK, 0 rows affected
mysql> show variables like 'character_set%';
+--------------------------+--------------------------+
| Variable_name | Value |
+--------------------------+--------------------------+
| character_set_client | gbk | --- 服务器对客户端的码表已经变为 gbk ;
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | D:mysqlsharecharsets |
+--------------------------+--------------------------+
8 rows in set
这时候,插入中文 ,我们就不会出现乱码了;
但是,当我们进行查询的时候,我们发现又出现乱码了 ;
原因很简单:还是解码编码的问题;
首先,我们客户端将中文按照 GBK 编码成 0101010 ,然后传递给服务器,服务器收到这串 010101010 以后,服务器按照 GBK 解码,保存;当进行查询的时候,服务器按照他的配置文件,就是刚刚那一串码表 ,发现需要按照 UTF8 解码,然后传给客户端,但是客户端收到以后 ,是按照 GBK 解码的,这时候,乱码又出现了!
解决方法,我们只需要再次告诉服务器,客户端查询结果的码表也是 GBK ;
# 告诉 服务器,给我以 GBK的形式显示结果,我只认识GBK
mysql> set character_set_results = gbk ;
Query OK, 0 rows affected
mysql> show variables like 'character_set%';
+--------------------------+--------------------------+
| Variable_name | Value |
+--------------------------+--------------------------+
| character_set_client | gbk |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | gbk | -- 改变默认码表了;
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | D:mysqlsharecharsets |
+--------------------------+--------------------------+
8 rows in set
这样查询就不会出现问题了 !
上面的两次命令,可以使用一个命令解决 ;
# 这句话,会将 character_set_client,character_set_connection ,character_set_database 都设置 ;
mysql> set names gbk ;
Query OK, 0 rows affected
mysql> show variables like 'character_set%';
+--------------------------+--------------------------+
| Variable_name | Value |
+--------------------------+--------------------------+
| character_set_client | gbk |
| character_set_connection | gbk |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | gbk |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | D:mysqlsharecharsets |
+--------------------------+--------------------------+
8 rows in set
但是上面的设置,仅对一次连接起作用,下次重新连接,服务器的默认码表,又会变成我们安装的时候选择的码表了!
一般在开发中,在 IDE 中选择 UTF8 ,就可以避免这种乱码了 ;
备注:
当数据被正确的存进数据库的时候,我们可以随意的修改客户端码表,数据库都会正确的给我们进行转换,它内置了 39 张码表 ;
mysql> show character set ;
+----------+-----------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+-----------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| binary | Binary pseudo charset | binary | 1 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
+----------+-----------------------------+---------------------+--------+
36 rows in set