集合框架概述
面向对象语言对事物的体现都是一对象的形式,为方便对多个对象的操作,就要对对象进行存储。另一方面,使用Array存储对象方面具有一些弊端,而Java集合就像一种容器,可以动态的把多个对象的应用放入容器中
数组再内存存储方面的特点
数组初始化以后,长度就确定了
数组声明的类型,就决定了进行元素初始化的类型
数组在存储数据方面的弊端
数组初始化以后,长度就不可变了,不便于扩展
数组中提供的属性和方法少,不便于进行添加、删除、插入等操作,且效率不高。同时无法直接获取存储元素的个数
数组存储的数据是有序的、可以重复的
Java集合类可以用于存储数量不等的多个对象,还可以用于保存具有映射关系的关联数组
集合的两种体系

Collection接口
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和Queue集合
JDK不提供此接口的任何形式实现,而是提供风积体的子接口(如:Set和List)实现
在Java5之前,Java集合会丢失容器中所有对象的数据类型,把所有对象都当初Object类型除了;从JDK5.0增加了泛型以后,Java集合可以记住容器中对象的数据类型
Collection接口方法
Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合。方法如下:
public boolean add(E e): 把给定的对象添加到当前集合中public void clear():清空集合中所有的元素public boolean remove(E e): 把给定的对象在当前集合中删除public boolean contains(E e): 判断当前集合中是否包含给定的对象public boolean isEmpty(): 判断当前集合是否为空public int size(): 返回集合中元素的个数public Object[] toArray(): 把集合中的元素,存储到数组中
import java.util.ArrayList;
import java.util.Collection;
public class Demo1Collection {
public static void main(String[] args) {
// 创建集合对象
// 使用多态形式
Collection<String> coll = new ArrayList<String>();
// 使用方法
// 添加功能 boolean add(String s)
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
System.out.println(coll);
// boolean contains(E e) 判断o是否在集合中存在
System.out.println("判断 扫地僧 是否在集合中"+coll.contains("扫地僧"));
//boolean remove(E e) 删除在集合中的o元素
System.out.println("删除石破天:"+coll.remove("石破天"));
System.out.println("操作之后集合中元素:"+coll);
// size() 集合中有几个元素
System.out.println("集合中有"+coll.size()+"个元素");
// Object[] toArray()转换成一个Object数组
Object[] objects = coll.toArray();
// 遍历数组
for (int i = 0; i < objects.length; i++) {
System.out.println(objects[i]);
}
// void clear() 清空集合
coll.clear();
System.out.println("集合中内容为:"+coll);
// boolean isEmpty() 判断是否为空
System.out.println(coll.isEmpty());
}
}
迭代器(Iterator)
1.Iterator对象称为迭代器(设计模式的一种),主要用于遍历Collection集合中的元素
2.GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生。
3.Clooection接口继承了java.lang.Iterable接口,该接口有一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象
4.Iterator仅用于遍历集合,Iterator本身并不提供承装对象的能力。如果需要创建Iterator对象,则必须有一个被迭代的集合
5.集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前
迭代器(Iterator)的方法
Java中的Iterator功能比较简单,并且只能单向移动:
①使用方法Iterrator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:Iterator()方法时java.lang.
②使用next()获得序列中的下一个元素
③使用hasNext()检查列表中是否还有元素
④使用remove()将迭代器新返回的元素删除
Iterator的接口定义:
public interface Iterator{
boolean hasNext();
Object next();
void remove;
}
迭代器(Iterator)应用
public class IteratorDemo {
public static void main(String[] args) {
// 使用多态方式 创建对象
Collection<String> coll = new ArrayList<String>();
// 添加元素到集合
coll.add("串串星人");
coll.add("吐槽星人");
coll.add("汪星人");
//遍历
//使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator<String> it = coll.iterator();
// 泛型指的是 迭代出 元素的数据类型
while(it.hasNext()){ //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
}
}
注意:
iterator可以删除集合的元素,但是是遍历过程中通过迭代器对象的remove方法,不是集合对象remove方法
如果还未调用next()或在上一次调用next方法之后已经调用remove方法,再调用remove都会报
IllegalStateException。
增强For循环(for each)
增强for循环(也称for each循环)是**JDK1.5**以后出来的一个高级for循环,专门用来遍历数组和集合的。它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
格式:
for(元素的数据类型 变量 : Collection集合or数组){
//写操作代码
}
//它用于遍历Collection和数组。通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
练习:遍历数组
public class NBForDemo1 {
public static void main(String[] args) {
int[] arr = {3,5,6,87};
//使用增强for遍历数组
for(int a : arr){//a代表数组中的每个元素
System.out.println(a);
}
}
}
练习:遍历集合
public class NBFor {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<String>();
coll.add("小河神");
coll.add("老河神");
coll.add("神婆");
//使用增强for遍历
for(String s :coll){//接收变量s代表 代表被遍历到的集合元素
System.out.println(s);
}
}
}
> tips: 新for循环必须有被遍历的目标。目标只能是Collection或者是数组。新式for仅仅作为遍历操作出现。
Collection子接口之一:List接口
List集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引
List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素
JDK API中List接口的实现类常用的又:ArrayList、LinkedList和Vector
List接口方法
void add(int index, Objec ele) : 在index位置插入ele元素
boolean addAll(int index, Collection eles) : 从index位置开始将eles中的所有元素添加进来
Object get(int index) : 获取指定index位置的元素
int indexOf(Object obj) : 返回obj在集合中首次出现的位置
int lastIndexOf(Object obj) : 返回obj在当前集合中末次出现的位置
Object remove(int index) : 移除指定index位置的元素,并返回此元素
Object set(int index, Object ele) : 设置指定index位置的元素为ele
List subList(int fromIndex, int toIndex) : 返回从fromIndex到toIndex位置的子集合
List实现类ArrayList
ArrayList是List接口的典型实现类、主要实现类
本质上,ArrayList是对象引用的一个“变长”数组
ArrayList是JDK1.8之前与之后的实现区别
JDK1.7:ArrayList是直接创建一个初始容量为10的数组
JDK1.8:ArrayList一开始创建一个长度为0的数组,当添加一个元素时再创建一个初始容量为哦10的数组
Arrays.asList()方法返回的List集合,既不是ArrayList实例,也不是Vector实例。Arrays.asList()返回值是一个固定长度的List集合
List实现类LinkedList
对于频繁插入或删除元素的操作,建议使用LinkedList类,效率较高
新增方法
void addFrist(Object obj)
void addLast(Object obj)
Object getFirst()
Object getLast()
Object removeFirst()
Object RemoverLast
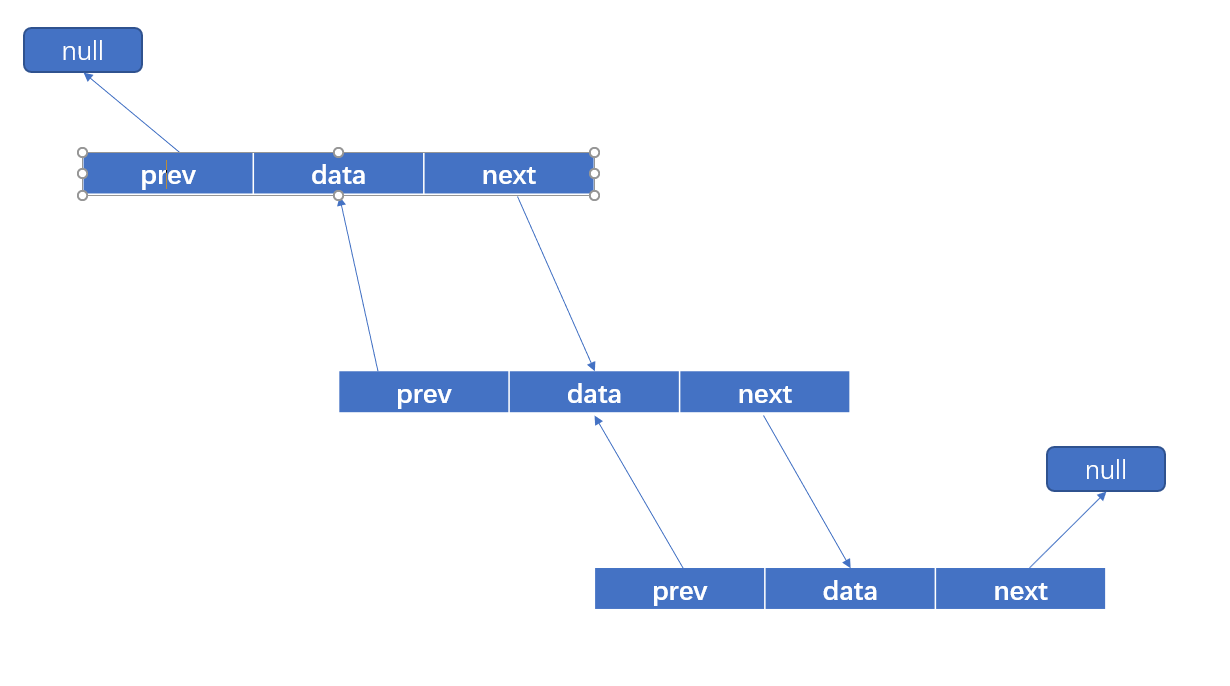
LinkedList:双向链表,内部没有声明数组,而是定义了Node类型的first和last,用于记录首末元素。同时定义内部类Node,作为LinkedList中保存数据的基本结构。Node除了保存数据,还定义了两个变量:
prev变量记录前一个元素的位置
next变量记录后一个元素的位置
private static class Node<E>{
e item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next){
this.item = element;
this.next = next;
this.prev = prev;
}
}
List实现类Vector
Vector是一个古老的集合,JDK1.0就有了,大多数操作与ArrayList相同,区别之处在于Vector是线程安全的
在各种list中,最好把ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList;Vector总是比ArrayList慢,所以尽量避免使用。
新增方法
void addElement(Object Obj)
void insertElementAt(Object obj,int index)
void setElementAt(Object obj,int index)
void removeElement(Object obj)
void removeAllElements()
ArrayList和LinkedList的异同
二者都是线程不安全的,相比于线程安全的Vector,执行效率高
此外,ArrayList是实现了基于动态数组的数组结构,LinkedList基于链表的数据结构。对于随机访问get和set,ArrayList觉得由于LinkedList,
应为Linked要移动指针。对于新增和删除操作add(特指插入)和remove,LinkedList比较占优势,因为ArrayList要移动数据
ArrayList和Vector的区别
Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized),属于强同步类。因此开销就比ArrayList要大,访问要慢。
正常情况下,大多数的Java程序员使用ArrayList而不是Vector,因为同步完全可以由程序员自己来控制。Vector每次扩容请求其大小的2倍空间,而ArrayList是1.5倍空间。Vector还有一个子类Stack。
Collection子接口之二:Set接口
Set集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set集合中,则添加操作失败
Set判断两个对象是否相同不是使用==运算符,而是根据equals()方法
Set实现类之一:HashSet
HashSet是Set接口的典型实现,大多数时候使用Set集合时都使用这个实现类
HashSet按Hash算法来存储集合中的元素,因此具有很好的存取、查找、删除性能
HashSet具有以下特点:
不能保证元素的排列顺序
HashSet不是线程安全的
集合元素可以是null
HashSet集合判断两个元素相等的标准:
两个对象通过hashCode()方法比较相等,并且两个对象的equals()方法返回值也相等
对于存放Set容器中的对象,对应的类一定要从重写equals()和hashCode(Object obj)方法,以实现对象相等规则。即:”相等的对象必须具有相等的散列码“。
向HashSet中添加元素的过程:
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据hashCode值,通过某种散列函数决定该对象在HashSet底层数组中的存储位置。(这个散列函数会与底层数组的长度相计算得到在数组中的下标,并且这种散列函数计算还尽可能保证能均匀存储元素,越是散列分布,改散列函数设计的越好)
如果两个元素的hashCode()值相等,会再继续调用equals方法,如果equals方法结果为true,添加失败;如果为false,那么会保存该元素,但是该数组的位置已经有元素了,那么会通过链表的方式继续链接。
如果两个元素的equals()方法返回true,那么它们的hashCode()返回值不相等,hashSet将会把它们存储在不同的位置,但依然可以添加成功。

重写hashCode()方法的基本原则
在程序运行时,同一个对象多次调用hashCode()方法应该返回相同的值
当两个对象的equals()方法比较返回true时,这两个对象的hashCode()方法的返回值也应相等
对象中用作equals()方法比较Field,都应该用来计算hashCode值
** 重写equals()方法的基本原则**
以自定义的Customer类为例,何时需要重写equals()?
当一个类有自己特有的“逻辑相等”概念,当改写equals()的时候,总是
要改写hashCode(),根据一个类的equals方法(改写后),两个截然不
同的实例有可能在逻辑上是相等的,但是,根据Object.hashCode()方法,
它们仅仅是两个对象。
因此,违反了“相等的对象必须具有相等的散列码”。
结论:复写equals方法的时候一般都需要同时复写hashCode方法。通
常参与计算hashCode的对象的属性也应该参与到equals()中进行计算。
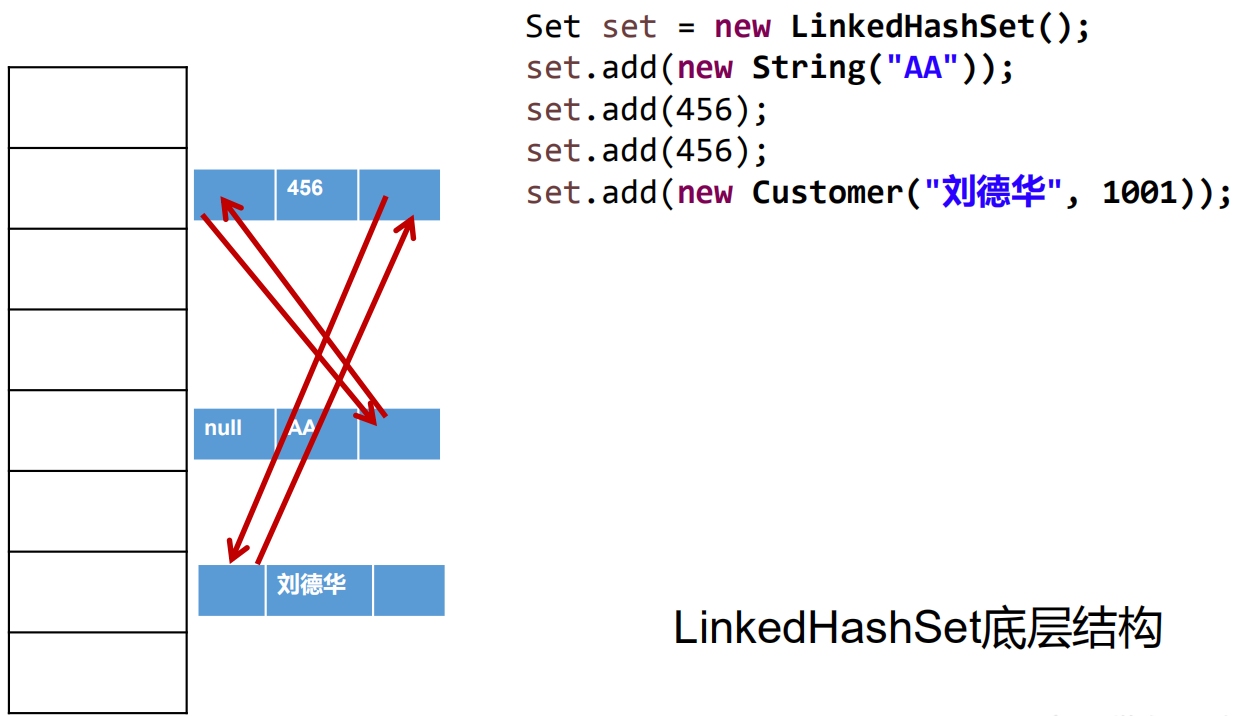
Set实现类之二:LinkedHashSet
LinkedHashSet 是 HashSet 的子类
LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,
但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能。
LinkedHashSet 不允许集合元素重复。