转自 https://blog.csdn.net/sinat_17697111/article/details/112677304
Presto Web UI 可以用来检查和监控Presto集群,以及运行的查询。他所提供的关于查询的详细信息可以更好的理解以及调整整个集群和单个查询。
需要注意的是,Presto Web UI所展示的信息都来自于Presto系统表,关于Presto系统表之后文章中再补充,这里不再多说;
当你进入Presto Web时,你将会看到如同1所示的界面:主要分为上下两部分,上面描述了集群信息,下面是查询列表;
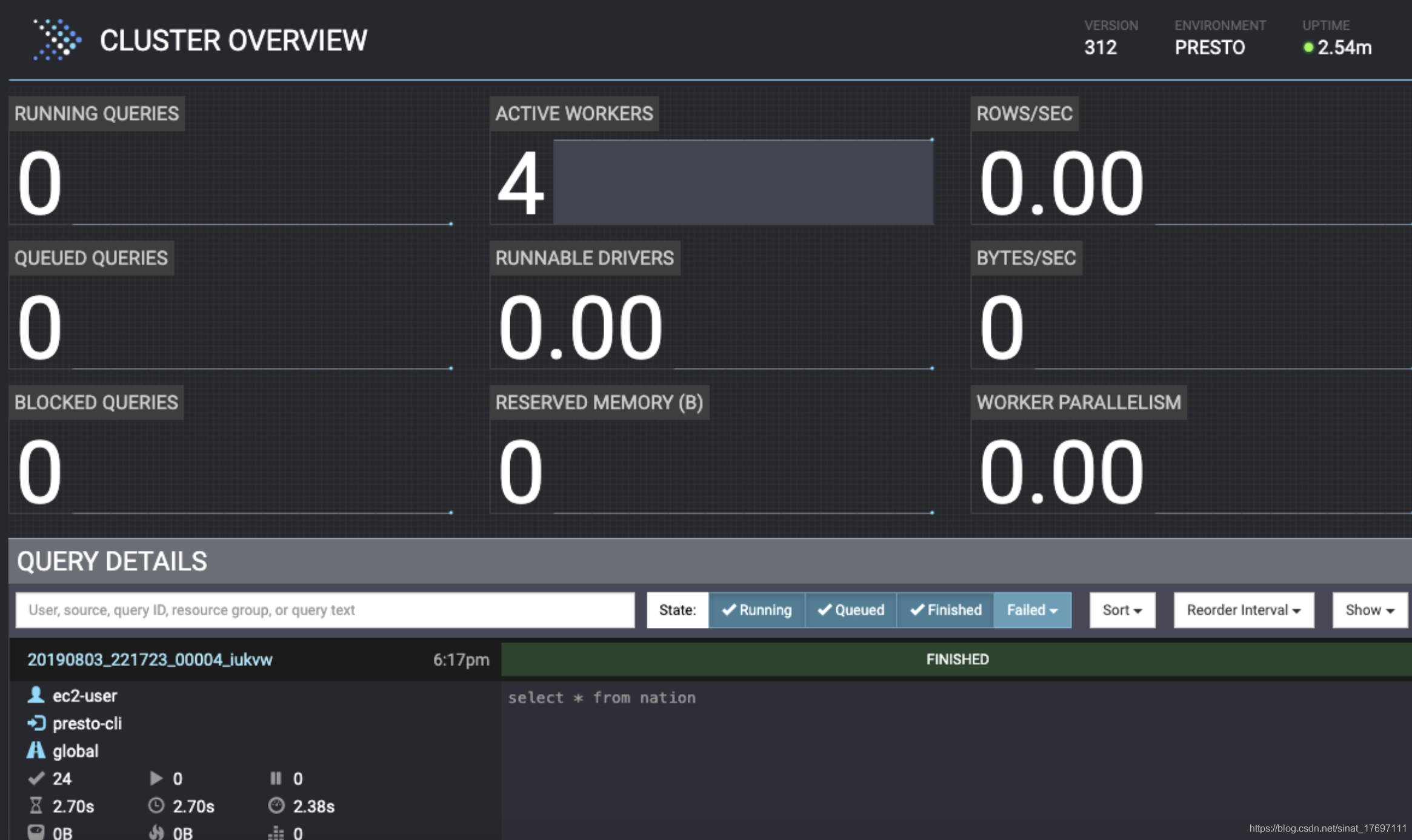
首页
集群信息
Running Queries
当前在集群中正在执行的查询的个数。包含所有用户提交的查询;例如,如果Alice正在执行两个查询,Bob正在执行五个查询,那么在这个指标下显示的是7。
Queued Queries
当前集群队列中正在等待的查询的个数,也是包含所有用户的查询。队列中的查询表示这些查询正在等待Coordinator根据Resource Group的配置为他们安排调度;
Blocked Queries
集群中被阻塞的查询的个数;被阻塞的查询意味着该查询因为缺少可用的Splits或者资源而无法继续执行(关于Splits的概念 以及查询何时被阻塞可以参考上一篇文章:Presto On Everything);
Active Workers
集群中当前活跃的节点的个数;任何手动会自动添加或删除的节点都会注册到Discovery 服务,同时这里展示的数字将会更新、
Runnable Drivers
集群中可运行的Drivers的平均数量(当Task被创建之后,他为每一个Split实例化一个Driver,每一个Driver就是一个Pipeline 中Operators的实例,并对来自Split的数据进行处理,一旦Driver完成,数据将会被传给下一个Split),
Reserved Memory
集群中Reserved Memory的大小,单位是bytes。(关于Reserved Memory的概念请参考上一篇文章:Presto On Everything)
Rows/Sec
集群中所有查询在每一秒钟处理的行数
Bytes/Sec
集群中所有查询在一秒钟处理的总共的Bytes
Worker Parallelism
Worker的并发总数,在集群中运行的所有Worker和所有查询的CPU Time总和
查询列表
WBE UI首页下部分就是查询列表的展示,当前列表中可以展示的查询的数量时可以配置的。如图二所示
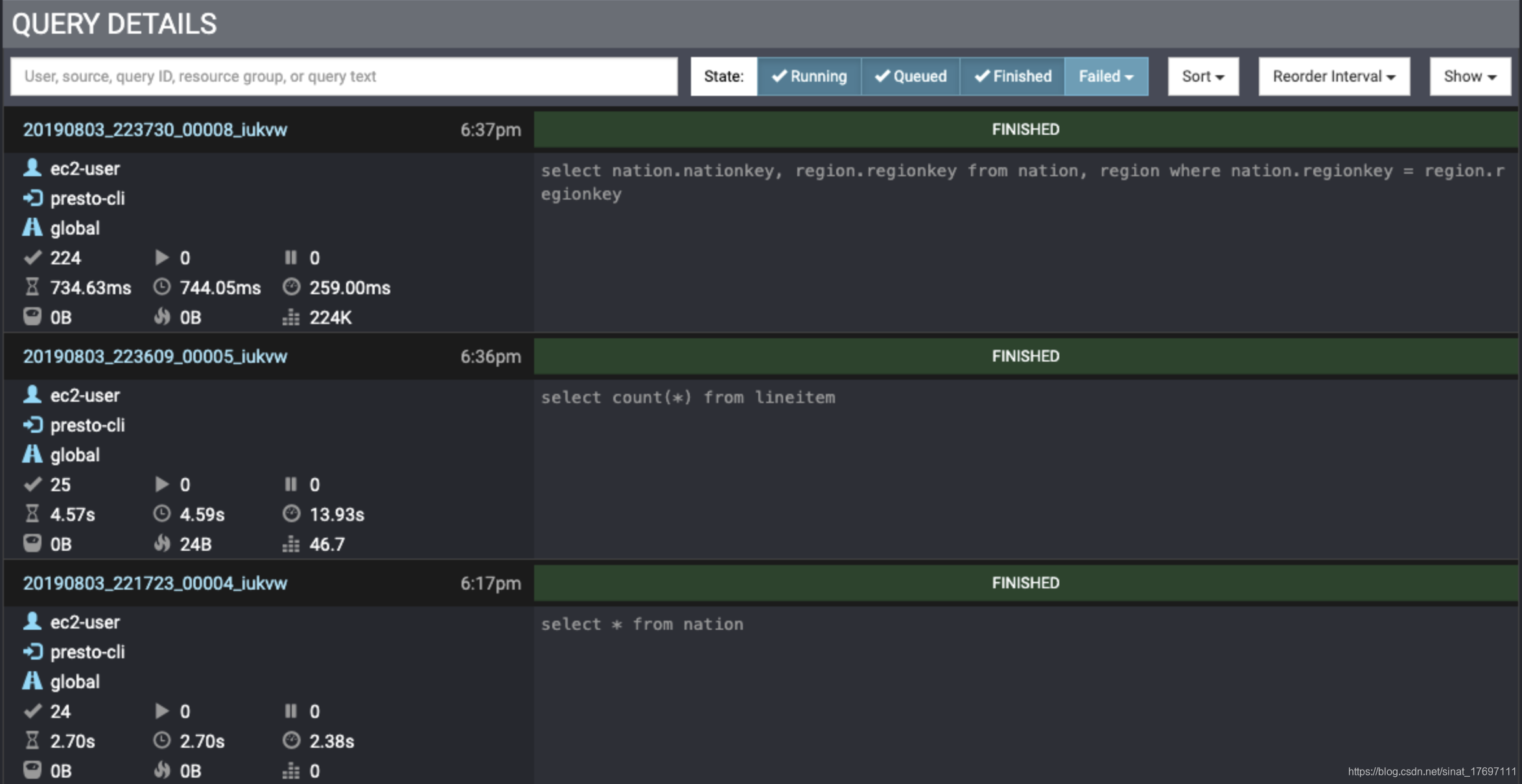
图2
如图所示你可以根据一些条件过滤和定位你想要的查询;同时提供了搜索输入框用于定位查询,输入的值会匹配很多项,包括:用户名、查询发起人,查询source,查询ID,resource group甚至SQL文本,和查询状态。同样你可以根据后面预设的一些状态(running, queued, finished, and failed)对查询进行筛选;
最左边的控件允许你确定显示的查询的排序顺序、重新排序的时间以及要显示的查询的最大数量。
下面的每一行表示一个查询,左侧如图三所示,右侧为查询的SQL文本;
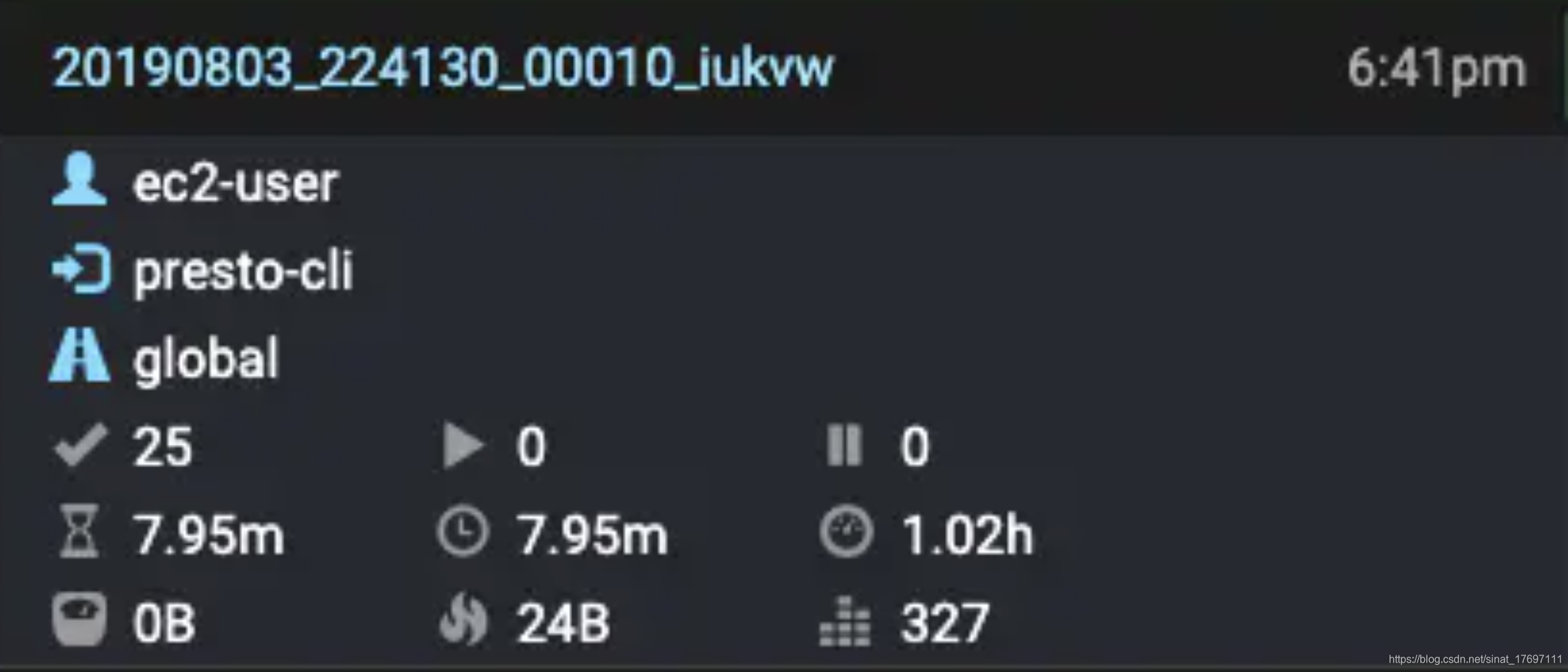
图3.png
根据图三可以观察当前查询的细节; 对于每个查询运行,左上角的文本是查询ID,图三中为:20190803_224130_00010_iukvw
前面是YYYYMMDD_HHMMSS格式的日期,具体的时间是当前查询运行时的时间,后半部分是一个自增的计数器,00010的含义表示这个查询时Coordinator重启以来第10个查询,最后的字符:iukvw,是随机生成的Coordinator的标识符,每次coordinator重启会充值标识符和计数器。
后面紧跟的三个值: ec2-user , presto-cli , 以及global 分别表示,提交该查询的用户,查询的来源,当前查询的Resource Group。在实例中,当前查询的用户是ec2-user,查询时通过Presto-cli提交的,如果你在Presto CLI中提交SQL 时使用--user指定用户,那么界面该查询展示的就是你所指定的用户。至于查询来源除了Presto-CLI之外也可以是:Presto-jdbc ,当你使用JDBC连接Presto时。
图三最下面的9个指标对应下面的表格;
Completed Splits: 查询的已完成Splits的数目。这个例子显示了25个已完成的Splits。在查询执行的开始时和执行完成时这个值是0。当查询正在进行期间这个值会一直增加
Running Splits: 查询中正在运行的运行Splits的数量。当查询完成时,这个值总是0。但是,在执行过程中,随着Splits的运行和完成,这个数字会发生变化
Queued Splits: 当前查询里出于队列中的Splits数。当查询完成时,这个值总是0。但是,在执行期间,这个数字会发生变化。
Wall Time: 执行查询所花费的Wall Time。即使在分页结果时,此值也会继续增长。
Total Wall Time: 此值与Wall Time相同,但它也包括排队时间。Wall Time不包括查询排队的任何时间。这是您观察的总时间,从您提交查询到您接收结果。
CPU Time: 处理查询所花费的总CPU时间。这个值通常比wallTine时间大,因为如果使用四个CPU花费1秒来处理一个查询,那么总的CPU时间是4秒。
Current Total Reserved
Memory:当前用于查询执行总的reserved memory使用。对于已完成的查询,此值为0.
Peak Total Memory: 查询执行期间的峰值总内存使用量。查询执行期间的某些操作可能需要大量内存,了解峰值是多大是很有用的
Cumulative User Memory: 在整个查询处理过程中使用的累积内存。这并不意味着所有的内存都是同时使用的。它是累积的内存总量。
Presto Web UI中的许多图标和值都有弹出的工具提示,当您将鼠标悬停在图像上时,这些工具提示是可见的。如果您不确定某个特定值代表什么,这将非常有用。
当正在运行的查询在等待某些东西(如资源或要处理的其他Splits)时可能会发生BLOCKED状态。看到查询往返于此状态是正常的,但是如果查询陷入BLOCKED状态,可能存在许多潜在的理由,这可能表明当前查询或者集群可能存在问题,如果发现有查询卡在这个状态,那么应该检查集群的状态和相关配置,也可能是这个查询需要非常大的内存或者计算开销很大。 此外,如果客户端没有获取到返回的结果,或者不能足够快地读取结果,反压机制也会使查询处于BLOCKED状态
如果查询长时间出于PLANNING状态,这通常发生在较大的复杂的查询中,因为查询要进行大量的规划和优化处理;但是如果你经常看到这个状态,并且查询出于该状态很长时间,那很可能是因为coordinator内存问题导致的(之前曾遇到过因HiveMetaStore服务而导致的长时间的PLANNING状态)。
查询明细视图:
通过点击查询ID可以跳转到该查询的明细界面,如图四所示

图4.png
Overview页面包括查询列表的查询细节信息如图4.1下:
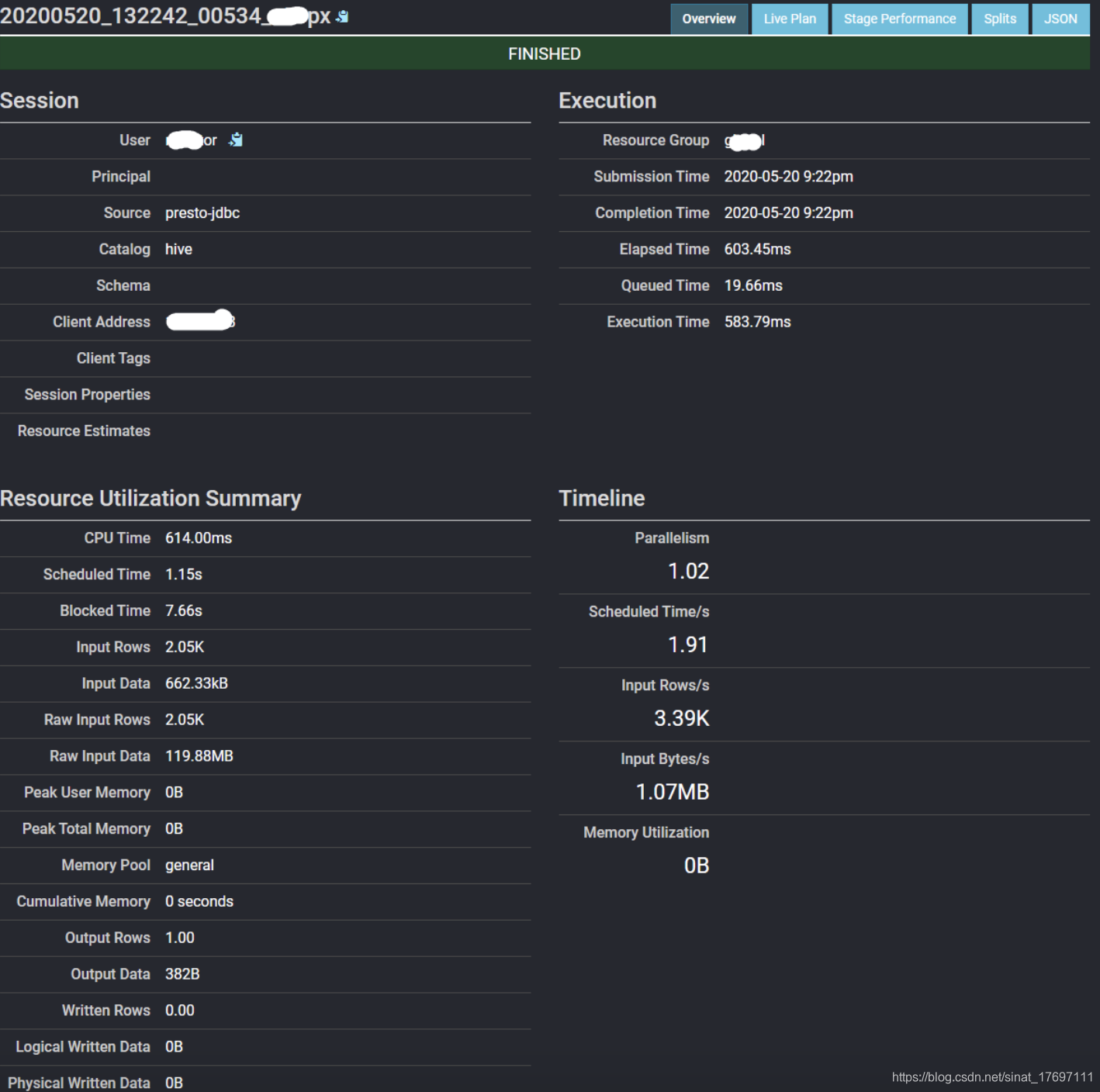
图4.1.png
最下面为Stage部分如图5所示
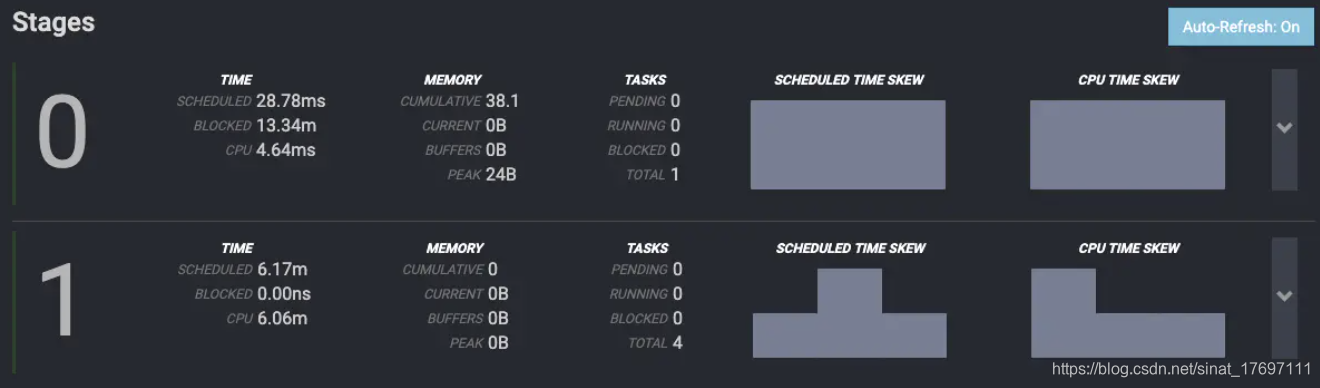
图5.png
这是一个简单的SELECTCOUNT(*)的查询,所以只有两个stages
Stage0 是一个单任务的Stage,运行在coordinator上并且合并来自Stage1的Task(共4个)的数据,以完成最后的聚合;
Stage1是一个分布式的Stage,他在所有的Worker上执行Task,这个Stage负责读取数据并进行部分聚合;
其中每个Stage的指标如下:
TIME—SCHEDULED
在完成Stage的所有Task之前,该Stage被调度的时间。
TIME—BLOCKED
因等待数据被阻塞的时间
TIME—CPU
Stage中所有Task的总共的CPU时间
MEMORY–CUMULATIVE
在整个Stage 运行期间的累积内存。这并不意味着所有的内存都是同时使用的
MEMORY—CURRENT
当前stage总共的reserved内存,当查询结束时,改值为0
MEMORY—BUFFERS
当前正在等待被处理的数据所消耗的内存
MEMORY—PEAK
该Stage的峰值总内存。查询执行期间的某些操作可能需要大量内存,了解峰值是多少是很有用的。
TASKS—PENDING
Stage中待完成的Task的数量,执行完成时,为0
TASKS—BLOCKED
stage阻塞Task的数量。当查询完成时,这个值总是0。但是,在执行过程中,随着Task在阻塞状态和运行状态之间移动,这个数字会发生变化
TASKS—TOTAL
已经完成的Task的数量
最后的图6描述了Stage更多的细节:
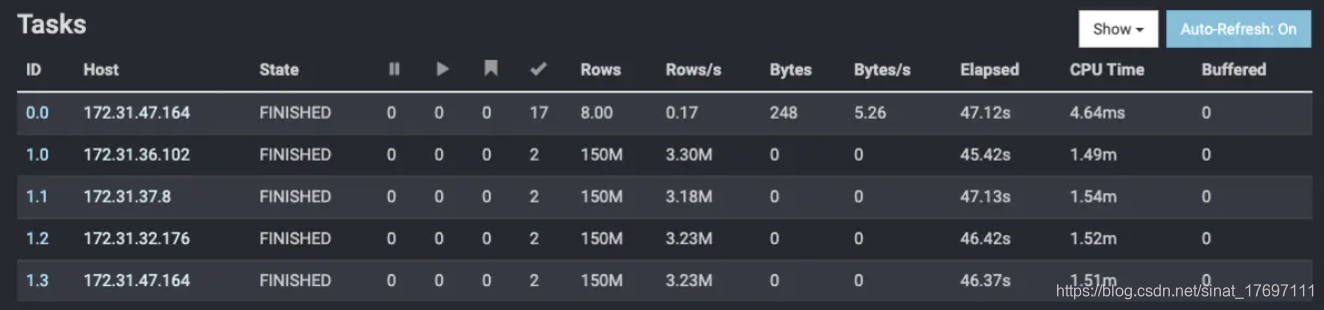
图6.png
如图6中指标具体含义如下表所示:
ID:Task的标识符,StageID.TaskID,中间用点分割,如0.0即Stage0的第0个任务
Host:Task运行所在的Worker节点
State :Task的状态:PENDING , RUNNING , or BLOCKED
Pending Splits:Task的挂起的Splits的数量。此值在Task运行时更改,并在Task完成时显示0
Running Splits:Task 中正在运行的Splits的数量,在Task运行时改变,Task完成后显示0
Blocked Splits:Task 中出于阻塞状态的任务数,Task完成后为0
CompletedSplits:Task完成的Splits的数量
Rows:Task处理的行数
Rows/s:每秒处理的行数
Bytes:Task处理的字节数
Bytes/s:Task每秒处理的字节数 |
Elapsed:Task调度期间 wall time的总和
CPU Time:Task调度期间CPU时间总和
Buffered:当前等待被处理的缓存数据大小
执行计划(Live Plan)
Live Plan页面中你可以实时查询执行处理过程;如图7所示
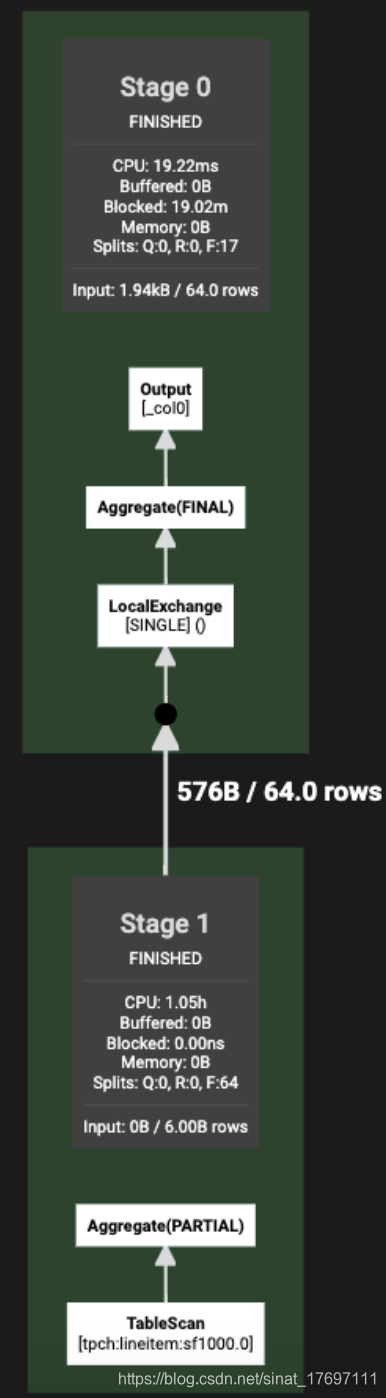
图7.png
在查询执行期间,计划中的计数器在查询执行过程中更新。Plan中的值与Overview选项卡中描述的相同,但是它们在查询执行计划上实时覆盖。 查看此视图有助于可视化查询被阻塞或花费大量时间的位置,以便诊断或改进性能问题
Stage Performance
Stage Performance提供了查询处理完成后Stage 性能的详细可视化。如图8所示
该视图可以看作是Live Plan视图的下钻,在Live Plan视图中可以看到Stage中Task的operator pipeline。计划中的值与Overview选项卡中描述的值相同。 查看此视图有助于了解查询在何处卡住或花费大量时间,以便诊断或修复性能问题。您可以单击每个operator来访问详细信息
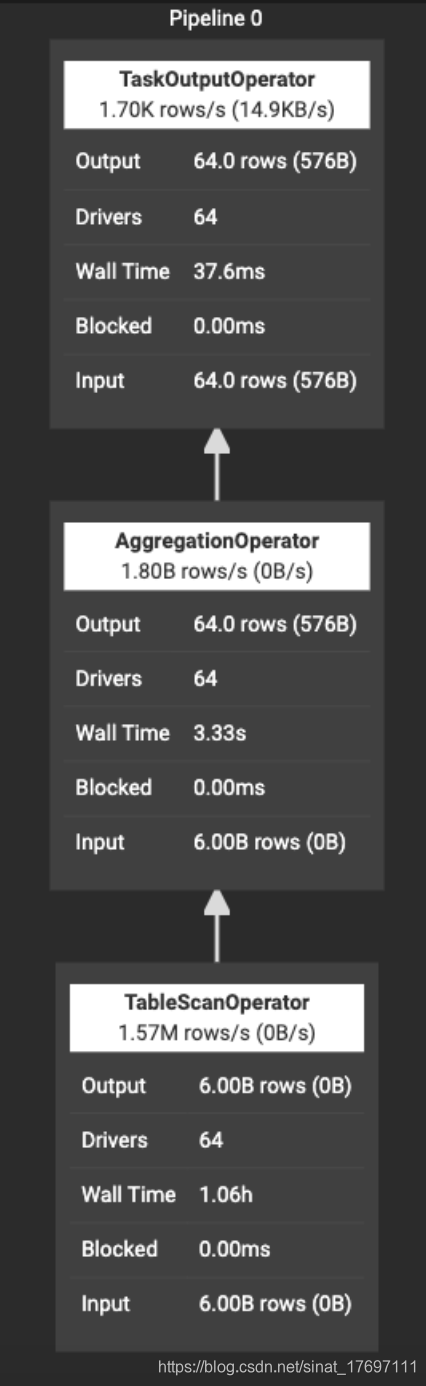
图8.png