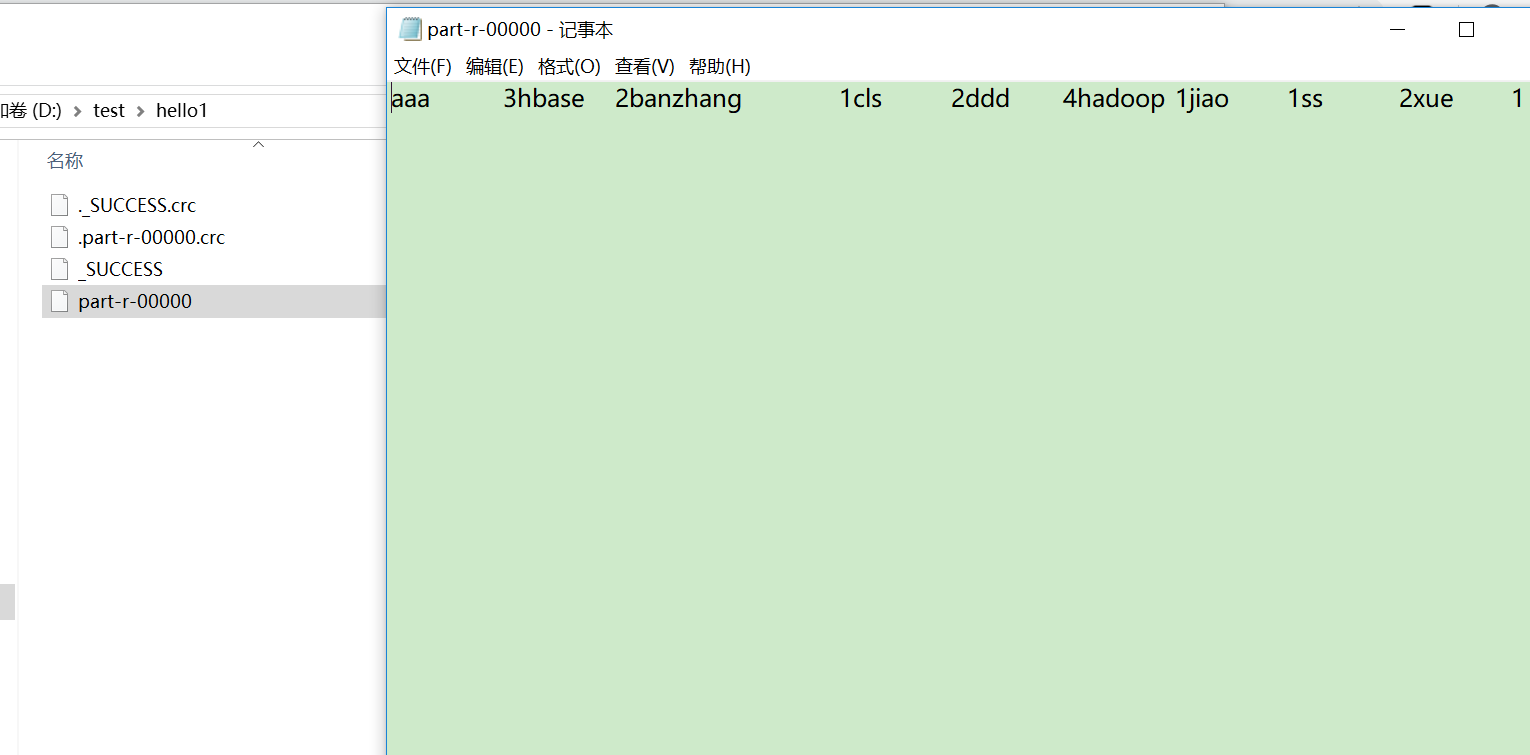
程序的功能:假设现在有n个文本,WordCount程序就是利用MR计算模型来统计这n个文本中每个单词出现的总次数。
1.创建maven工程导入依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
2.编写WordcountMapper实现类,需要继承Mapper类
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 切割 String[] words = line.split(" "); // 3 输出 for (String word : words) { k.set(word); context.write(k, v); } } }
3.编写WordcountReducer实现类,需要继承Reducer类
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ int sum; IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { // 1 累加求和 sum = 0; for (IntWritable count : values) { sum += count.get(); } // 2 输出 v.set(sum); context.write(key,v); } }
4.编写WordcountDriver驱动类
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordcountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1 获取配置信息以及封装任务 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 设置jar加载路径 job.setJarByClass(WordcountDriver.class); // 3 设置map和reduce类 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); // 4 设置map输出 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5 设置最终输出kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6 设置输入和输出路径 FileInputFormat.setInputPaths(job, new Path("d:/test/hello.txt")); FileOutputFormat.setOutputPath(job, new Path("d:/test/hello1")); // 7 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
5.运行结果,自动生成d:/test/hello1目录,如果目录存在会抛出异常
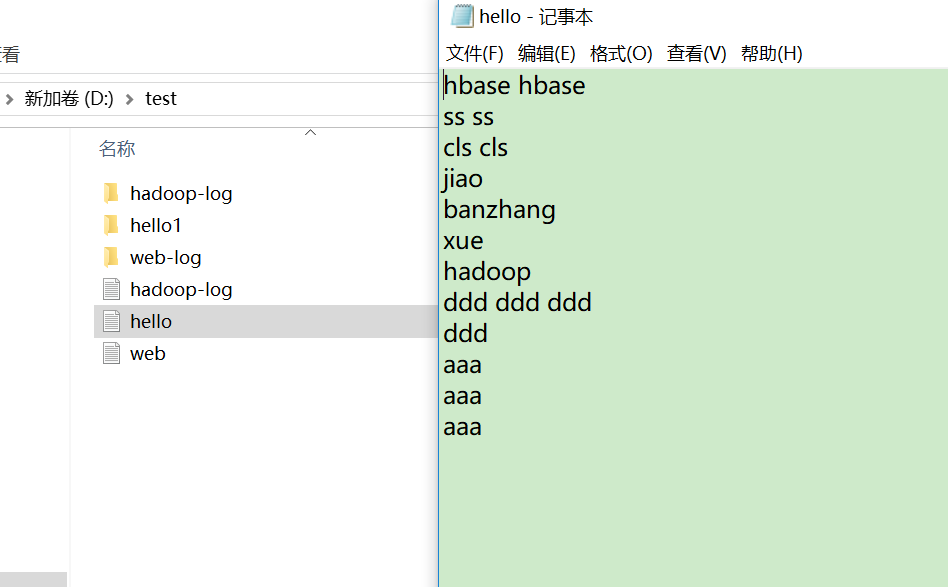
下图是输入数据
下图是统计结果