Impala简介
一:什么是Impala?
Impala是用于处理存储在Hadoop集群中的大量数据的SQL查询引擎。它是一个用C ++和Java编写的开源软件。换句话说,Impala是性能最高的SQL引擎,它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
二:Impala的特点是什么?
1. Impala支持内存中数据处理,即,它访问/分析存储在Hadoop数据节点上的数据,而无需数据移动。
2.与其他SQL引擎相比,Impala为HDFS中的数据提供了更快的访问。
3.使用Impala,可以访问不同的数据存储,如HDFS,Apache HBase
4.Impala支持各种文件格式,如LZO,序列文件,Avro,RCFile和Parquet。
5.Impala使用Apache Hive的元数据,ODBC驱动程序和SQL语法。
6.C++编写,LLVM(构架编译器)统一编译运行用于优化以任意程序语言编写的程序的编译时间、链接时间、运行时间以及空闲时间,对开发者保持开放,并兼容已有脚本
三:Impala的核心组件:
1、Impala Statestore
负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息,而且还负责query的调度分配
2、Impala Catalog
分发表的元数据信息到各个impalad中
接收来自statestore的所有请求
3、Impala Daemon
接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
子节点上的守护进程,负责向statestore保持通信,汇报工作
四:Impala的组成部分?
Impala由以下的组件组成:
1、Clients – Hue、ODBC clients、JDBC clients、和Impala Shell都可以与Impala进行交互,这些接口都可以用在Impala的数据查询以及对Impala的管理。
2、Hive Metastore(元数据) 存储Impala可访问数据的元数据。例如,这些元数据可以让Impala知道哪些数据库以及数据库的结构是可以访问的,当你创建、删除、修改数据库对象或者加载数据到数据表里面,相关的元数据变化会自动通过广播的形式通知所有的Impala节点,这个通知过程由catalog service完成。

3、Cloudera Impala – Impala的进程运行在各个数据节点(Datanode)上面。每一个Impala的实例都可以从Impala client端接收查询,进而产生执行计划、协调执行任务。数据查询分布在各个Impala节点上,这些节点作为worker(工作者),并行执行查询。
4、HBase和HDFS – 存储用于查询的数据。
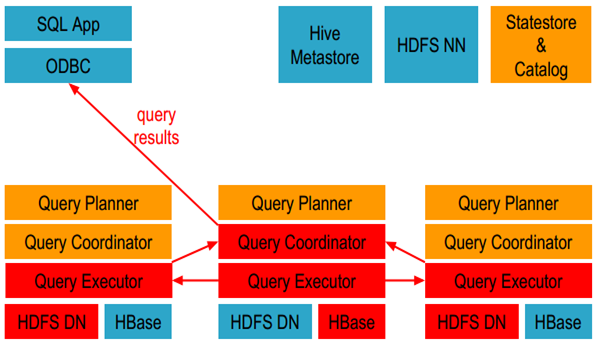
五:Impala执行查询的具体过程:
1、客户端通过ODBC、JDBC、或者Impala shell向Impala集群中的任意节点发送SQL语句,这个节点的impalad实例作为这个查询的协调器(coordinator)。

2、Impala解析和分析这个查询语句来决定集群中的哪个impalad实例来执行某个任务。

3、HDFS和HBase给本地的impalad实例提供数据访问。
4、各个impalad向协调器impalad返回数据,然后由协调器impalad向client发送结果集。
六 Impala的不足之处:
1、不支持用户定义函数UDF。
2、不支持text域的全文搜索。
3、不支持Transforms函数。
4、不支持查询期的容错。
5、对内存要求高。
七 Impala与hive的对比
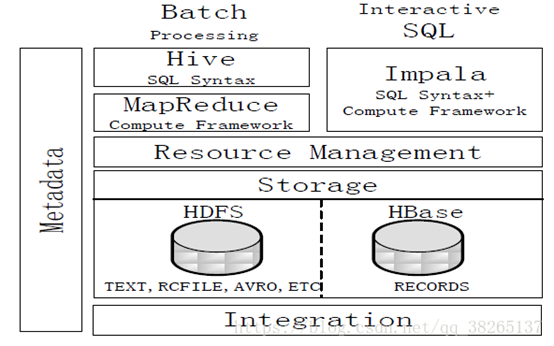
图:Impala与Hive的对比
Hive与Impala的不同点总结如下:
Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询。
Hive依赖于MapReduce计算框架,Impala把执行计划表现为一棵完整的执行计划树,直接分发执行计划到各个Impalad执行查询。
Hive在执行过程中,如果内存放不下所有数据,则会使用外存,以保证查询能顺序执行完成,而Impala在遇到内存放不下数据时,不会利用外存,所以Impala目前处理查询时会受到一定的限制。
Hive与Impala的相同点总结如下:
Hive与Impala使用相同的存储数据池,都支持把数据存储于HDFS和HBase中。
Hive与Impala使用相同的元数据。
Hive与Impala中对SQL的解释处理比较相似,都是通过词法分析生成执行计划。
总结:
Impala的目的不在于替换现有的MapReduce工具。
把Hive与Impala配合使用效果最佳。
可以先使用Hive进行数据转换处理,之后再使用Impala在Hive处理后的结果数据集上进行快速的数据分析