前言:
准备使用selenium爬取网站数据,先搭建selenium+python爬虫环境搭建
系统环境:
64位win10系统,同时装python2.7和python3.6两个版本,IDE为pycharm
安装selenium
进入cmd命令行窗口,敲入以下代码
pip install selenium
python便会自动下载和安装selenium。
接着在python自带的IDLE中敲入
import selenium
如果不报错,则说明selenium安装成功。
Chrome driver安装
在python中使用selenium还需要安装Chrome driver浏览器驱动,首先在网上下载Chrome driver下载地址为:http://www.pc18.com/soft/36193.html#
接着我们把解压后的chromedriver.exe驱动文件复制到chrome浏览器目录下以及python目录下,目录地址分别是C:UsersdellAppDataLocalGoogleChromeApplication和C:UsersdellAppDataLocalProgramsPythonPython36-32,
注意,还需要把第一个浏览器的目录地址添加到系统环境变量中,如下图所示

到现在为止,selenium+python爬虫环境就已经搭建好了
初步使用
我们在IDLE中敲入以下测试代码:
from selenium import webdriver browser = webdriver.Chrome() browser.get('http://www.baidu.com/')
在测试第二行代码的时候,就遇到如下图所示问题

初步判断是计算机防火墙问题所致,接着运行第三行代码,遇到如下图问题:
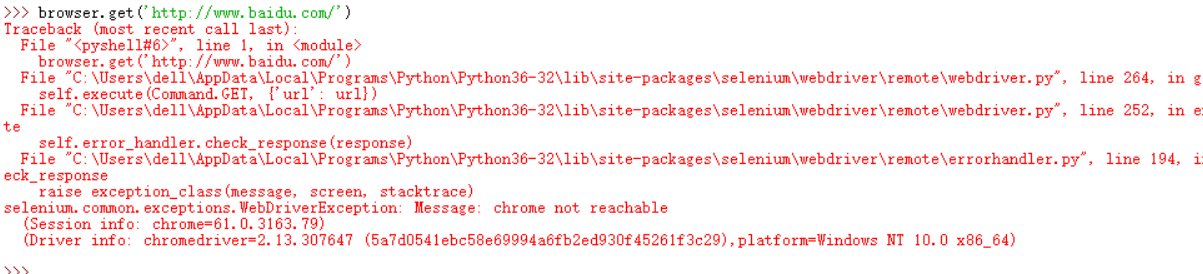
初步判断是上一个问题所致
结论:
selenium+python爬虫环境搭建已基本搭建完成,上述遇到的问题将在解决后上传