2017-10-09 19:06:22
版权声明:本文为博主原创文章,未经博主允许不得转载。
前言:
先获得cookie,然后自动登录豆瓣和新浪微博
系统环境:
64位win10系统,同时装python2.7和python3.6两个版本(本次使用python3.6),IDE为pycharm,浏览器为chorme,使用的python第三方库为requests
查看cookie:
首先登陆豆瓣首页,并且登录账户(注意练习爬虫时最好用小号),右键检查,点击Network,然后按Fn+F5刷新页面,点击最上面的www.douban.com选项,即可找到cookie信息
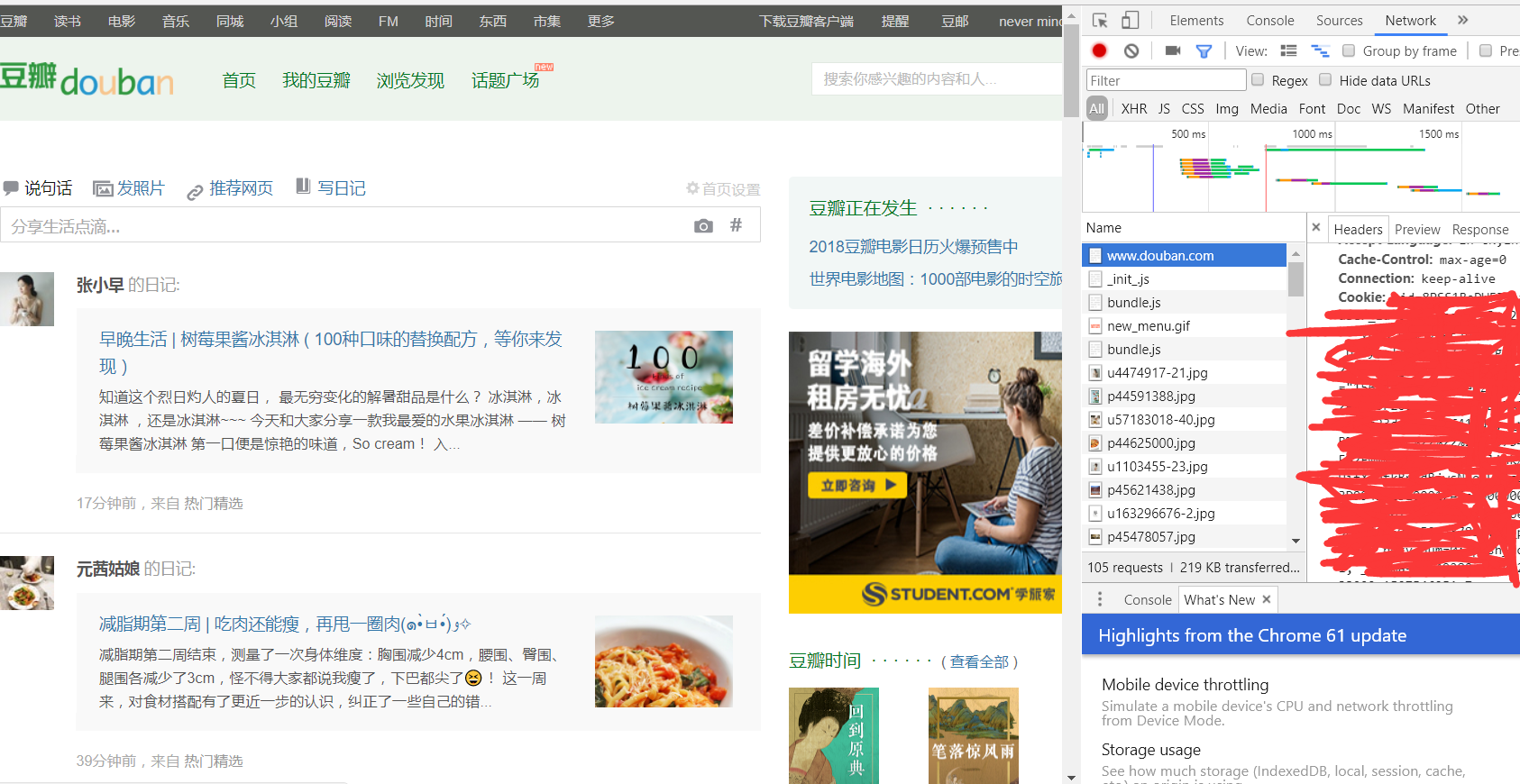
登录:
复制cookie到如下代码中:
import requests headers = {'User-Agent': ''} cookies = {'cookie': ''} url = 'http://www.douban.com' r = requests.get(url, cookies = cookies, headers = headers) with open('douban_2.txt', 'wb+') as f: f.write(r.content)
注意:User-Agent也用如上方式获取并复制到代码中
运行代码,即可在脚本文件目录下找到"douban_2.txt"的text文件,里面是豆瓣登录主页的源代码。