论文全名:Detecting Text in Natural Image with Connectionist Text Proposal Network
1.摘要
(1)本文提出新型网络CTPN,用于自然图像中的文本行定位。CTPN直接在卷积特征映射中的一系列细粒度文本提议中检测文本行。(创新一)开发了一个垂直锚点机制,联合预测每个固定宽度提议的位置和文本、非文本的分数。(创新二)序列提议通过循环神经网络自然连接起来,该网络无缝的结合到卷积网络中,从而形成可训练的端到端模型。
2.引言
(1)图像文字检测的应用:图像OCR、多语言翻译、图像检索等。包括检测和识别两个任务,本文聚焦检测任务。由于文本模式的大变化以及背景的高度杂乱,使得检测任务一般比文字识别任务难度更大。
(2)传统使用自下而上的方式,从低级别字符和笔画检测开始,步骤繁琐,现在普遍被神经网络所代替,无需自行查找特征。
(3)目前主流的方法Faster-RCNN虽然用于一般目标检测效果良好,但是用在文本检测上并不令人满意。第一:主要由于文本的长度往往都是难以固定,不像一般物体一般都是有相对较固定额边界框;第二:一般物体IOU>0.5可能就可以识别出物体的种类,而文字识别需要更精确的IOU,因为仅仅大于0.5可能根本无法识别出文字。
3.贡献
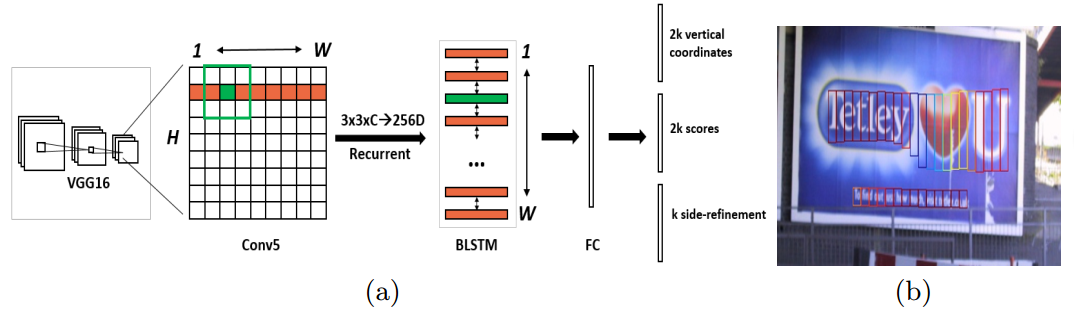
图一:(a)连接文本提议网络(CTPN)的架构。首先通过VGG16的最后一个卷积映射(conv5)密集的滑动3*3空间窗口。每行的序列窗口通过双向LSTM(BLSTM)循环连接,其中每个窗口的卷积特征(3*3*C)被用作256维的BLSTM(包括两个128维的LSTM)的输入。RNN层连接到512维的全连接层,接着是输出层,联合预测k个锚点的文本、非文本分数,y轴坐标坐标(包括坐标和高度)和边缘调整偏移。(b)CTPN输出连续的固定宽度细粒度文本提议。每个框的颜色表示文本/非文本的分数。只显示文本框正例的分数。
(1)贡献一:开发了一个垂直锚点机制,联合预测每个固定宽度提议的位置和文本、非文本的分数。
(2)贡献二:序列提议通过循环神经网络自然连接起来,该网络无缝的结合到卷积网络中,从而形成可训练的端到端模型。
在ICDAR2013,2015数据集上都取得了很好的成绩。
4.相关工作
(1)文本检测:过去都是使用自下而上的方法为主,粗略分为连接组件(CC)和基于滑动窗口的方法。特征手动设计,鲁棒性差,设计特征本身往往也十分困难,另外滑动窗口的方法在计算上也十分昂贵。
(2)目标检测:从选择性搜索的RCNN发展到了RPN网络提供候选框的Faster-RCNN,RPN提议不具有判别性,需要通过额外得成本高昂的CNN模型进一步细化和分类。更重要的是,文本和一般目标检测很大的不同,因此很难直接将通用的目标检测系统应用到这个高度领域化的任务中。
5.连接文本提议网络
本节详细介绍网络的细节,它包括三个关键的贡献,使文本定位可靠和准确:检测细粒度提议文本,循环连接文本提议和边缘细化。
(1)在细粒度提议中检测文本
输入的图像任意大小,VGG网络架构决定了总步长和感受野固定为16个和228个像素。而本文锚点的宽度恰好固定为16,刚好各个框互相挨着且不重叠。
文中k个锚点框,k设置成10,其高度从11个像素到273个像素(每次÷0.7),位置通过高度和y中心坐标度量。如下所示:

其中V={Vc,Vh},V*={V*c,V*h}分别是相对的预测坐标和相对的实际坐标,Cya,ha分别是锚点框的y轴中心高度,Cy,h是输入图片中预测的y轴坐标和高度,C*y,h*是输入图片的实际坐标和高度。
检测到的文本提议是从>0.7(具有非极大值抑制)的文本/非文本分数的锚点生成的。
(2)循环连接文本提议
RNN类型:BLSTM(双向LSTM),每个LSTM有128个隐含层。
RNN输入:每个滑动窗口的3*3*C的特征(可以拉成一列),同一行的窗口的特征形成一个序列。
RNN输出:每个窗口对应256维特征。
整个感受野理论上可以覆盖228*width.
(3)边缘细化
文本行的构建规则。后面详细补充。
与y中心坐标预测类似,下面是x坐标的相对偏移:
文中每个锚点都预测了x坐标的偏移(这个步骤不是后处理计算的),如图一所示,但最终只使用了文本行边缘的提议。即左右两边。
(4)模型输出和损失函数
提出的CTPN有三个输出共同连接到最后的FC层,如图一所示,这个三个输出同时预测文本/非文本分数,垂直坐标(v={Vc,Vh})和边缘细化偏移(o).,探索k个锚点来预测他们在conv5中的每个空间位置,从而在输出层分别得到2k,2k和k个参数。

其中每一个锚点都是一个训练样本,其中每个锚点都是一个训练样本,ii是一个小批量数据中一个锚点的索引。
未完。