这里通过 VMware ,我们安装了三台虚拟机,用来搭建 kafka集群,虚拟机网络地址如下:
hostname ipaddress subnet mask geteway
1、 master 192.168.146.200 255.255.255.0 192.168.146.2
2、 slave1 192.168.146.201 255.255.255.0 192.168.146.2
3、 slave2 192.168.146.202 255.255.255.0 192.168.146.2
1、下载 kafka 压缩包
官网下载地址:http://kafka.apache.org/downloads
2、搭建zookeeper集群
由于 kafka 集群的运行需要 zookeeper,所以我们要首先进行 zookeeper 集群的搭建。
关于搭建的教程,我在上一篇博客已经介绍了:https://www.cnblogs.com/ysocean/p/9860529.html
3、解压 kafka
将下载的 kafka 压缩文件上传到集群中的每台机器相应目录,执行如下命令进行解压。
tar -zxf kafka_2.12-2.0.0.tgz
4、修改配置文件 server.properties
1 broker.id=0 2 listeners=PLAINTEXT://192.168.146.200:9092 3 zookeeper.connect=192.168.146.200:2181,192.168.146.201:2181,192.168.146.202:2181
第一个 broker.id 后面的值和搭建 zookeeper 集群中 myid 一样,是一个集群中唯一的数,要求是正数。需要保证kafka集群中设置的都不一样。
第二个设置监听器,后面的 IP 地址对应当前的 ip 地址。
第三个是配置 zookeeper 集群的 IP 地址。
该配置文件的其余设置可以默认,具体会在后面博客进行介绍。
5、启动 kafka
/usr/local/software/kafka_2.12-2.0.0/bin/kafka-server-start.sh /usr/local/software/kafka_2.12-2.0.0/config/server.properties &
该命令虽然是后台启动服务,但是日志仍然会打印到控制台。
想要完全后台启动,执行如下命令:
/usr/local/software/kafka_2.12-2.0.0/bin/kafka-server-start.sh /usr/local/software/kafka_2.12-2.0.0/config/server.properties 1>/dev/null 2>&1 &
其中1>/dev/null 2>&1 是将命令产生的输入和错误都输入到空设备,也就是不输出的意思。/dev/null代表空设备。
执行完毕后,输入 jps ,出现 kafka 的进程,则证明启动成功。
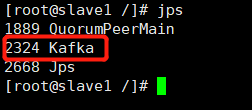
6、创建 topic
集群启动成功后,我们通过创建一个名字为 test,partitions为3,replication为3的topic。
进入到bin 目录下,执行如下命令:
./kafka-topics.sh --create --zookeeper 192.168.146.200:2181,192.168.146.201:2181,192.168.146.202:2181 --partitions 3 --replication-factor 3 --topic test
7、向 topic 发送消息
进入到 bin 目录下,执行如下命令:
./kafka-console-producer.sh --broker-list 192.168.146.200:9092,192.168.146.201:9092,192.168.146.202:9092 --topic test

输入 hello kafka ,然后 enter 键,即向名为 test 的topic 发送了一条消息:hello kafka
8、kafka 可视化工具
为了更好的看到上一步创建的 topic,以及发送的消息。这里介绍一个 kafka 可视化工具——Kafka Tools,官网下载地址:http://www.kafkatool.com/download.html
安装过程很简单,都是点击下一步即可。然后打开该工具,进行如下配置:
点击 File ---> Add cluster
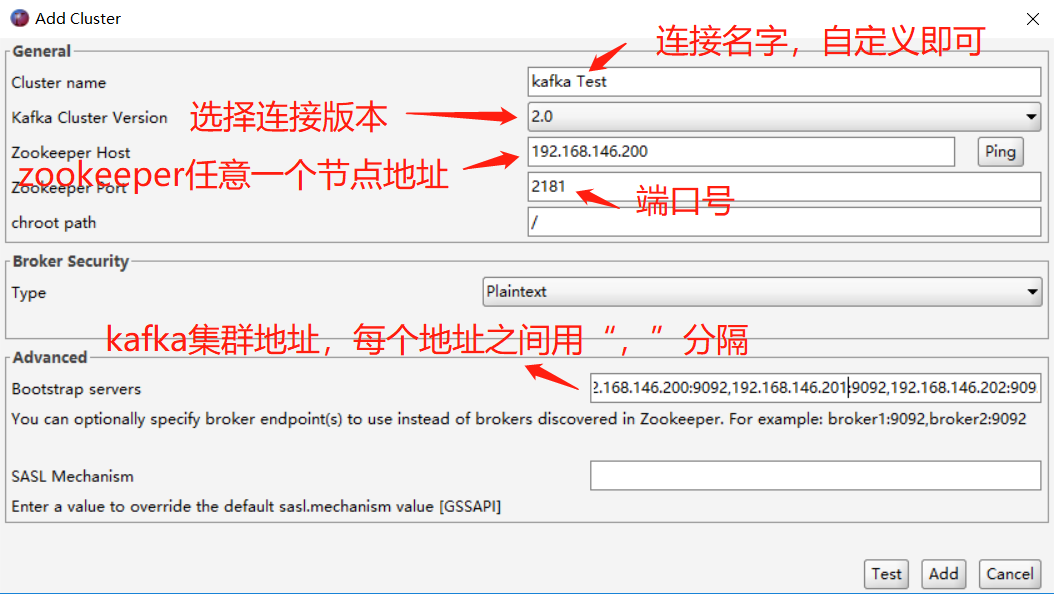
然后点击有下家的 Add 按钮即可。
点开刚刚创建的连接,出现如下界面:
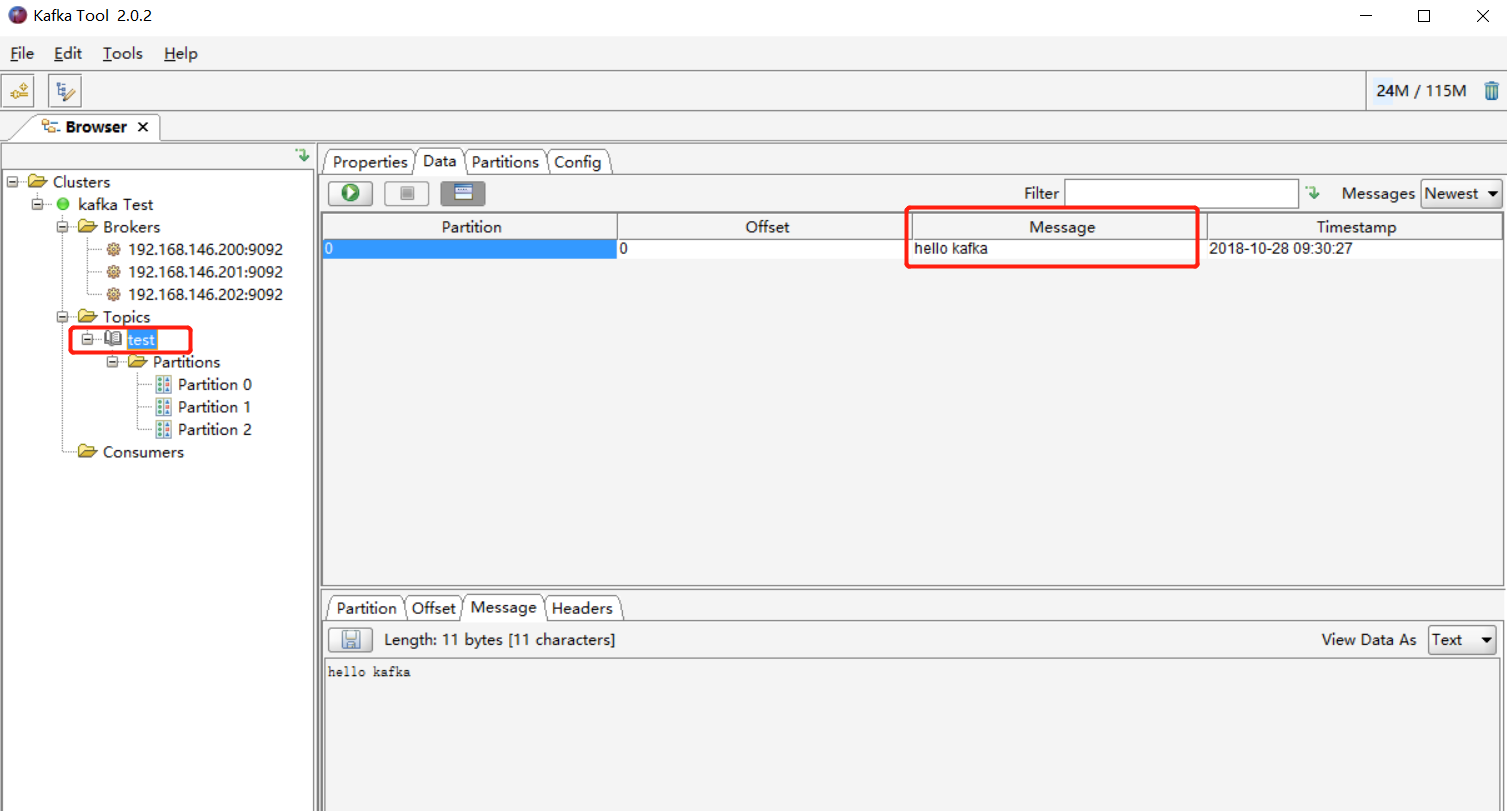
test 便是我们上一步创建的 topic 名称,里面有一条消息 hello kafka。