前言:
由于参加了一个小比赛,所以参考了一下GitHub上的代码,借用了CSDN上
mind_programmonkey大佬的数据集,写出了一个口罩识别程序,代码实现途中,发现了许多问题,所以写下这篇博客,希望对其他人有所帮助。。
由于我只是一名学生,掌握知识有限,所以也是从零开始,对一些小白应该会有所帮助,也欢迎大佬指点。
联系方式:wx:yuanxi154
需要数据集、权重、和我训练好的模型可以加我
一、环境要求
- Python: 3.7.4
- Tensorflow-GPU 1.14.0
- Keras: 2.2.4
- 备注:我环境是用anaconda配置的,具体方法百度,不过可能因为墙的原因,配置会报很多错误
二、数据集
VOC格式数据集(需要数据集联系我)
xml标签和图片相对应
注意:这种名称的图片和xml标签会报错(本来我是随便找个数据集的,结果发现会报错,具体什么原因我也不知道)
正确格式:
三、准备权重
首先,我们需要下载yolov3事先已经训练好的权重,yolov3.weights
下载方法百度
四、代码实现
(1)前期准备:
原版的话就是GitHub上qqwwee的代码:https://github.com/qqwweee/keras-yolo3
我修改后的代码我也上传至GitHub上:https://github.com/god-yx/facemask
由于GitHub不能存在空文件夹,所以我们需要先创建两个文件夹logs和VOCdevkit/VOC2007的三个子文件夹
logs用于存放训练好的模型
VOCdevkit用于存放数据集
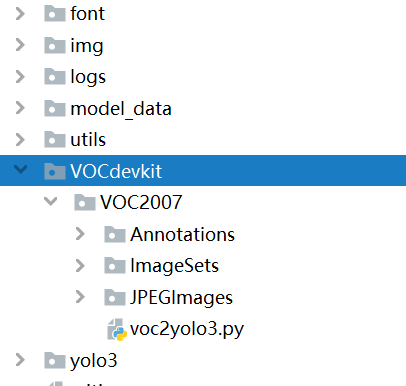
VOC2007底下需要创建三个子文件夹Annotations、ImageSets、JPEGImages
ImageSets需要再创建Main子文件夹
Annotations:用于存放xml标签
ImageSets:存放数据集列表文件,由voc2yolo3.py文件生成
JPEGImages:存放图片
完成后效果图:
(2)权重转换
由于我们用的keras框架,所以我们需要把下载的权重给转换一下
转换的位置在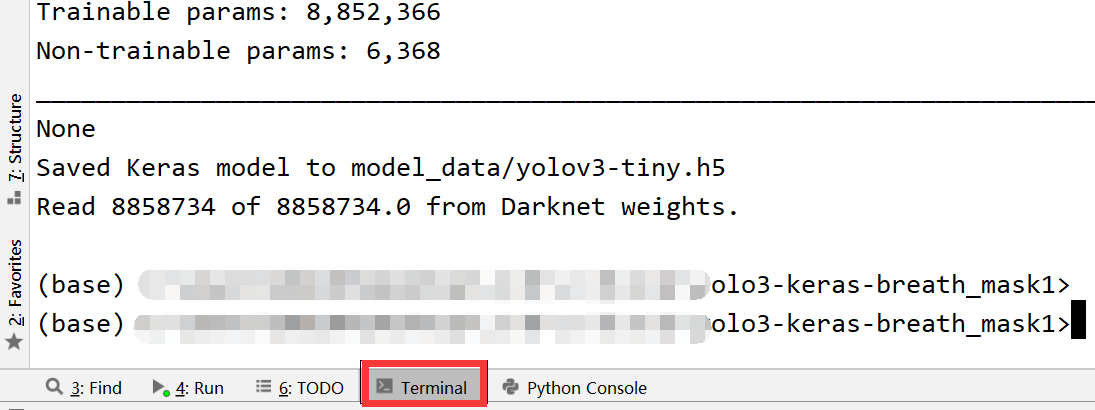
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
python convert.py yolov3-tiny.cfg yolov3-tiny.weights model_data/yolov3-tiny.h5
复制代码直接粘贴回车就好,转换成功就会出现上面图中的信息。
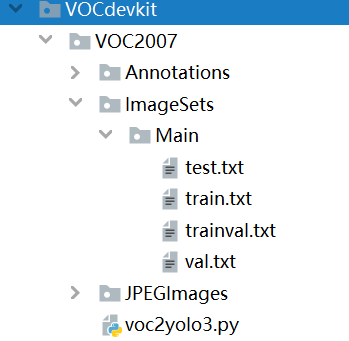
(3)利用voc2yolo3.py文件生成对应的txt。
运行voc2yolo3.py之后会在ImageSets/Main生成如下txt文件(位置不要错)
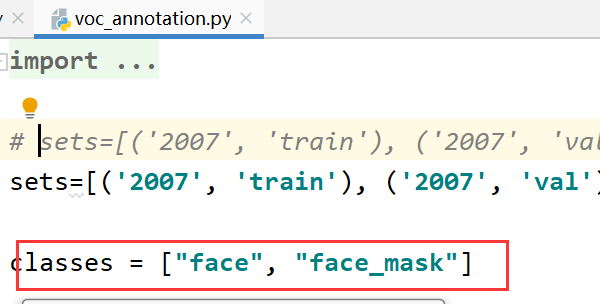
(4)运行根目录voc_annotation.py
运行前需要将voc_annotation文件中classes改成你自己的classes(xml文件对应的标签)
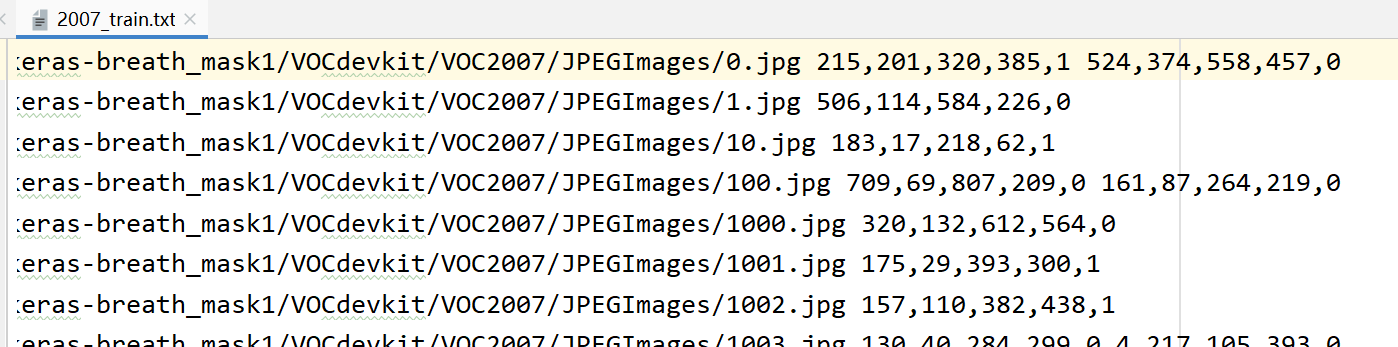
我们就会生成这样的一个文件,2007_train.txt,这里面 每一行对应其图片位置及其真实框的位置
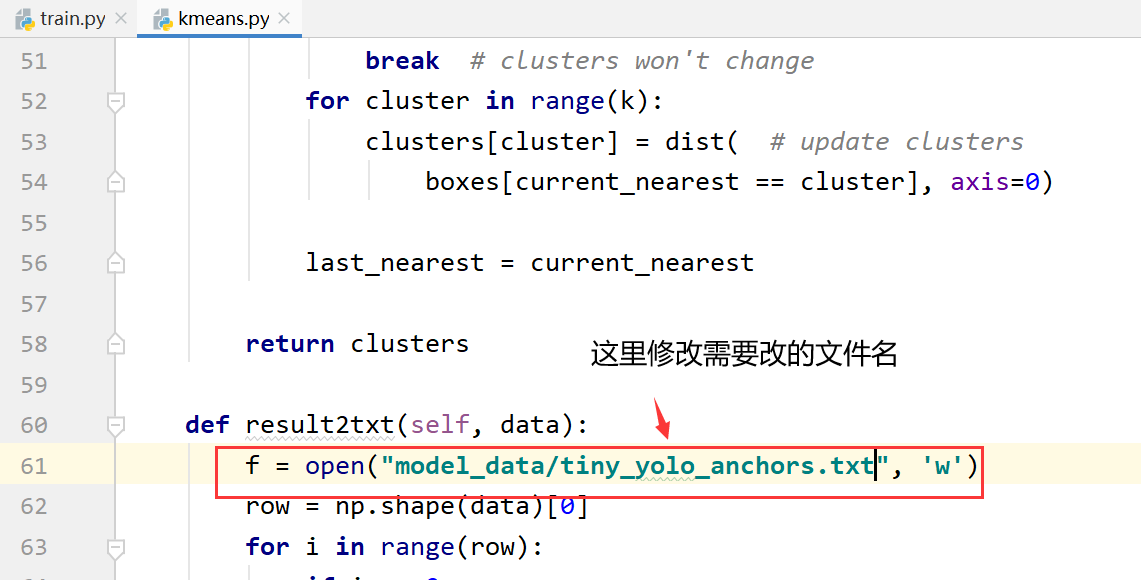
(5)修改model_data里面的yolo_anchors.txt和tiny_yolo_anchors.txt
这里非常重要,因为如果不修改的话,就会出现很多问题。
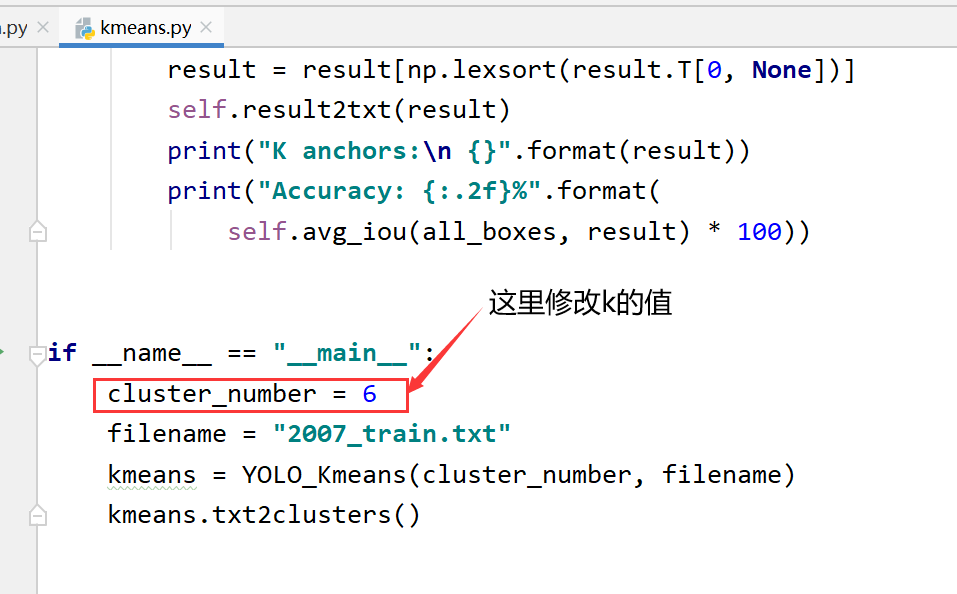
这里我们利用kmeans.py来生成。
k=9,生成yolo_anchors;k=6,生成tiny_yolo_anchors.txt
(6)修改标签
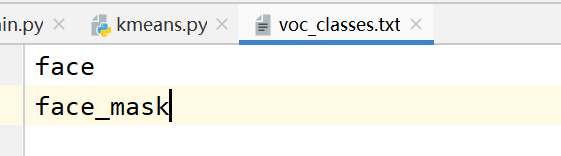
接着我们来到model_data里面的voc_classes.txt文件中需要将classes改成你自己的classes。不要有第三行
(7)训练
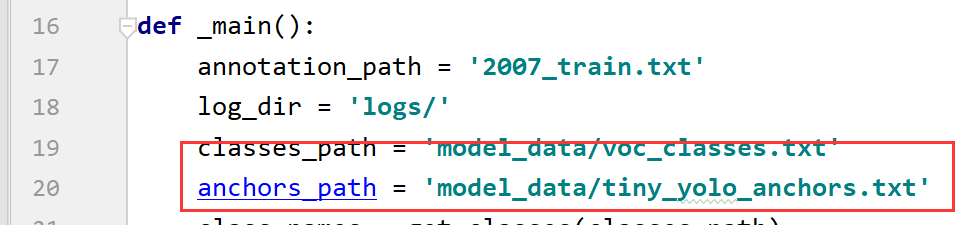
然后来到train.py中,通过修改anchor_path,从而选择使用yolov3训练还是yolov3-tiny训练
如果是用我的代码,可以不用改,否则:
运行train.py 即可开始训练,训练好的模型会存放在logs下。

训练过程
五,测试
修改根目录下yolo.py文件,修改model_path,anchors_path,classes_path替换成·自己的路径

运行predict_img.py,在输入框输入图片路径进行测试。
运行yolo_video.py,打开摄像头进行测试。
测试本地视频:
运行yolo_video.py
此外对应的yolo.py文件174行改为vid = cv2.VideoCapture(“视频路径+视频名+视频后缀名”);
六、注意:
一张图片最多只能识别20个对象的问题:
-
1.训练时,要在yolo3文件夹下面的utils.py里,修改get_random_data()函数,有一个默认参数是max_boxes=20,改成很大的数值就行了。
-
2.检测时,要在yolo3文件夹下面的model.py里,修改yolo_eval()函数,有一个默认参数是max_boxes=20,改成很大的数值就行了。
七:常见问题
这里汇总我测试代码时出现的几个问题:
(1)File "h5py\_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py\_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5pyh5f.pyx", line 88, in h5py.h5f.open
OSError: Unable to open file (unable to open file: name = './raw', errno = 13, error message = 'Permission denied', flags = 0, o_flags = 0)
这里我的问题是由于版本问题,新的版本对语法有所改变
(2)提示Mismatch between model and given anchor and class sizes
这里是由于第五步的时候修改的有问题;
(3)测试的时候没有窗口,或者识别很多窗口
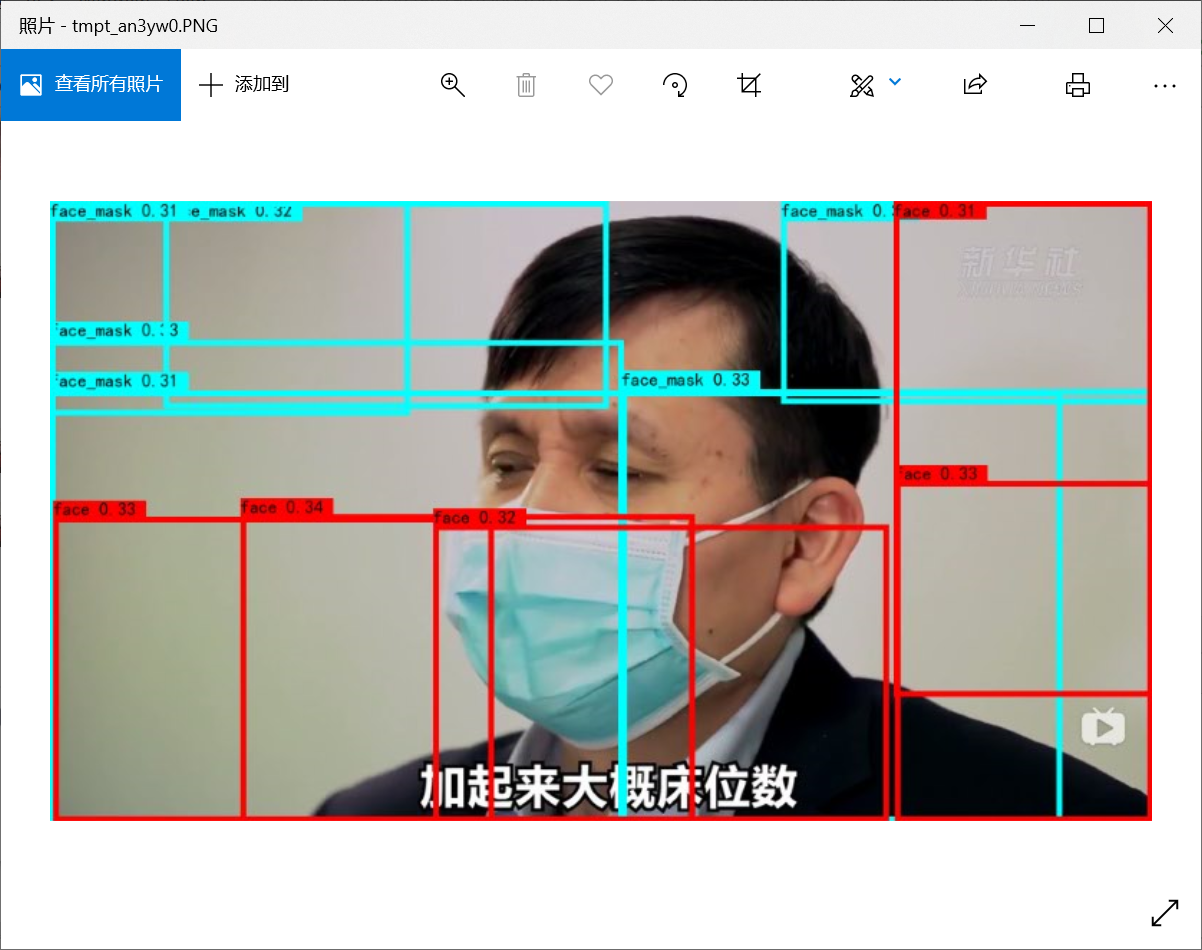
还是第五步的时候出问题了
还有一些问题记不清楚了,如果有问题欢迎留言讨论