1.通用搜索引擎面临着索引规模、更新速度、个性化需求等多方面挑战
2.如果网页 p 中包含超链接 l, 则 p 称为链接 l 的父网页;如果超链接 l 指向网页 t, 则网页 t 称为子网页,又称为目标网页。
3.主题网络爬虫的基本思路就是按照事先给出的主题, 分析超链接和已经下载的网页内容, 预测下一个待抓取的 URL 以及当前网页的主题相关度, 保证尽可能多地爬行、 下载与主题相关的网页, 尽可能少地下载无关网页
4.主题网络爬虫,主题定制爬行策略和相关算法
研究进展分析总结:①基于文字内容的启发式方法(利用网页、url、锚文字等文字信息;爬行主题采用关键字集合来描述;根据url的优先级来爬取,使用主题关键词和抓取网页的文字内容计算优先级)
②基于web超链图的评价方法(pagerangk值排url优先级;如果一个网页被引用的次数越多,越重要,url优先级越高)
③基于分类器的预测方法(基于分类模型预测网页的主题相关度)
综上:未来主题爬虫的研究主要是围绕如何提高链接主题预测的准确性,
5.优秀的搜索引擎需要复杂的架构和算法,以此支撑海量数据的获取、存储、及查询的及时性
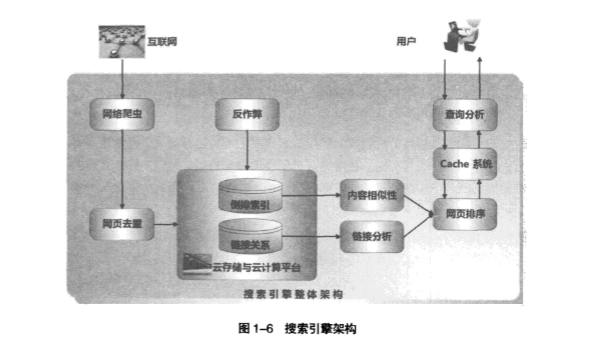
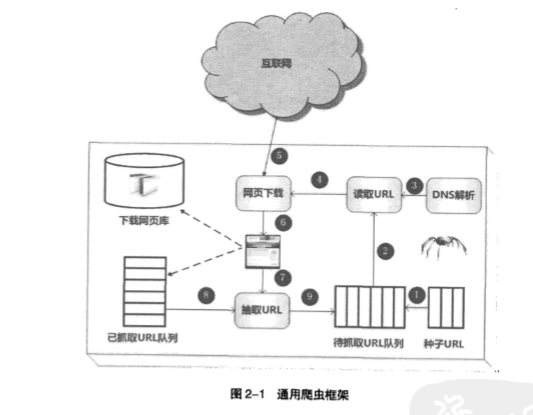
6.优秀爬虫的特性:
①高性能(下载网页的速度;带抓取url队列和一抓取url队列的数据结构优化)
②可扩展性(能够扩充服务器等)
③健壮性(对异常情况的正确处理;)
④友好性