在机器学习中,我们使用 loss/cost 表示当前模型与理想模型的差距。训练的目的,就是不断缩小 loss/cost。
简单直接的classification error 很难精确描述模型与理想模型之间的距离。需要建立别的更有效的loss函数。
pytorch中常用的方法如下:
每个损失函数的构造函数都会有自己的参数
criterion = LossCriterion()
loss = criterion(x, y)
Cross-Entropy-Loss
交叉熵,部分参考:
博客 - 神经网络的分类模型 LOSS 函数为什么要用 CROSS ENTROPY
知乎 - 损失函数 - 交叉熵损失函数
PyTorch(七)——损失函数
如果用 MSE 计算 loss,输出的曲线是波动的,有很多局部的极值点。 即,非凸优化问题 (non-convex)。cross entropy 计算 loss,则依旧是一个凸优化问题,用梯度下降求解时,凸优化问题有很好的收敛特性。
cross-entropy 更清晰的描述了模型与理想模型的距离。交叉熵主要是用来判定实际的输出与期望的输出的接近程度。注意:交叉熵不是对称的。
交叉熵的计算公式为:
其中p表示真实值,在这个公式中是one-hot形式;log底数为2,q是预测值,在这里假设已经是经过softmax后的结果了。
分类问题,都用 one hot + cross entropy
training 过程中,分类问题用 cross entropy,回归问题用 mean squared error。
training 之后,validation/testing 时,使用 classification error,更直观,而且是我们最关注的指标。模型预测学习过程中:
- 神经网络最后一层得到每个类别的得分scores;
- 该得分经过sigmoid(或softmax)函数获得概率输出;
- 模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算。
使用逻辑函数得到概率,并结合交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
sigmoid(softmax) + cross-entropy loss 擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。基于这个问题的优化有很多,比如对softmax进行改进,如L-Softmax、SM-Softmax、AM-Softmax等。(由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。)
使用交叉熵损失函数,不仅可以很好的衡量模型的效果,又可以很容易的的进行求导计算。
另,sigmoid计算公式为:
softmax的计算公式为:
交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
torch.nn.CrossEntropyLoss()
多分类,训练过程中使用。首先,import torch.nn as nn 部分参考:
CrossEntropyLoss带权重的计算公式为(默认weight=None)(不带权重的话,公式中不包含外层括号外的weight[class]):
用于多分类问题,nn.CrossEntropyLoss()是nn.logSoftmax()和nn.NLLLoss()的整合,可以直接使用它来替换网络中的这两个操作。
直接使用pytorch中的loss_func=nn.CrossEntropyLoss()计算得到的结果与softmax-log-NLLLoss计算得到的结果是一致的。
class torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
- weight (Tensor, optional) – a manual rescaling weight given to each class. If given, has to be a Tensor of size C
- size_average (bool, optional) – Deprecated (see reduction). By default, the losses are averaged over each loss element in the batch. Note that for some losses, there are multiple elements per sample. If the field size_average is set to False, the losses are instead summed for each minibatch. Ignored when reduce is False. Default: True
- ignore_index (int, optional) – Specifies a target value that is ignored and does not contribute to the input gradient. When size_average is True, the loss is averaged over non-ignored targets.
- reduce (bool, optional) – Deprecated (see reduction). By default, the losses are averaged or summed over observations for each minibatch depending on size_average. When reduce is False, returns a loss per batch element instead and ignores size_average. Default: True
- reduction (string, optional) – Specifies the reduction to apply to the output: 'none' | 'mean' | 'sum'. 'none': no reduction will be applied, 'mean': the sum of the output will be divided by the number of elements in the output, 'sum': the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction. Default: 'mean'
Large-Margin-Cosine-Loss
所有基于softmax loss改进的损失都有相同的想法:最大化类间方差和最小化类内方差。
参考
简称LMCL,原用在人脸识别任务中,出自Tencent AI Lab在CVPR 2018的论文:CosFace: Large Margin Cosine Loss for Deep Face Recognition
这个损失函数制定通过采用了特征L2归一化以及权重向量的L2归一化,去除了特征的径向差异带来的影响(这个创新点其实就来自之前的Normface)。引入一个余弦Margin可以在角度空间中增大决策Margin,因此可以实现最小化类内差异,最大化类间差异。
该算法以归一化的特征为输入,以最大化类间余弦Margin来学习判别性特征。
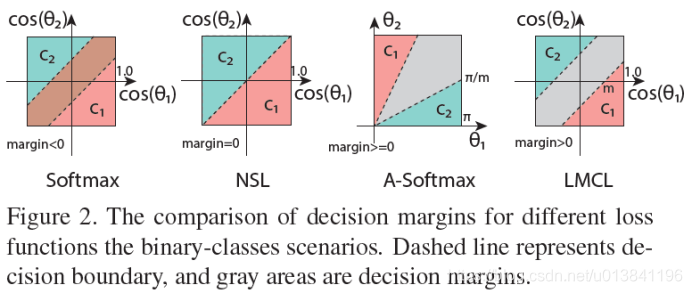
定义一个超参数m>0(两个类别之间有一个明确的边界空间(margin>0),有更好的鲁棒性),定义了一个余弦空间的Margin,决策边界为:
计算公式:
subject to:
其中N为训练样本的数目,x_i表示归一化的第i个特征,W_i表示第i类别的权重向量。s为尺度超参数,一般取值较大;m为margin超参数,取小值。
tips
在PyTorch中使用交叉熵损失函数的时候会自动把label转化成onehot,所以不用手动转化,而使用MSE需要手动转化成onehot编码。
几种loss的对比: