一.正则表达式
1.正则表达式 (Regular Expression) 又称 RegEx, 是用来匹配字符的一种工具. 在一大串字符中寻找你需要的内容.
2.正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配
3.re 模块使 Python 语言拥有全部的正则表达式功能
4.它常被用在很多方面, 比如网页爬虫, 文稿整理, 数据筛选等等.
二.简单的匹配


1 import re 2 # regular expression 3 pattern1 = "dog" 4 pattern2 = "cat" 5 pattern3 = "bird" 6 string = "dog runs to cat" 7 8 #如果匹配成功,返回一个匹配的对象,没找到则返回none 9 #re.span方法显示匹配的位置 10 #group(num) 或 groups() 来获取匹配表达式 11 12 #re.match:匹配string初始位置 13 #re.match(pattern, string, flags=0) 14 #pattern:匹配的正则表达式;string要匹配的字符串;flags标志位,用于控制正则表达式的匹配方式 15 print(re.match(pattern1, string)) 16 print(re.match(pattern1, string).span())#span函数显示匹配的位置 17 print(re.match(pattern1, string).group())#groop方法获取正则表达式 18 print(re.match(pattern2, string)) 19 print(re.match(pattern3, string)) 20 print('*'*50) 21 22 # re.search(pattern,string, flags=0)匹配整个string:在string中查找pattern 23 print(re.search(pattern1, string)) # <_sre.SRE_Match object; span=(12, 15), match='cat'> 24 print(re.search(pattern2, string)) # 25 print(re.search(pattern2, string).span()) 26 print(re.search(pattern2, string).group()) 27 print('*'*50) 28 29 #findall(pattern, string, flags=0)在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表 30 # 注意: match 和 search 是匹配一次,匹配到结束,findall 匹配所有,匹配完结束 31 print(re.findall(r"ran", "run ran ran ran")) 32 print(re.search(r"ran", "run ran ran ran")) 33 print(re.findall(r"(run|ran)", "run ran ran ran")) # | : or 34 print(re.search(r"(run|ran)", "run ran ran ran")) 35 print('*'*50) 36 37 #finditer(pattern, string, flags=0) 和findall类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回 38 r=re.finditer(r"(run|ran)", "run ran ren ran") 39 print(r) 40 for i in r: 41 print(i.group()) 42 ------------------------------------------------- 43 <_sre.SRE_Match object; span=(0, 3), match='dog'> 44 (0, 3) 45 dog 46 None 47 None 48 ************************************************** 49 <_sre.SRE_Match object; span=(0, 3), match='dog'> 50 <_sre.SRE_Match object; span=(12, 15), match='cat'> 51 (12, 15) 52 cat 53 ************************************************** 54 ['ran', 'ran', 'ran'] 55 <_sre.SRE_Match object; span=(4, 7), match='ran'> 56 ['run', 'ran', 'ran', 'ran'] 57 <_sre.SRE_Match object; span=(0, 3), match='run'> 58 ************************************************** 59 <callable_iterator object at 0x058E8470> 60 run 61 ran 62 ran
三.灵活匹配
import re # multiple patterns 灵活匹配:匹配潜在的多个可能性文字,可用【】将可能的字符囊括起来 ptn = r"r[au]n" # ("run" or "ran") #建立一个正则的规则:我们在 pattern 的 “” 前面需要加上一个 r 用来表示这是正则表达式, 而不是普通字符串. print(re.search(ptn, "dog runs to cat"))# <_sre.SRE_Match object; span=(4, 7), match='run'> #括号 [] 中还可以是以下这些或者是这些的组合. 比如 [A-Z] 表示的就是所有大写的英文字母. [0-9a-z] 表示可以是数字也可以是任何小写字母 print(re.search(r"r[A-Z]n", "dog runs to cat")) print(re.search(r"r[a-z]n", "dog runs to cat")) print(re.search(r"r[0-9]n", "dog r2ns to cat")) print(re.search(r"r[0-9a-z]n", "dog runs to cat")) ----------------------------- <_sre.SRE_Match object; span=(4, 7), match='run'> None <_sre.SRE_Match object; span=(4, 7), match='run'> <_sre.SRE_Match object; span=(4, 7), match='r2n'> <_sre.SRE_Match object; span=(4, 7), match='run'>
四.sub替换
1 import re 2 3 #re.sub(pattern, repl, string, count=0)通过正则表达式匹配上一些形式的字符串然后再替代掉这些字符串. 4 #repl : 替换的字符串,也可为一个函数。count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。 5 print(re.sub(r"r[au]ns", "catches", "dog runs to cat")) 6 7 # repl可以是一个函数。将匹配的数字乘于 2 8 def double(matched): 9 value = int(matched.group('value')) 10 return str(value * 2) 11 s = 'A23G4HFD567' 12 print(re.sub('(?P<value>d+)', double, s)) 13 -------------------------------------------- 14 dog catches to cat 15 A46G8HFD1134
五.compile编译正则表达式
1 import re 2 #compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供match()和search()这两个函数使用 3 #使用 compile 过后的正则, 来对这个正则重复使用 4 #先将正则表达式 compile为一个变量, 比如 compiled_re, 然后直接使用这个 变量compiled_re 来重复使用 5 compiled_re = re.compile(r"r[ua]n") 6 print(compiled_re.search("dog ran to cat")) 7 print(compiled_re.findall("run ran ran")) 8 ------------------------------------------------------ 9 <_sre.SRE_Match object; span=(4, 7), match='ran'> 10 ['run', 'ran', 'ran']
六.split分割
1 import re 2 #split 方法按照能够匹配的子串将字符串分割后返回列表 3 #split(pattern, string, maxsplit=0, flags=0) 4 #maxsplit分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。 5 #flags标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 6 print(re.split(r"[,;.]", "a;b,c.d;e")) 7 print(re.split('W+', ' runoob, runoob, runoob.', 1)) 8 ------------------------------------------------------ 9 ['a', 'b', 'c', 'd', 'e'] 10 ['', 'runoob, runoob, runoob.']
七.正则表达式修饰符(flags):正则表达式可以包含一些可选标志修饰符来控制匹配的模式。
多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志

1 import re 2 print(re.search(r"r[A-Z]n", "dog runs to cat")) 3 print(re.search(r"r[A-Z]n", "dog runs to cat",flags=re.I)) 4 ------------------------------------------------------------------------ 5 None 6 <_sre.SRE_Match object; span=(4, 7), match='run'>
八.正则表达式模式:
模式字符串使用特殊的语法来表示一个正则表达式:
1.字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
2.多数字母和数字前加一个反斜杠时会拥有不同的含义。
3.标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
4.反斜杠本身需要使用反斜杠转义。
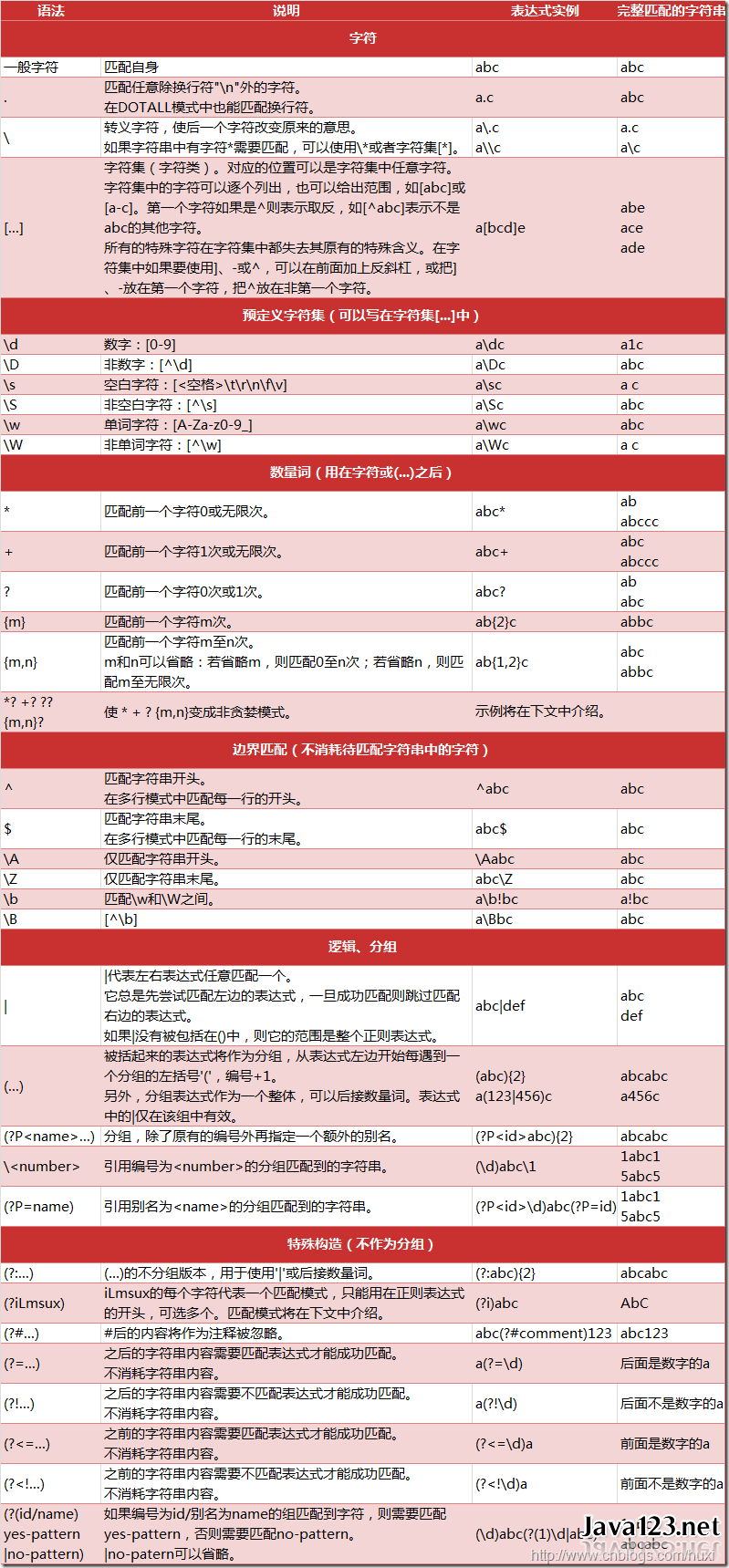
实例:

