定义
1、设计数据库的时候所依据的规范,共有三个规范。
2、按照三范式设计表避免出现数据冗余。
3、在实际的开发中,以满足客户的需求为主,有的时候会拿冗余换执行速度。
第一范式
- 主键、字段不能再分
要求有主键,数据库中不能出现重复记录,每一个字段是原子性不能再分。 - 示例:不符合第一范式

原因:
1、数据存在重复记录,数据不唯一,没有主键。
2、联系方式可以再分,不是原子性。 - 修改后:

- 结论:关于第一范式
1、每一行必须唯一,也就是每个表必须有主键,这是我们数据库设计的最基本要求;
2、主键主要通常采用数值型或定长字符串表示;
3、关于列不可再分,应根据具体的情况来决定。如联系方式,为了开发上的便利可能就采用一个字段了。
第二范式
- 非主键字段完全依赖主键
第二范式是建立在第一范式基础之上,要求数据库中所有非主键字段完全依赖主键,不能产生部分依赖。(严格意义上说:尽量不要使用联合主键) - 示例(不符合第二范式)
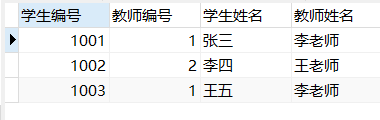
原因:
1、以上虽然确定了主键(学生编号、教师编号),但此表会出现大量冗余,主要涉及到的冗余字段为“学生姓名”和“教师姓名”;
2、出现冗余的原因在于:学生姓名部分依赖了主键的一个字段学生编号,而没有依赖教师编号;而教师姓名部分依赖了主键的一个字段教师编号,这就是第二范式部分依赖。 - 修改后
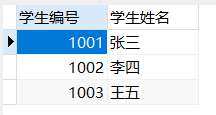
学生表:
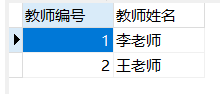
教师表:
关系表:
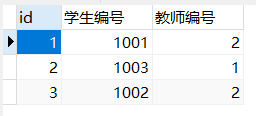
- 结论
1、一种典型的“多对多”的设计。
2、多对多,三张表,关系表两个外键。
第三范式
- 定义
建立在第二范式基础之上,要求非主键字段不能产生传递依赖于主键字段。 - 示例(不符合第三范式)
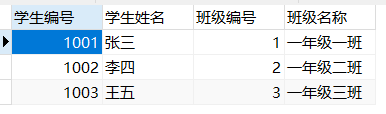
原因:
1、从表中看出,班级名称字段存在冗余,因为班级名称字段没有直接依赖于主键(学生编号);
2、班级名称字段依赖于班级编号,班级编号依赖于学生编号,那么这就是传递依赖。 - 修改后
(将冗余字段单独拿出来建立表)
学生表:
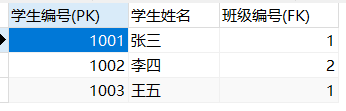
班级表:
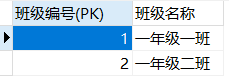
- 结论
1、以上设计是一种典型的一对多的设计,一(班级表)存储在一张表中,多(学生表)存储在一张表中,在多的那张表中添加外键指向一的一方的主键
2、一对多,两张表,多的表加外键。
一对一
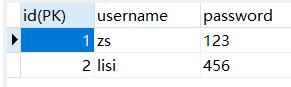
- 方法一:分两张表存储,共享主键
t_user_login:

t_user_detail:
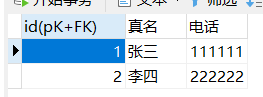
t_user_detail中的id即是主键也是外键。 - 方法二:分两张表存储,外键唯一
t_user_login:
t_user_detail:
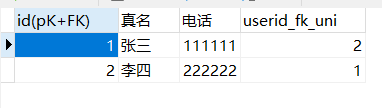
给userid_fk_uni添加外键和unique约束。