首先接到的是一个网址,地址是http://www.zxinc.org/gb2260.htm。但这个网址后来就没用了,服务器那边应该出问题了,不过还好我保存到本地了。
再放一个云盘
链接:https://pan.baidu.com/s/1Hkf2PtRGK3dLQ50tJ1mk4g
提取码:unon
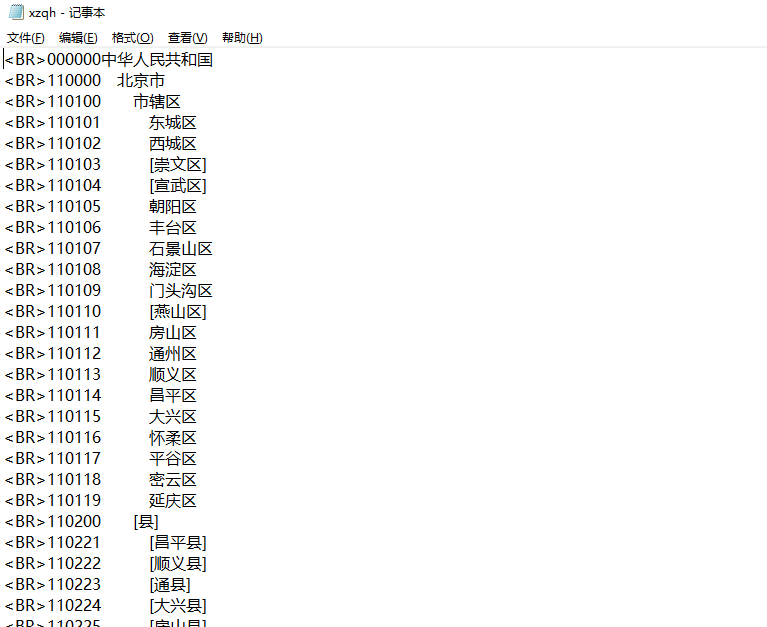
这里我是将那个页面打开查看源码然后复制下来的,所以前面带了一个<BR>,这里的每行是由区划代码、区划名称构成。这里一共有6976行
我的需求是将这份文本做成excel,并分成三列,1列放区划代码,2列放名称,3列需要自家根据区划代码来标记区划层级,如省级则标记1,市级标记2,县级标记3.
这里我没有用一套流程走到底,excel表格也是我直接手动创建并粘贴数据上去的。我只需要在文本中过滤出我想要的数据并打印到控制台,只要行数是正确的,一列列粘贴到excel表格上是可以的。其实也可以写一个方法来写入至excel,但那样效率低,没必要。
好了直接贴代码,这里我直接是写在main方法里了,我直接将main方法复制下来。有一部分代码暂时不会用到,我将其注释掉了,等需要用时我会打开注释
public static void main(String[] args) { File file = new File("D:\xzqh.txt"); //源文本 // File file = new File("D:\code.txt"); //代码+标记文本 BufferedReader br = null; StringBuffer sb = null; try { //在字节流的基础上套用InputStreamReader转换为字符流 br = new BufferedReader(new InputStreamReader(new FileInputStream(file.getPath()), "GBK")); sb = new StringBuffer(); String line = null; while ((line = br.readLine()) != null) { sb.append(line); } } catch (Exception e) { e.printStackTrace(); } finally { try { br.close(); } catch (Exception e) { e.printStackTrace(); } } //打印文件的所有内容 System.err.println(new String(sb)); // //设置过滤条件 // String regex = "\d{6}"; //匹配数字 // String regex = "[a-zA-Z]"; //匹配英文字母 // String regex = "[u4e00-u9fa5]{1,}"; //匹配中文 // Pattern p = Pattern.compile(regex); // Matcher m = p.matcher(new String(sb)); // while (m.find()) { //追加 // String str1 = m.group(); // if(str1.indexOf("省") != -1 || str1.indexOf("市") != -1 || str1.indexOf("区") != -1) { // System.err.println(m.group()); // }else if(str1.indexOf("[县]") != -1) { // System.err.println(m.group()); // break; // }else if(str1.indexOf("县") != -1 || str1.indexOf("旗") != -1 || str1.indexOf("盟") != -1) { // System.err.println(m.group()); // }else if(str1.indexOf("州") != -1 || str1.indexOf("岛") != -1 || str1.indexOf("直辖行政单位") != -1) { // System.err.println(m.group()); // }else if(str1.indexOf("镇") != -1 || str1.indexOf("委员会") != -1) { // System.err.println(m.group()); // }else { // System.out.print(m.group()); // }
// //code处理,这段是后面加上去的
// StringBuffer str = new StringBuffer(m.group());
// if("A".equals(str.toString())) {
// System.err.println(str.append("1"));
// }else if("B".equals(str.toString())) {
// System.err.println(str.append("2"));
// }else if("C".equals(str.toString())) {
// System.err.println(str.append("3"));
// }else {
// System.err.println(str);
// }
//直接输出 // System.out.println(m.group()); //处理追加字符 // StringBuffer str = new StringBuffer(m.group()); // String code0 = str.substring(0, 2); //截取0-2位 // String code1 = str.substring(2, 4); //截取中间两位 // String code2 = str.substring(4, 6); //截取后2位 // if(!"00".equals(code2)) { //县级 // System.out.println(str.append("C")); // }else if(!"00".equals(code1) && "00".equals(code2)) {//市级 // System.out.println(str.append("B")); // }else if(!"00".equals(code0) && "00".equals(code1) && "00".equals(code2)){ //省级 // System.out.println(str.append("A")); // }else { // System.out.println(str); // } // } }
讲一下整体思路吧,我们得到的结果是有三列的Excel表格,所以我们一列一列的走,先拿到他的区划代码
然后接下来是步骤
1.将上面的代码运行,注意文件位置是对的,正确运行的话应该是下面的样子,这是没有换行的,不过这个影响不大。

将 打印所有内容 那行代码注释掉,因为我们不需要打印所有,只需要将区划代码打印出来;并将下面的注释打开,如图
再次运行程序,打印台输出区划代码,同样是6976行(总行数),将其复制粘贴至excel的第一列

2.根据行政区划做标记省级为XX0000,市级为XXX000或XXXX00,县级为XXXXXX或XXXXX0,层级标记的是数字,所以,但是区划也是数字,在这里不好区分开,所以暂时用ABC代替123,便于过滤。
将 直接输出 那行代码注释,如图,其他则不变。这段代码是根据区划代码在后面加上标记
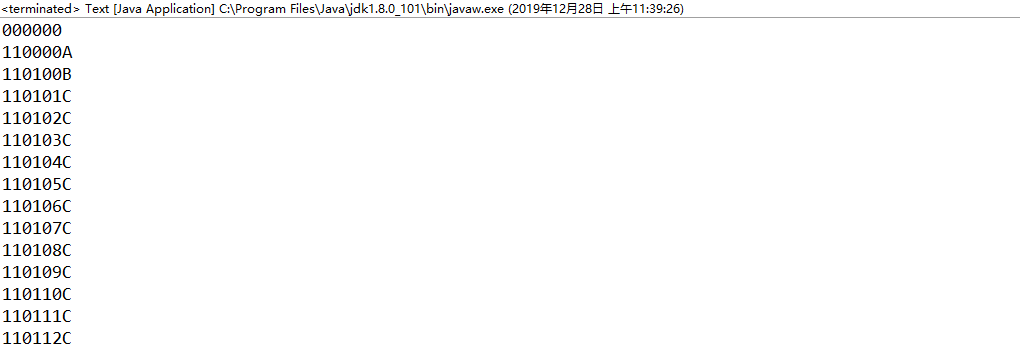
输出如图:这里的000000是中华人民共和国,因为只有一个,所以我这里不做判断
然后将打印台内容全选放入一个新的txt文本,取名code.txt。里面保存的是行政区划+区划标记的文本。(先暂时存放,后面还需要用到)
3.将 处理追加字符下面这段代码注释掉,打开 直接输出 的注释,如图
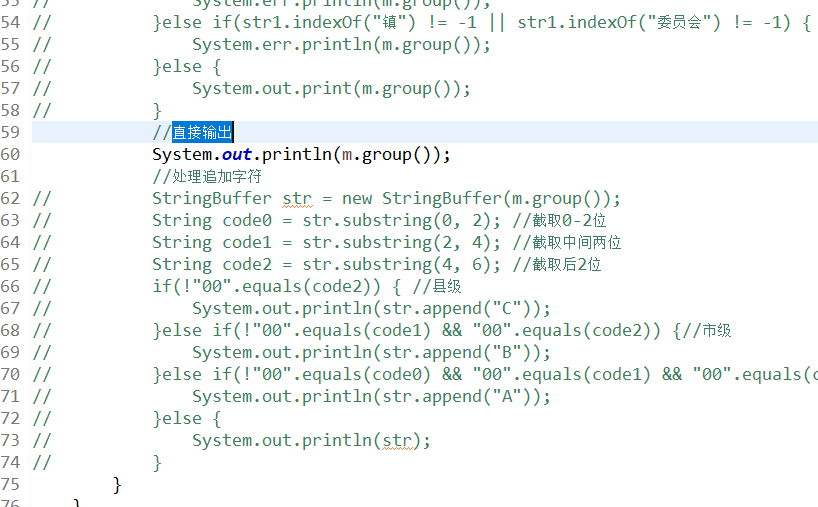
然后将过滤条件更换成匹配中文,然后将 直接输出 这行代码注释掉,将蓝色部分代码的注释打开。这里解释一下为什么已经匹配了中文还需要这么麻烦地对比字符,这是因为有些地名实在是千奇百怪,直接匹配地名,会导致匹配出来行数对不上,也就是数据有问题,所以才这样走一遍的:
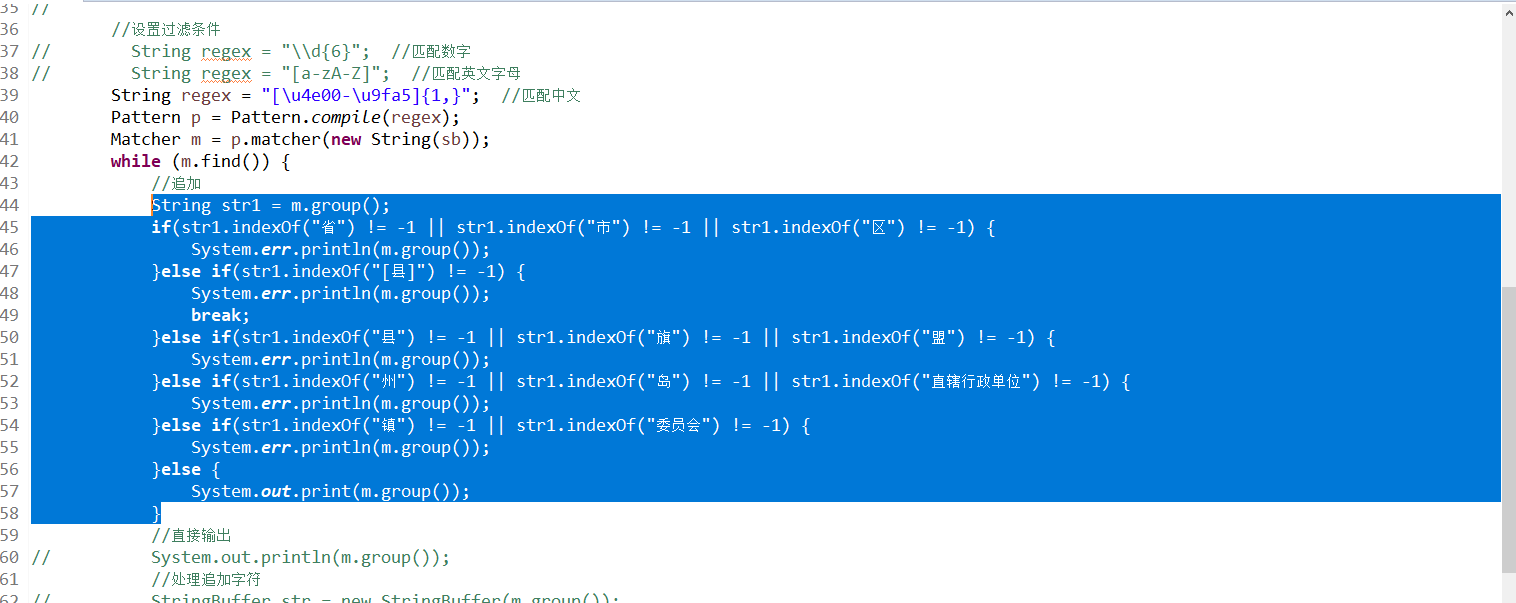
然后直接输出,打印台是这样的,复制到Ecel,这样就拿到第二列的区划名称
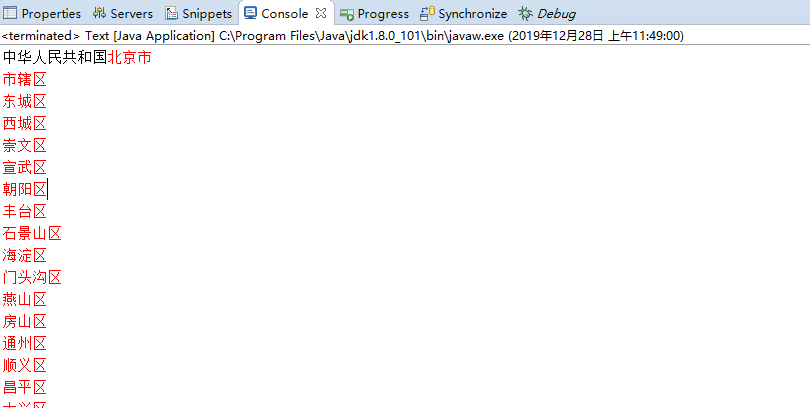
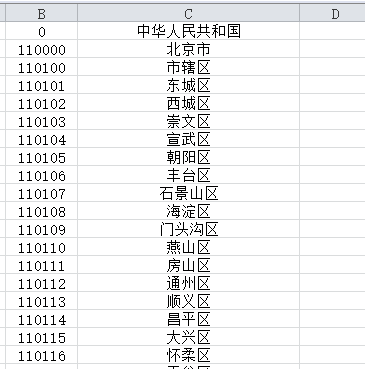
4.读取刚才的code.txt,注意路径。并将以下代码如图注释掉。这里匹配字母然后选择过滤后直接输出!
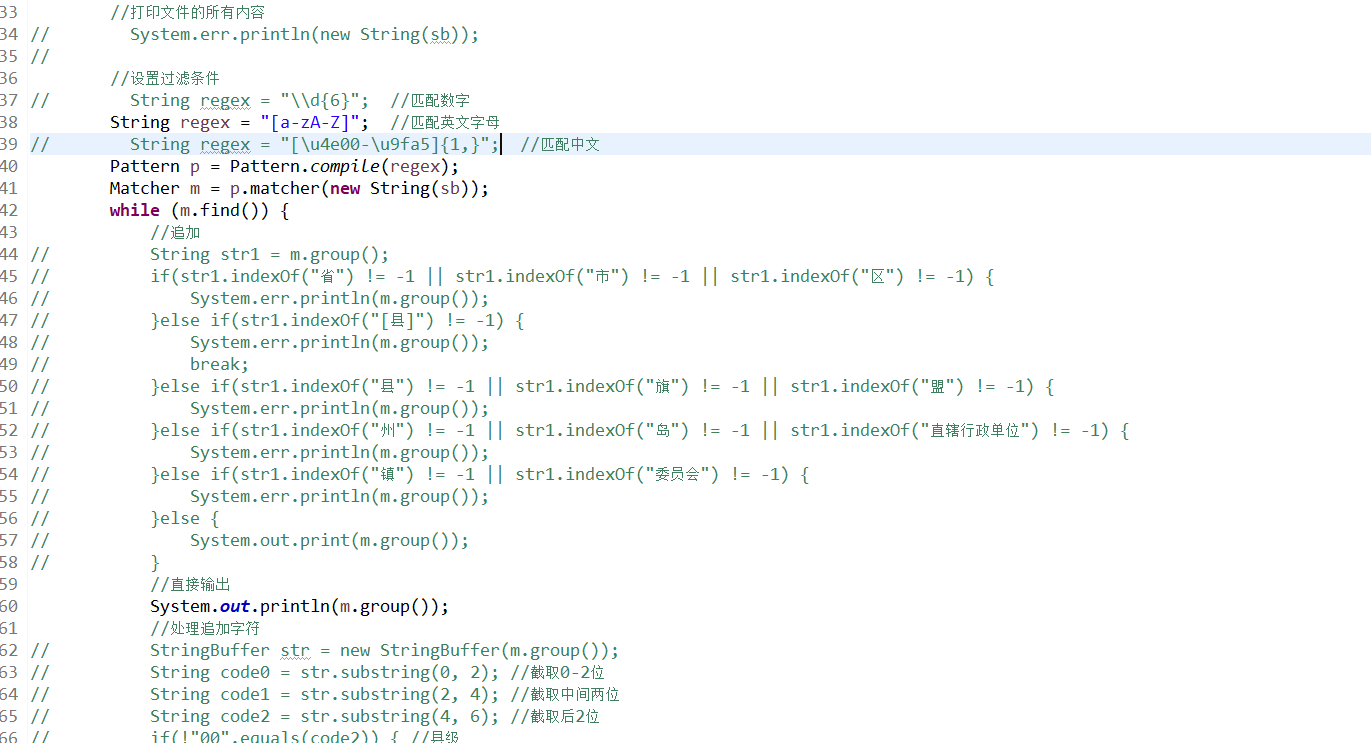
记得将上面的读取的文件替换成code.txt,将code处理这段注释打开,

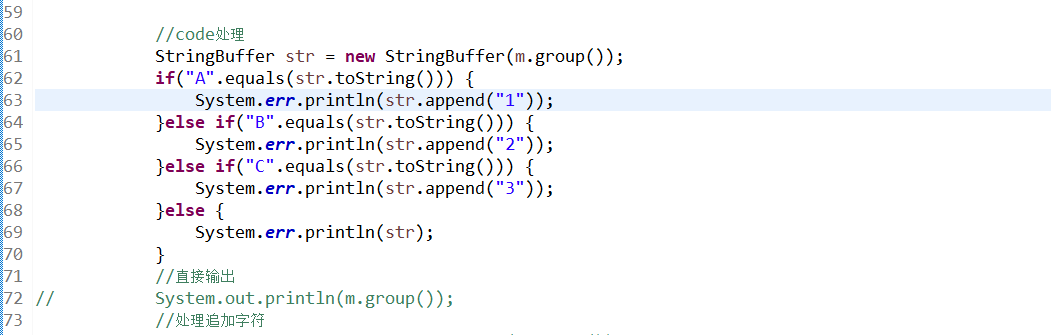
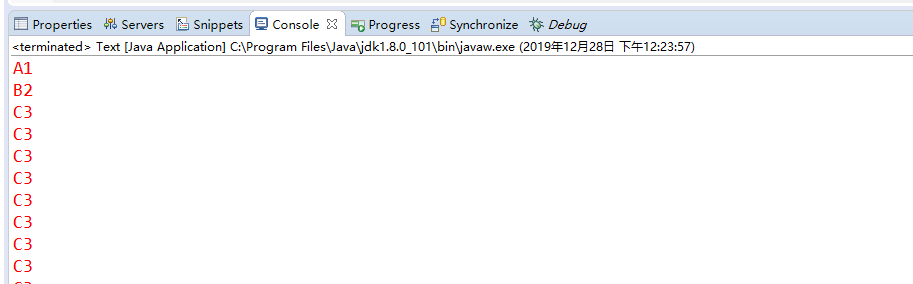
打印出一串字母+数字组合,再将以下打印台输出的额所有内容复制到code.txt,再更换过滤条件,单独将数字取出
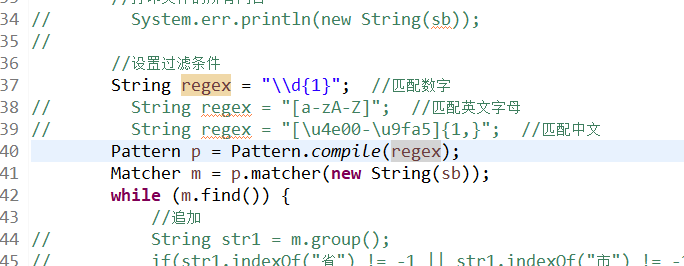
过滤后直接输出即可,不需要处理什么,注意运行前记得把匹配的6为数字改成1位
控制台输出:

将其复制粘贴至Excel中即可。注意1开始是从北京市开始的,而不是从中华人民共和国开始。

逻辑有点乱,下次好好梳理