[Crawling is going on - Alpha版本]
使 用 说 明
|
北京航空航天大学计算机学院 远航1617 小组 |
产品版本: Alpha版本 |
|
产品名称:Crawling is going on |
共 7 页 |
文 档 作 者: ______杨帆______
说 明 书 校 对:_____林谋武______
项 目 审 核: _____刘昊岩______
1.引言
1.1 编写目的
编写本使用说明的目的是充分叙述本软件所能实现的功能及其运行环境,以便使用者了解本软件的使用范围和使用方法,并为软件的维护和更新提供必要的信息。
1.2 参考资料
|
资料名称 |
作者 |
|
自己动手写网络爬虫 |
罗刚 |
|
Web数据挖掘 |
(Soumen Chakrabarti)查凯莱巴蒂 |
|
软件测试 |
肖汉 |
|
精通SQL Server 2008完全自学手册 |
金玉明 |
1.3 术语和缩写词
|
缩略语 |
全意 |
|
爬虫 |
一种自动获取网页内容的程序,是搜索引擎的重要组成部分 |
|
URL |
中文名称为“统一资源定位符”,是互联网上标准资源的地址 |
|
过滤 |
去除网页中不符合需求的内容,例如广告等 |
|
线程 |
爬虫程序运行时的程序调度单位 |
2.软件概述
2.1 软件用途
本软件用于自动获取网页内容,同时具有去广告,分类保存扒取到的文件,网页质量判定等功能。是网上问答系统等搜索引擎的重要组成部分。
2.2 软件运行
本软件运行在PC 及其兼容机上,使用WINDOWS 操作系统,需要eclipse开发环境。软件安装完成后,打开eclipse,导入软件所在路径,打开工程。运行工程下default package包中的MyCrawler.java文件,出现软件主界面。
2.3 系统配置
本软件运行在PC 及其兼容机上,使用WINDOWS 操作系统 ,要求奔腾4以上CPU,512兆以上内存,10G 以上硬盘。软件需要有eclipse开发环境。
2.4 软件结构
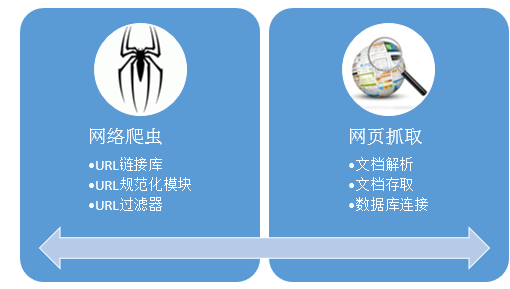
2.5 软件性能
功能测试用例通过率达到94%。爬取的网页达到10^2数量级时,平均用时不超过1.5分钟。
CPU占用率如下表:
|
序号 |
爬取数 |
CPU占用率 (%) |
内存占用率(KB) |
|
1 |
10 |
2.24 |
189400 |
|
2 |
100 |
9.39 |
170552 |
|
3 |
1000 |
27.44 |
164344 |
可靠性,安全性,易用性均经过测试并达到测试要求。
2.6 输入、处理、输出
2.6.1 输入
1) 网络爬取过程开始的源网址。
2) 预期抓取的网页数量。
2.6.2 处理
程序将从源网址(输入1)开始依次爬取下一级链接,爬取到预期爬取网页数量后(输入2)停止爬取。
点击start键开始爬取。
点击close键关闭软件。
2.6.3 输出
1) 已爬取的URL数;
2) 当前爬取URL;
3) 爬取进度;
4) 爬取状态;
5) 爬取的URL;
6) 本地File目录下爬取结果下载的文件内容,包含html等文件。
7) 数据库中保存文件的绝对路径、文件的下载地址及对应URL的网页编码与类型、对当前文件的下载时间、更新时间集、以及最后一次操作时间等信息。
3.软件使用过程
3.1 软件安装
将软件压缩包中的全部文件解压到本地即可。
3.2 运行说明
本软件需运行在WINDOWS操作系统下,并需要安装eclipse开发环境和最新版本的JRE。
配置数据库到Windows(或Windows server)数据源中,数据库名为yuanhang。数据库中包括:被抓取网页的类型、编码等信息;文件下载后在本地的存储路径;文件的下载时间记录、更新时间记录、最后一次更新记录。
软件安装完成后,打开eclipse,导入软件所在路径,打开工程。运行工程下default package包中的MyCrawler.java文件,出现软件主界面。
3.3 控制输入
运行软件出现主界面后,在主界面的URL seed中输入源网址,在主界面how much pages中输入想要抓取的网页数量,点击“start”按钮开始爬取。
3.4 输出文件
在本地File路径下为爬取结果下载的文件内容,包含html等文件。
在数据库中保存本地文件的绝对路径、文件的下载地址及对应URL的网页编码与类型、对当前文件的下载时间、更新时间集、以及最后一次操作时间等信息。
3.5 输出报告
在主界面中会显示已爬取的URL数、当前爬取URL、爬取进度、爬取状态、爬取的全部URL。
3.6 非常规过程
如果出现不可能处理的问题,可以直接与远航1617 小组的技术支持人员联系团队博客:http://www.cnblogs.com/yuanhang1617。
4.软件维护过程
4.1 程序设计的约定
本软件程序是一个单一的运行软件,各个软件子模块的预定如下:
4.2 源程序清单
本软件源程序全部位于default package包中,共包括9个文件:
ConnectServer.java
CraUi.java
DownLoadFile.java
HtmlParserTool.java
LinkFilter.java
LinkQueue.java
MyCrawler.java
Queue.java
Url.java