本次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:duymgzccnews.csv')
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
1)数据保存
import sqlite3 with sqlite3.connect('gzccnews.sqlite')as db: newsdf.to_sql('gzccnews',con=db)
2)数据表的数据查看
with sqlite3.connect('gzccnews.sqlite')as db: df2 = pd.read_sql_query('select * from gzccnews',con=db) df2
截图效果:

3)数据库连接
import pymysql from sqlalchemy import create_engine coninfo = "mysql+pymysql://root:@localhost:3306/gzccnews?charset=utf8" engine = create_engine(coninfo,encoding="utf-8")
4)新建表及相关信息
newsdf.to_sql(name='news',con=engine,if_exists='append',index= False,index_label='id')
截图效果:

二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
本次作业主题是爬取广商教务系统学生成绩:http://jwxw.gzcc.cn/
1.获取广州商学院教务系统登录页面url,以及验证码地址
首先使用浏览器开发者调试工具找到登录页面的准确地址:http://jwxw.gzcc.cn/default2.aspx
然后找到验证码的地址:http://jwxw.gzcc.cn/CheckCode.aspx
将验证码保存让用户输入即可
def login(username,password): ''' 登录方正教务系统(广州商学院) :param username: 学号 :param password: 密码 :return: tuple(cookies,name) 返回一个元组 ''' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36', } login_url = 'http://jwxw.gzcc.cn/default2.aspx' checkcode_url = 'http://jwxw.gzcc.cn/CheckCode.aspx' data=requests.get(login_url) __VIEWSTATE=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)[0] cookies=data.cookies checkcode=requests.get(checkcode_url,cookies=cookies,headers=headers) with open('checkcode.jpg','wb') as f: f.write(checkcode.content) code=input('请输入验证码:') while '-' in code: checkcode = requests.get(checkcode_url, cookies=cookies, headers=headers) with open('checkcode.jpg', 'wb') as f: f.write(checkcode.content) code = input('请重新输入验证码:') post_data={ '__VIEWSTATE':__VIEWSTATE, 'txtUserName':username, 'Textbox1':'', 'TextBox2':password, 'txtSecretCode':code, 'RadioButtonList1':'%D1%A7%C9%FA', 'Button1':'', 'lbLanguage':'', 'hidPdrs':'', 'hidsc':'', }
2.判断登录是否成功
登录时发送POST请求,需要注意要提交一个叫__VIEWSTATE的字段,并且要携带cookies
发送POST后,如果登录成功则返回用户页面,判断即可
resource=requests.post(login_url,data=post_data,cookies=cookies,headers=headers).text if '活动报名' in resource: print('登录成功!') dom_tree=etree.HTML(resource) name=dom_tree.xpath('//span[@id="xhxm"]/text()') name=name[0] print('欢迎回来 '+name) return (cookies,name.split('同')[0]) else: print('登录失败!') exit(0)
3.构造函数
获取成绩信息,并保存在score.csv中
def get_score(cookies,username,name): ''' 获取所有考试成绩,并导出csv :param cookies: cookies :param username: 学号 :param name: 姓名 :return: Boolean ''' headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36', 'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username } first_url='http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+name+'&gnmkdm=N121605' data=requests.get(first_url,cookies=cookies,headers=headers) viewstate=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text) viewstate=viewstate[0] headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36', 'Referer':'http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+quote(name)+'&gnmkdm=N121605' } print(headers) score_url='http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+name+'&gnmkdm=N121605' post_data={ '__EVENTTARGET':'', '__EVENTARGUMENT':'', '__VIEWSTATE':viewstate, 'hidLanguage':'', 'ddlXN':'', 'ddlXQ':'', 'ddl_kcxz':'', 'btn_zcj':'%C0%FA%C4%EA%B3%C9%BC%A8' } scores=requests.post(score_url,cookies=cookies,headers=headers,data=post_data) all=re.compile('<td>(.*?)</td><td>(d+)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td></td><td></td>').findall(scores.text) for i in all: with open('score.csv', 'a', newline='') as f: try: csv_out=csv.writer(f,dialect='excel') csv_out.writerow([i[0],i[1],i[2],i[3],i[4],i[5].replace(' ',''),i[6],i[7],i[8],i[9].replace(' ',''),i[10].replace(' ',''),i[11].replace(' ',''),i[12].replace(' ','')]) except Exception: print('导出失败!') return False print('成绩导出成功!') return True
4.登录
if __name__ == '__main__': print('广州商学院正方教务系统登录') username=input('请输入学号:') password=input('请输入密码:') cookies,name=login(username,password) get_score(cookies,username,name)
登录成功后,截图:

获取成绩,截图:
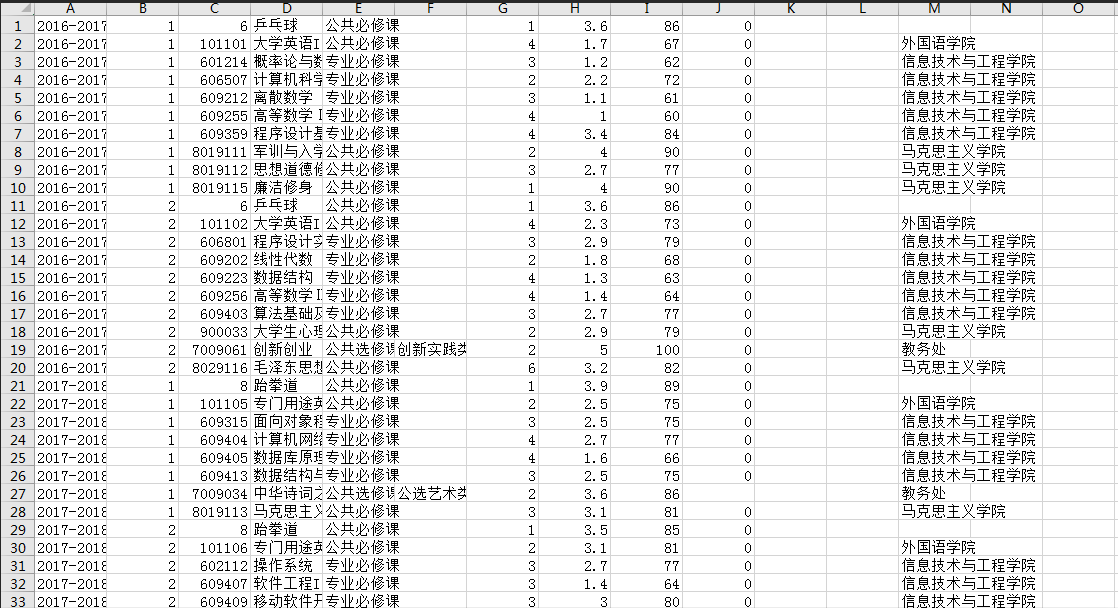
接下来进行相应的成绩分析:
1.总成绩依照分数越高,字体越大的逻辑显示
# 存储过滤后的文本 pd.DataFrame(wcls).to_csv('2.csv', encoding='utf-8') # 读取csv词云 txt = open('score.csv', 'r', encoding='utf-8').read() # 用空格键隔开文本并把它弄进列表中 cut_text = "".join(jieba.lcut(txt))
截图效果:

简要分析:本图汇聚了该生所有的学科成绩(去除慕课网课程分数),从图中可见,移动软件即Android,数据挖掘明显突出,软件工程与程序设计基础较为其次,乒乓球与跆拳道等体育也清晰可见。但是,大学英语、高等数学等大学基础课程模糊不可见。
总的来说,专业成绩明显优势,体育活动亦有较好的发展,基本课程则明显弱势,由于学生的普遍认为,只要注重专业成绩,平时的基本文化课程没什么用处,受到这个观念的影响下,才会有了这样的发展。
2.分析各学期的平均绩点走向

简要分析:从图中可见,每学年度的绩点有小幅度增长的,从大一第一学期,到大三第一学期,从2.2到3.12,每次增长幅度为0.25-0.3,稳定发展。
侧面突出该生的学习态度,从散漫随着时间的推移,过渡到认真求知,是一个良好的方向,这也是全国大学生的一个普遍现象,从大一的迷茫,由于摆脱了高中的压抑环境,不再受到来自校方和家庭的约束,注意力不在学习上,同时还受到对基础文化课程的不注重的观念影响,但随着时间流逝,在不断地求知中,逐渐认清了方向,越临近毕业,大学生也就越成熟稳重。
3.将所有学科统一分成六大类
由于课程较多,为了分析该生在哪方面比较擅长,应对未来的发展就业,有个明显的方向,特将全部课程统一区分为六大种类
程序类,网络类,大数据处理类,web架构类,体育修身类,其他(包括基础文化课程)

利用饼图,将六类平均绩点显示出来,由于部分类别课程较少,部分类别课程明显较多,该饼图的数据仅供参考,分析的价值为一般,目前只能利用已知的信息做个大概分析。

简要分析:从图中可见,体育修身类(体育活动与思政文化修养)突出,网络internet类紧随其后,程序类,数据类,网络类发展均衡,其他类并不明显,
以专业方向来看,首先剔除体育类与其他类,其余四类都是相差不大,但结合上方成绩表可看出,该生的网络类是比其他类别更具优势,web架构方面也较为精通,而程序类中,Android课程也比较优秀,但c++语言却没有十分掌握,软件工程方面也并不好,程序类别中有好的地方也有不好的地方,可看出该生对这方面没有绝对的把握,并不稳定。从就业方向来看,选择前端工程师,或网络方面的工作比较轻松一些,大数据是近期热门职业,也可以自学,对这方面有兴趣的话,也可以发展。