nask.exe应该就是nas kit(nas开发工具的意思),由于这个编译器是作者自己写的,所以这种汇编语言应该是作者改造出来的,所以我叫它nas汇编语言。
作者说nask是模仿nasm语法的,关于nasm:Linux 汇编器:对比 GAS 和 NASM
前言
本文标题虽为二进制,但其实一般大家都看十六进制 ,因为每4位二进制(4bits)就对应一位十六进制数(hex),如

作者也这样说:为了方便清晰地表示二进制,我们用十六进制来看

如果计算进制有困难,可以使用在线工具或Excel,字符转16进制的也可以自己在网上搜索一下。
开始编写nas
首先 我们对nas汇编语言的 RESB DB DW(WORD) DD(DWORD)很陌生,所以应该了解一下
另外简记一下大小顺序: BWD不玩刀
B 1字节 8bits
W 2字节 16bits
D 4字节 32bits
先安装Nodepad++以及它16进制查看器插件:新版Notepad++加十六进制查看的插件HexEditor
然后我们在01_day下建几个nas文件并写入内容,如
上面是文件名,下面是内容 当然如果你喜欢命令行,可以文本替换三个换行后用echo 重定向快速写入文本文件 test-RESB.nas RESB 9 testDB_hex.nas DB 0x3e testDB_char.nas DB "Hello" testDB_dec.nas DB 3 test-DW.nas DW 3 test-DD.nas DD 3
然后逐一手动编译,以test-DD.nas为例
把目录z_tools放到和01_day同一级目录下,打开cmd执行如下
..z_tools ask.exe test-DD.nas test-DD.img
当然我写了个脚本


1 @ECHO OFF 2 setlocal enabledelayedexpansion 3 echo ---find nas---- 4 for /R %cd% %%f in (*.nas) do ( 5 6 rem 文件名,无后缀文件名 7 SET "FILE_PATH_NO_EXT=%%~nxf" 8 SET "OUTFILE_NO_EXT=%%~nf" 9 10 ....z_tools ask.exe !FILE_PATH_NO_EXT! !OUTFILE_NO_EXT!.img 11 )
再用nodepad++(View in HEX)查看每个编译出来的img的十六进制,这样我们就对这几个nask汇编指令有很清晰的认识了,
之后遇到不清楚的指令,我们也可以这么玩
然后我发现DD 3和DW 3在我windows系统上是一样的???都是hex(03 00),
由于用的是“小端”的排列方式,所以是hex(0300)而非hex(0003),关于大端小端,本文底部有说明链接,但还是推荐你先看完正文。
但是为什么16bits和32bits得出来结果是一样的?不应该一个03 00一个03 00 00 00吗
但是DD 512和DW512就不一样的了,一个hex(02 00)hex(02),虽然dec 512的确是hex 200,但是这位数完全不对啊
???算了,继续看下面的
更多玩法:
开两个notepad++窗口和一个cmd,一个改,一个编译,一个看,
可以启用实时刷新功能:Notepad++自动刷新文本
(注意:这个实时刷新是需要你点击窗口时才刷新的,例如你改了test.txt,而test.txt显示在窗口1,但是此时你在看窗口2,那么就需要你点击一下窗口1,这样才会刷新。)
以下是我的骚操作:
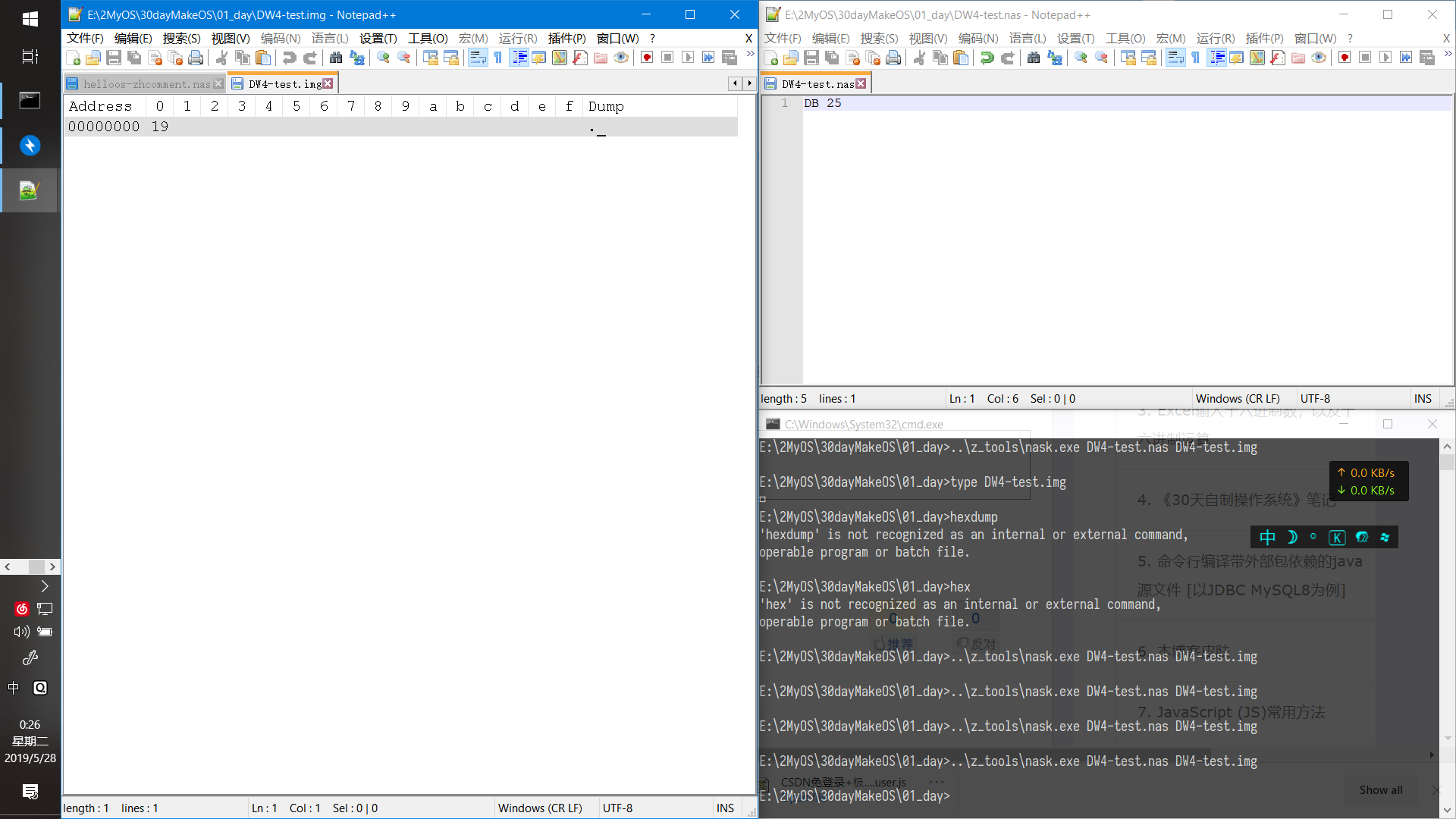
25(dec) = 19(hex)
反向验证一下
1* 16^1 + 9* 16^0=25
分析nas汇编代码
一段段来,先复制一小段,分析

记下末尾地址(如此处是0xd),然后继续添加一小段分析
由于我们还不知道DW和DD是怎么回事,所以可以DW或DD为分段点
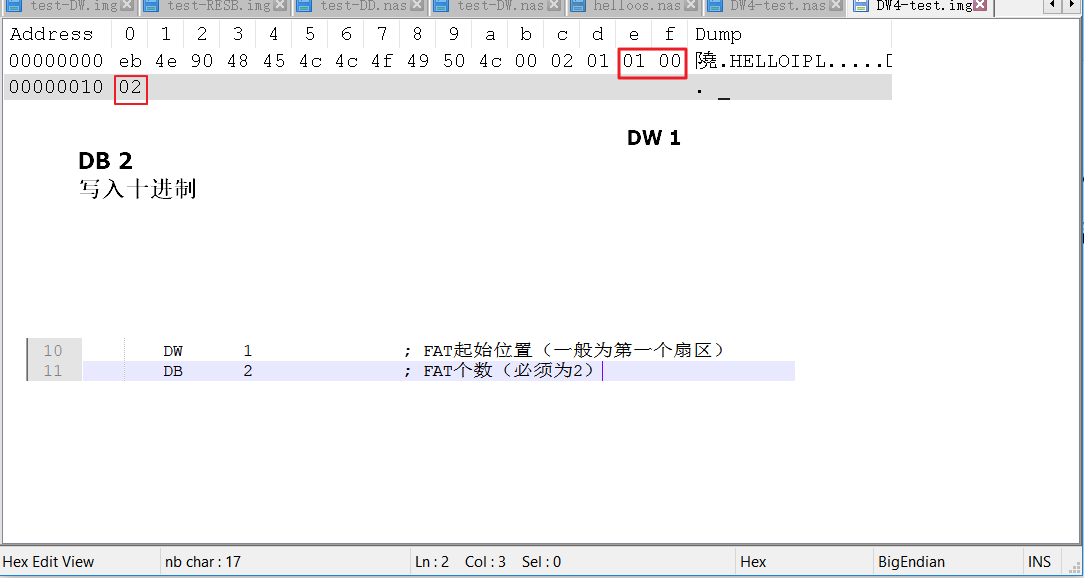
DW 1 ,DB 2这一段我编译了两次,第一次是因为看到编译结果比预想中多了1bits,所以重新编译了一次,就正常了....结合上面512的例子,所以究竟是编译器的问题还是Notepad++插件的问题?懵逼中
可能会有人笑我,为什么抱着一本 古老到还在讲软盘却讲不清楚很多细节 的书就不放了呢,还逐个bit去看,
其实我个人觉得应该仔细去看这一部分,因为nask.exe不是全平台的,但是仔细研究之后,我们也可以用其他的汇编编译器在各平台上写引导区、写操作系统的
回到DB DW DD,B是8位二进制的, 2^8=256
DW (WORD)是16bits,所以 2^16=65536
DD (DOUBLE-WORD)是32bits,得 2^32=4294967296
现在我们知道了为什么不用DB 512,因为DB是8bits最多拥有256个十进制数,不可能容纳512这个数。
而DD,又会不会是因为编译器的优化让DD在数不够大时自动降级为DW呢?我们还不清楚,希望后面能找到答案吧。
更详细的图解
Day1的helloOS.nas前半部分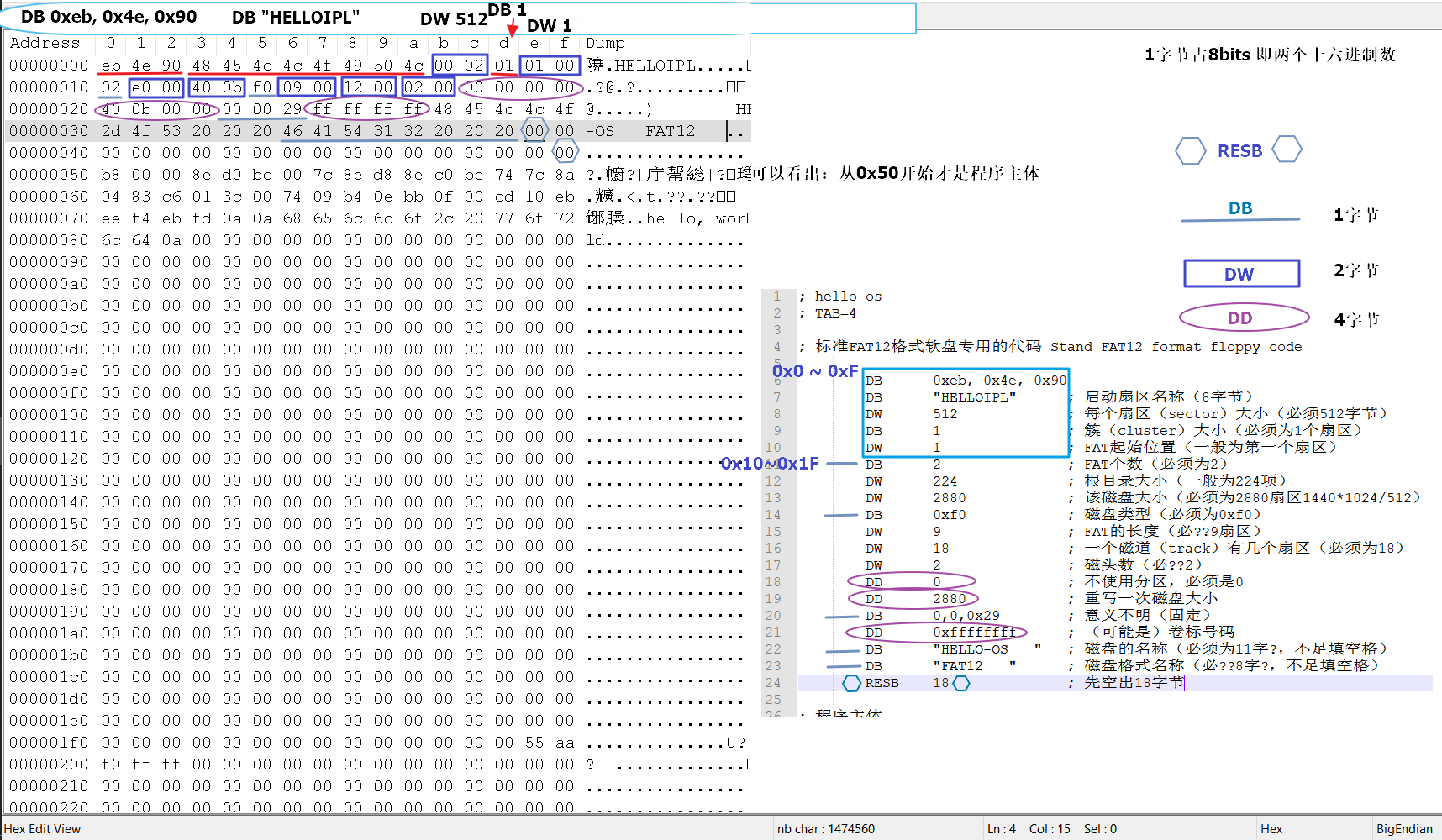
后半部分(程序主体、信息显示部分、启动扇区以外部分输出)
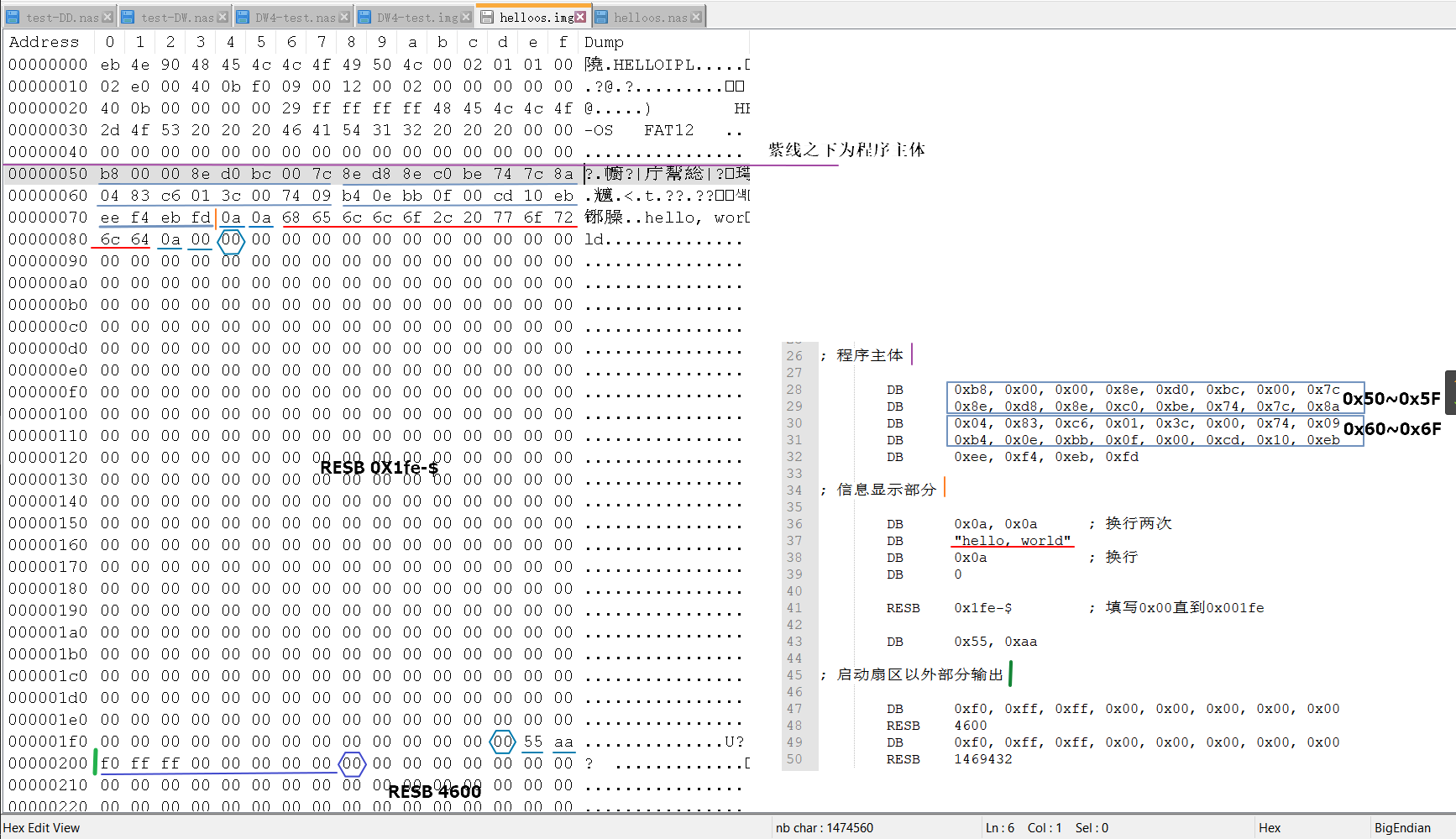
从这里可以看出只有DB不够用时才会用更大容量的DW、DD
但是里面源码里出现了DW 2880和DD 2880


所以我们不禁会想,这究竟是用法呢?还是说只是作者为了标识19行的2880才用了DD(如果是这样的话,那么DD在数值只需要16bits时等价于DW?)
怒了,想办法测试一下:
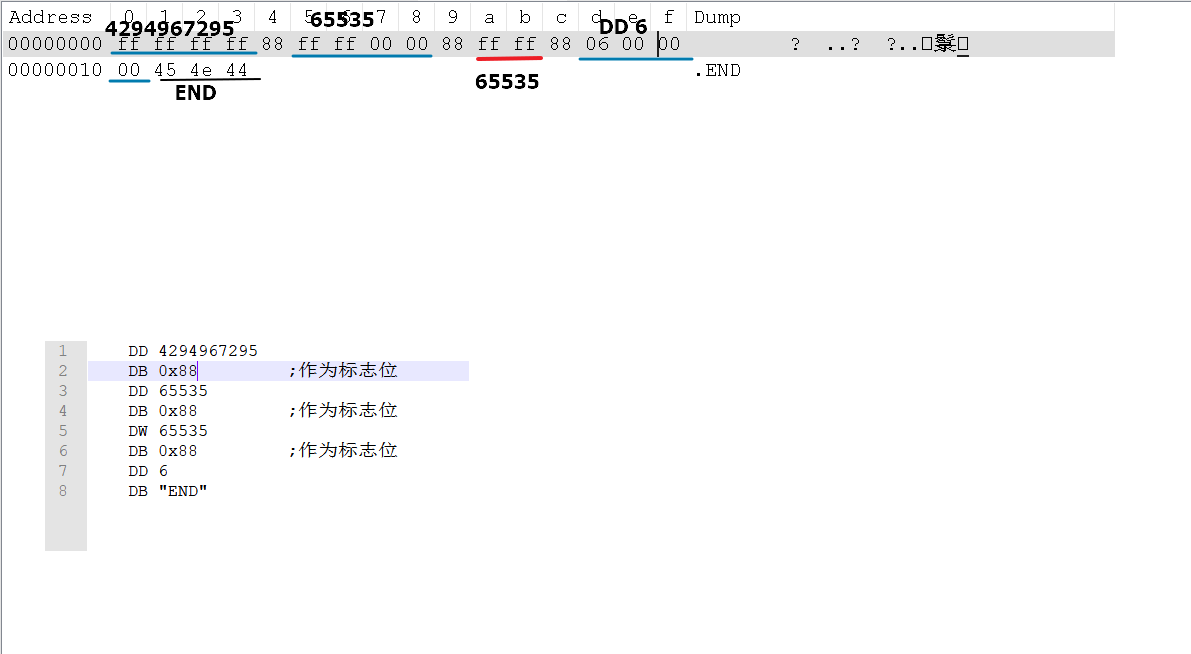
又对了,那我们接下来排除一下hex编辑器的问题吧,我把之前出bug 的语句再编译一次。
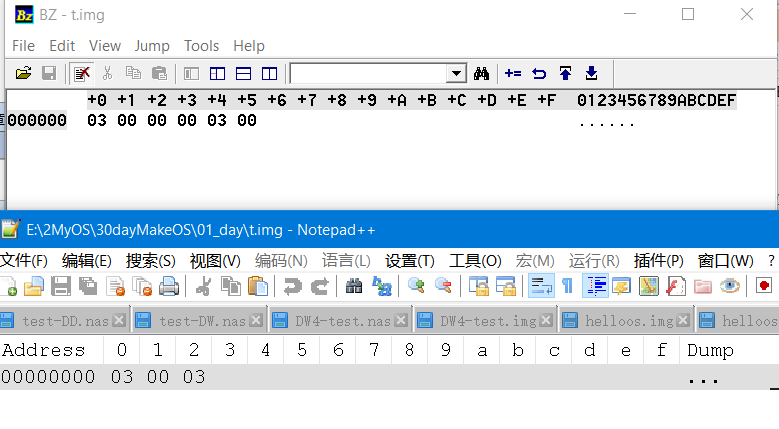
和Notepad++插件HexEditor作者沟通后,发现是Notepad++的bug....貌似在文件长度很短的情况下才有这个bug
所以DB是写入1字节,DW是写入2字节,DD是写入4字节。 0x01这个地址能容纳1个字节,
事实证明作者没骗我们,并且他考虑的很周到,用不同的工具可能会有不一样的效果,毕竟bug这东西谁能百分比确定呢?
但是HexEditor确实好用,那我还是继续用吧,小心点就行。
推荐
VSCode的十六进制查看器插件 HexDump
跨平台的十六进制编辑器 wxMEdit
另外,关于字节序(大端小端):
详解大端模式和小端模式 或 http://bdxnote.blog.163.com/blog/static/8444235201091054458112/
[本文已完整,但可能会偶尔补充点什么]