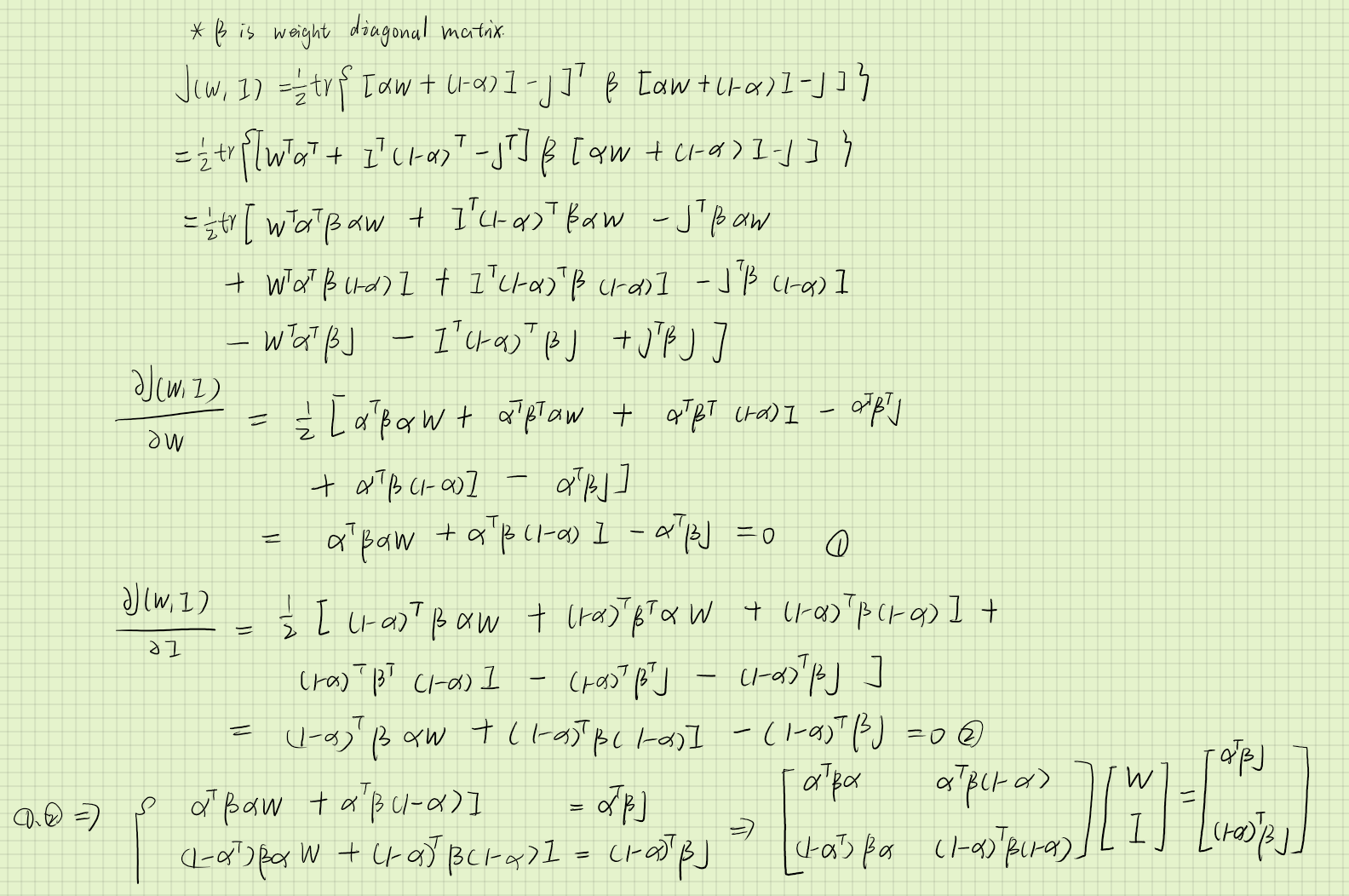References:
1.Automatic watermark detection and removal
6.矩阵求导
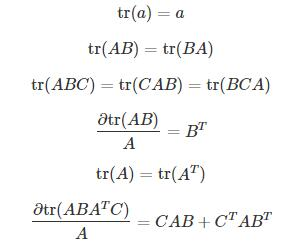
接2证明带权重的IRLS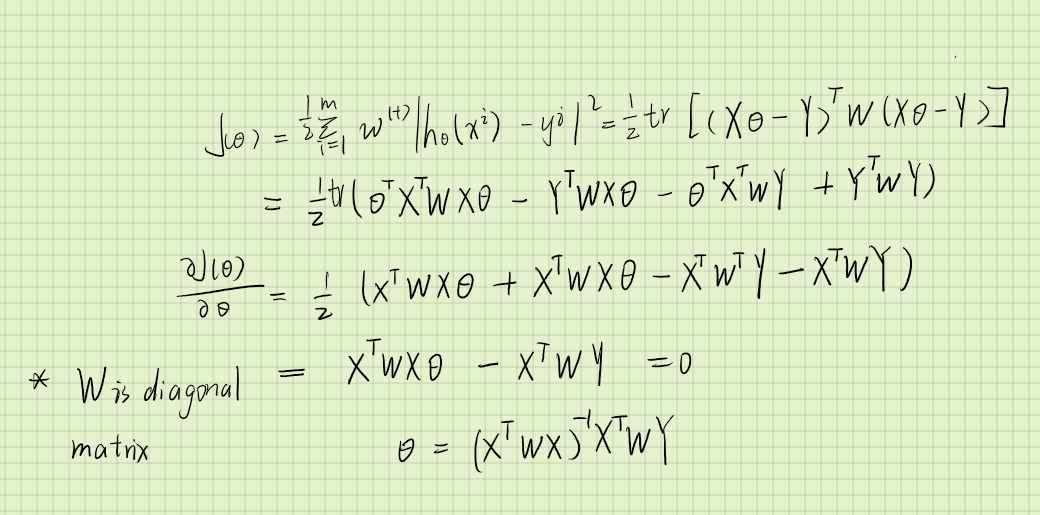
Background:
简述一下本文的大致思路,加了水印的图像由原图、水印、α蒙版值三部分构成:J = α*W + (1 - α) * I
引入梯度,自然图像相邻像素间变化平缓,因此梯度期望为0
known property of natural image gradients to be sparse, i.e., the chance of having strong gradients at the same pixel location in multiple images is small. Hence, E [∇Ik] ≈ 0.
Optimization:

where
is a robust function that approximates L1 distance (p is omitted for brevity).The terms Ereg(∇I) and Ereg(∇W) are regularization terms that encourage the reconstructed images and the watermark to be piecewise smooth where the gradients of the alpha matte are strong.

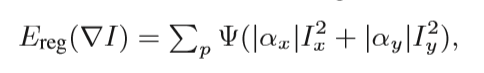

对最优化方程化简
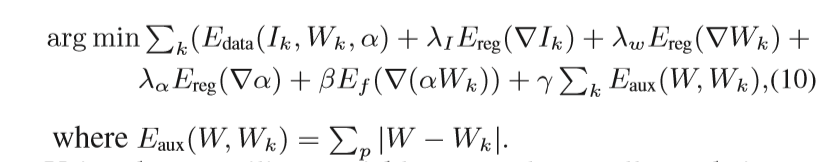
在求解过程中,分两次用IRLS。其一,更新IK ,WK ;其二,更新α。
详细介绍第一步。


# robust function def Func_Phi(X, epsilon=1e-3): return np.sqrt(X + epsilon**2) def Func_Phi_deriv(X, epsilon=1e-3): return 0.5/Func_Phi(X, epsilon)
因为引入了鲁棒函数 phi()以接近L1 distance, 故此时我们的p值为1。每次迭代的权值w为 1/(2*sqrt(X+0.001^2))
*本文中全部输入矩阵均为np.diags(matrix.reshape(-1))构造,即均为对角矩阵
phi_data = diags( Func_Phi_deriv(np.square(alpha*Wk[i] + (1-alpha)*Ik[i] - J[i]).reshape(-1)) ) phi_W = diags( Func_Phi_deriv(np.square( np.abs(alpha_gx)*Wkx + np.abs(alpha_gy)*Wky ).reshape(-1)) ) phi_I = diags( Func_Phi_deriv(np.square( np.abs(alpha_gx)*Ikx + np.abs(alpha_gy)*Iky ).reshape(-1)) ) phi_f = diags( Func_Phi_deriv( ((Wm_gx - alphaWk_gx)**2 + (Wm_gy - alphaWk_gy)**2 ).reshape(-1)) ) phi_aux = diags( Func_Phi_deriv(np.square(Wk[i] - W).reshape(-1)) ) # E_reg_deta_I phi_rI = diags( Func_Phi_deriv( np.abs(alpha_gx)*(Ikx**2) + np.abs(alpha_gy)*(Iky**2) ).reshape(-1) ) # E_reg_deta_W phi_rW = diags( Func_Phi_deriv( np.abs(alpha_gx)*(Wkx**2) + np.abs(alpha_gy)*(Wky**2) ).reshape(-1) ) # sobel^T * c * E_reg_I * sobel L_i = sobelx.T.dot(cx*phi_rI).dot(sobelx) + sobely.T.dot(cy*phi_rI).dot(sobely) # sobel^T * c *E_reg_W * sobel L_w = sobelx.T.dot(cx*phi_rW).dot(sobelx) + sobely.T.dot(cy*phi_rW).dot(sobely) # sobel^T * E_f * sobel L_f = sobelx.T.dot(phi_f).dot(sobelx) + sobely.T.dot(phi_f).dot(sobely) # alpha^T * L_f * alpha + gamma * E_aux A_f = alpha_diag.T.dot(L_f).dot(alpha_diag) + gamma*phi_aux bW = alpha_diag.dot(phi_data).dot(J[i].reshape(-1)) + beta*L_f.dot(W_m.reshape(-1)) + gamma*phi_aux.dot(W.reshape(-1)) # (1-alpha) * E_data * J bI = alpha_bar_diag.dot(phi_data).dot(J[i].reshape(-1)) A = vstack([hstack([(alpha_diag**2)*phi_data + lambda_w*L_w + beta*A_f, alpha_diag*alpha_bar_diag*phi_data]), hstack([alpha_diag*alpha_bar_diag*phi_data, (alpha_bar_diag**2)*phi_data + lambda_i*L_i])]).tocsr() b = np.hstack([bW, bI]) x = linalg.spsolve(A, b) # Solve the sparse linear system Ax=b jointly to get WK IK Wk[i] = x[:size].reshape(m, n, p) Ik[i] = x[size:].reshape(m, n, p)
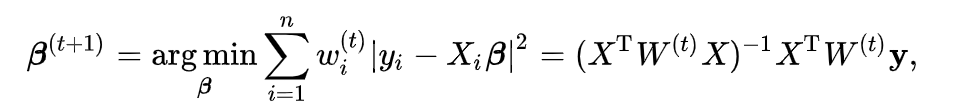
将inverse matrix消去,左右同左乘XTWX。得到 XTWXβ = XTWy。
以E_data项为例, αW + (1 - α)I = J
bW = alpha_diag.dot(phi_data).dot(J[i].reshape(-1)) + beta*L_f.dot(W_m.reshape(-1)) + gamma*phi_aux.dot(W.reshape(-1))
bI = alpha_bar_diag.dot(phi_data).dot(J[i].reshape(-1))
b 指代XTWy,其中y为原图J,对于IK,1-α为其X(其中据帧均有np.diags()构造),E_data为其W;
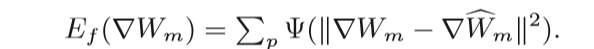
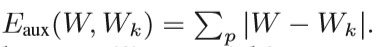
phi_f = diags( Func_Phi_deriv( ((Wm_gx - alphaWk_gx)**2 + (Wm_gy - alphaWk_gy)**2 ).reshape(-1))
L_f = sobelx.T.dot(phi_f).dot(sobelx) + sobely.T.dot(phi_f).dot(sobely)
bW = alpha_diag.dot(phi_data).dot(J[i].reshape(-1)) + beta*L_f.dot(W_m.reshape(-1)) + gamma*phi_aux.dot(W.reshape(-1))
sobel as gradient image,除了与IK相似的项以外,对于WK多了两项E_f,E_aux要复杂一点。(对于E_f因为构造L_f是按β左部构造,故要dot W_m消去)
L_i = sobelx.T.dot(cx*phi_rI).dot(sobelx) + sobely.T.dot(cy*phi_rI).dot(sobely)
L_w = sobelx.T.dot(cx*phi_rW).dot(sobelx) + sobely.T.dot(cy*phi_rW).dot(sobely)
L_f = sobelx.T.dot(phi_f).dot(sobelx) + sobely.T.dot(phi_f).dot(sobely)
A_f = alpha_diag.T.dot(L_f).dot(alpha_diag) + gamma*phi_aux
A = vstack([hstack([(alpha_diag**2)*phi_data + lambda_w*L_w + beta*A_f, alpha_diag*alpha_bar_diag*phi_data]), hstack([alpha_diag*alpha_bar_diag*phi_data, (alpha_bar_diag**2)*phi_data + lambda_i*L_i])]).tocsr()
A指代XTWX ,因为Edata是二元线性涉及联合求解,过程如下。根据矩阵性质可得,其他系数要放在主对角线上
以下为带权重的推导