抓取豆瓣top250电影数据,并将数据保存为csv、json和存储到monogo数据库中,目标站点:https://movie.douban.com/top250
一、新建项目
打开cmd命令窗口,输入:scrapy startproject douban【新建一个爬虫项目】
在命令行输入:cd douban/spiders【进入spiders目录】
在命令行输入:scrapy genspider douban_spider movie.douban.com【douban_spider为爬虫文件,编写xpath和正则表达式的地方,movie.douban.com为允许的域名】
在pycharm打开创建的douban项目,目录结构如下:
二、明确目标
分析网站,确定要抓取的内容,编写items文件;
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#序号
serial_number = scrapy.Field()
#电影名称
movie_name = scrapy.Field()
#电影简介
introduce = scrapy.Field()
#星级
star = scrapy.Field()
#评价数
evaluate = scrapy.Field()
#描述
describe = scrapy.Field()
三、制作爬虫
编写douban_spider爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
#爬虫名,不能跟项目名称重复
name = 'douban_spider'
#允许的域名,域名之内的网址才会访问
allowed_domains = ['movie.douban.com']
#入口url,扔到调度器里边
start_urls = ['https://movie.douban.com/top250']
#默认解析方法
def parse(self, response):
#循环电影的条目
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']//li")
for i_item in movie_list:
#item文件导进来
douban_item = DoubanItem()
#写详细的xpath,进行数据的解析
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']//a//span[1]/text()").extract_first()
content= i_item.xpath(".//div[@class='info']//div[@class='bd']//p[1]/text()").extract()
#多行结果需要进行数据的处理
#douban_item['introduce'] = ''.join(data.strip() for data in content)
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//div[@class='star']//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']//span/text()").extract_first()
#将数据yield到piplines中
yield douban_item
#解析下一页规则,取的后一页的xpath
next_link = response.xpath("//span[@class='next']//a//@href").extract()
if next_link:
next_link=next_link[0]
#yield url到piplines中,回调函数callback
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
四、存储内容
将数据存储为JSON格式:scrapy crawl douban_spider -o test.json
将数据存储为CSV格式:scrapy crawl douban_spider -o test.csv【生成的CSV文件直接打开会是乱码,先利用Notepad++工具打开,编码格式改为utf-8保存再重新打开即可】
将数据保存到monogo数据库中:
# -*- coding: utf-8 -*- import pymongo mongo_db_collection # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class DoubanPipeline(object):
#创建数据库连接 def __init__(self): host = '127.0.0.1' port = 27017 dbname = 'douban' sheetname = 'douban_movie' client = pymongo.MongoClient(host=host, port=port) mydb = client[dbname] self.post = mydb[sheetname]
#插入数据 def process_item(self, item, spider): data = dict(item) self.post.insert(data) return item
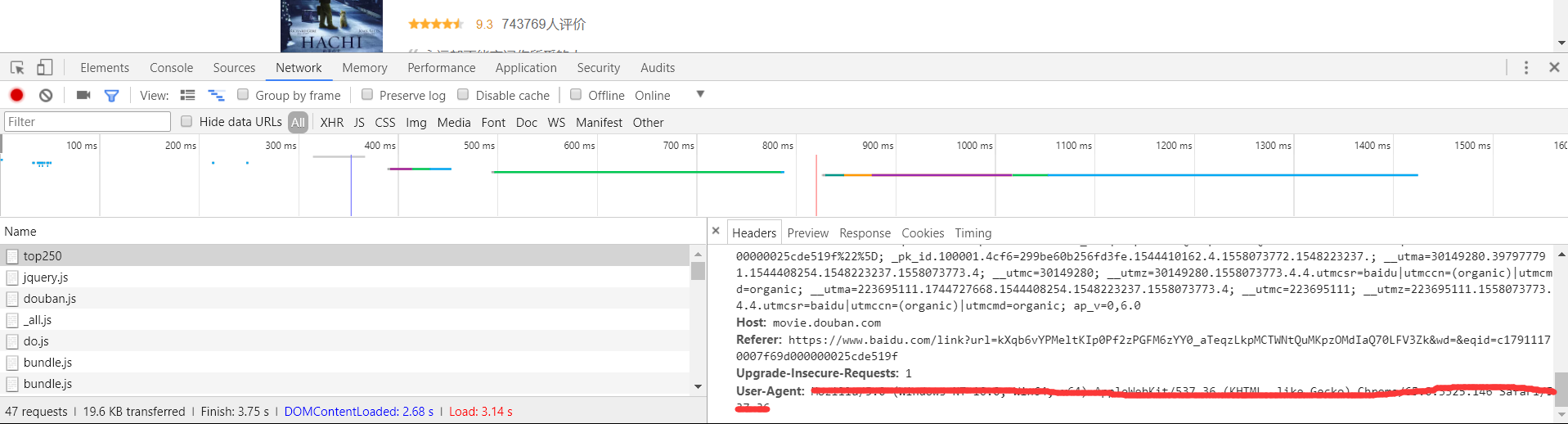
打开settings文件的USER_AGENT选项,删除里边内容,到网站找一个正确的USER_AGENT粘贴进来。【方法:打开豆瓣top50网站,按F12开发者选项,选择Network-All,刷新页面,选择top250,右侧Headers最下边即为USER_AGENT,如下图所示】
打开settings文件的ITEM_PIPELINES
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
设置启动文件
在douban文件下新建一个main.py文件,作为爬虫的启动文件,避免到命令窗口启动爬虫项目。
main文件内容如下:
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())