前言
58作为一个分类信息网站,作为信息服务的提供平台,我们的客户在我们的平台的交易链路,抽象后可以描述为:商户购买服务->将购买后的资源托管到资源中心->商家消耗相关资源->收入的核算。
具体业务流程如下图:
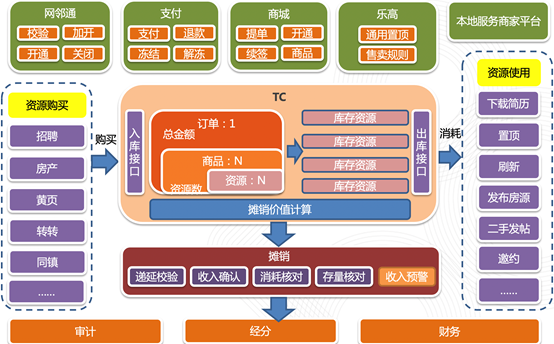
图0-1 资源中心业务流程图
资源中心就是我们交易链路中客户购买相关服务后将相关服务资源托管的管理中心。是我们进行资源管理及后续收入核算的核心服务。
其在整个交易链路所处的位置为:
1、购买链路:房产、招聘等各大业购买平台->支付->资源中心。
2、消耗链路:房产、招聘等各大业使用平台->资源中心->摊销算收入->业绩、经分进行相关数据处理。
可见其在58的整体交易链上的重要性。无论是在商户购买58相关服务还是商户在实际使用58付费服务的过程中,都需要和资源中心进行交互。那么,如何治理好这个服务就是一个非常重要的课题。本文我们将从高可用性、性能优化两个方面介绍服务治理在资源中心的具体实践。
一、高可用应用架构演进
系统的建设并非一蹴而就的。资源中心的高可用,也是经过2年的不断建设演进,达到目前的4个9的可用级别的。我们的技术演进,既有我们通过技术的实践,主动优化的,也有在使用场景中遇到的问题,血泪教训后的填坑补丁。
1、高可用的理论框架

图1-1 高可用理论架构
如上图,从通用的高可用架构理论上,一个高可用架构通常包含高可用的硬件架构、高可用的应用、高可用的服务、高可用的数据、高可用的软件质量保证及最后的相关监控。对于硬件、网络、Nginx、DB、MB等相关基础设施,通过58私有云作为IAAS/PAAS直接提供给我们服务,对软件的质量保障和后续的相关监控,也有相关部门提供了完整的支持,也不是我们核心要点。这里核心介绍高可用服务的建设。
2、我们的具体实践
高可用服务的建设可以分为分级管理、超时设置、异步调用、服务降级、幂等设计这几个方面。
2.1分级管理
分级管理在实践中的难点是统一跨部门之间对重要性的认知。我们通过跨部门协作,制定共同的服务可用性OKR。完成服务重要性的协同认知。
在认知一致的基础上,基础运维部将我们的服务作为最高级来进行。首先是我们在私有云的容器,1是通过跨机柜,跨机房等方式,尽量避免硬件层面问题带来的风险;2是独立部署,避免混合部署,其他服务带来的潜在风险。其次在数据库层面上,采用最新的硬件进行独立部署。同时进行任务的集群隔离,让DBA单独拿出一个从节点专门用来进行DB相关任务处理,与处理线线上请求的机器进行隔离保障性能。最后是沟通机制上,针对我们的服务,单独安排独立接口人,负责相关问题的处理。保障相关问题发生后,能够第一时间进行处理。
同时,针对不同的请求方,我们设置了不同的容器分组,做到不同业务间的分级管理。保障不同业务组之间不会因为流量的暴涨影响彼此。
2.2超时设置
为什么要进行超时设置呢?
由于下游服务响应过慢、线程死锁、线上BUG等一系列原因导致我们作为调用方调用之后一直没有响应。从而最终导致用户请求长时间得不到响应,同时在长时间占有线程资源甚至会拖垮整个服务影响其他正常请求。所以我们应该进行超时设置,这是微服务中快速失败的一个基本手段。
第二个问题,我们该如何设置呢?
通常有两个层面的超时:服务级超时、接口级别的超时。服务级别的超时时间一般以最慢接口的耗时时间为基准。而且大部分框架都只会有服务级的超时设置,很少有接口级的超时设置。接口级的超时设置,没有必要所有接口都设置,仅针对流量极大、性能要求较高的接口进行单独设置就行。这里教大家一个小Tips:可以使用位于JUC包中的Future进行接口级的超时设置,简单有效。
第三个问题,服务超时时我们该如何处理呢?
基于这个这个问题,我们需要从上下游、流量、业务场景这三个维度进行考量。
超时的处理手段一般有两种:重试、异常快速返回。重要的写事务场景需要重试,我们要尽最大努力保证事务成功。流量较大的接口一般不适合重试,直接返回异常就好,最极端的场景下容易导致流量翻n倍,导致后面的链路奔溃。
2.3异步调用
异步调用可以分为同进程下的线程异步和进程间的异步调用。在最初的架构设计中,我们针对非核心流程但是相对关系较为紧密的内容做了单进程下的异步。使用的Disruptor队列异步写日志。用Event Bus异步化非核心流程。系统平稳运行了多年,以至于我们极少关注我们的非核心异步相关的服务。但是,一次线上事故还是给了我们深刻的教训。
2020年8月,突然有人反馈服务大量超时。我们通过我们的监控发现我们的请求大量积压,有一组服务处于无法提供服务的状态。经过比较发现,这组服务依赖的日志写入数据库出现超时。导致异步写日志的线程池创建了大量等待线程,进而导致正常处理请求的线程所能占用的CPU时间大大降低,最终大致正常请求超时并出现雪崩现象。这里有我们线程池参数设置不合理的原因,同时,也提醒我们,在同进程下异步,在出现小概率事件之后,依然可能影响到我们的服务可用性。针对这种情况,我们整体梳理了我们的核心流程和非核心流程。将非核心流程采用消息的方式,进行进程间隔离。进行服务治理完成之后我们大概的服务拓扑图如下图:
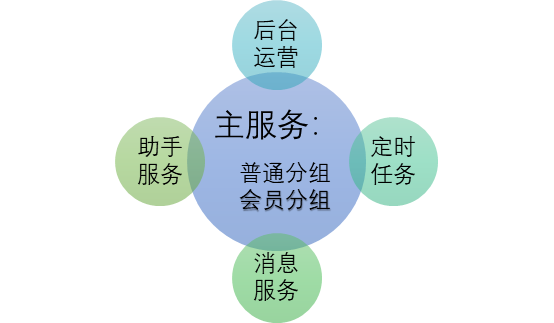
图1-2 资源中心服务拓扑图
2.4服务降级
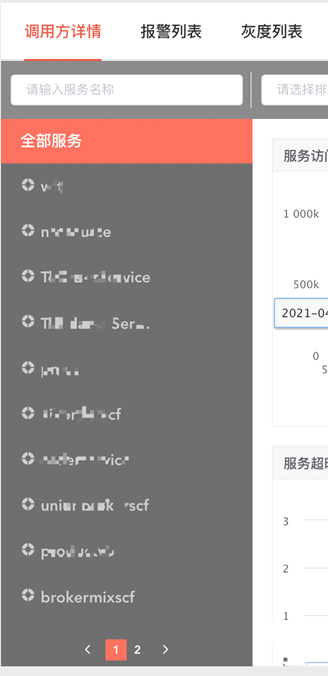
图1-3 资源中心依赖方列表
如上图我们的服务拆分了非核心依赖之后还有十几个核心依赖。假设每个服务都是4个9高可用的服务,99.99^10≈99.9%我们的服务可靠性立马下降了一个数据量级,极大的影响了服务的稳定性。
2020年10月28日上午由于下游的某一个服务出现问题,导致30%的流量持续将近3分钟不可用。如下图:
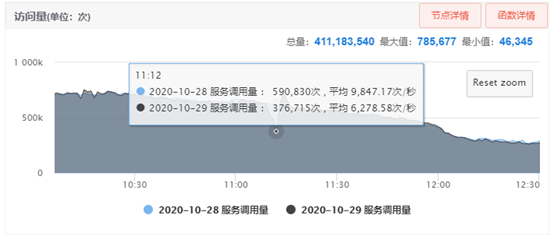
图1-4 资源中心流量监控
30%是个什么概念呢?资源中心的核心服务日访问量4.5亿+,峰值近百万QPM。30%持续3分钟大概100万的请求不可用。所以降级对我们来时势在必行。
首先我们团队仅仅4个人,还得花90%的时间处理业务需求,所以自己造轮子是不可取的。就成本来说开源框架也是极好的选择。业内知名的几款降级框架对比如下图:
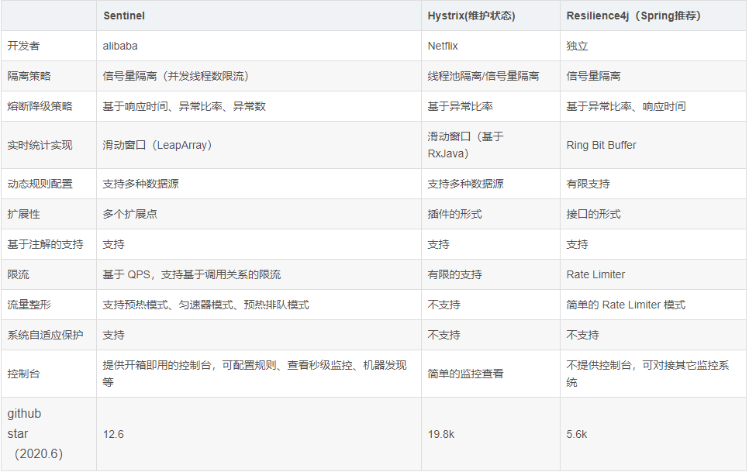
表1-1 降级开源框架比较
最终降级组件我们选的是Sentinel。首先先不考量Resilience4J因为其缺少生产级别的配套设施,相关监控系统以及控制台,我们无法感知到内部运行情况以及出现问题时无法从外部人工接入。再说Sentinel与Hystrix相比我们看中其源码简单、异常处理灵活两大特点。我们大部分接口平均耗时在2ms以后,所以我们果断采取信号量隔离机制,此时Hystrix另外一个优点线程池个隔离对我们来说意义也不大,所以选择了Sentinel。
为什么我们会将异常处理作为选择Sentinel的一个点呢?Hystrix在进行降级阀值计算时,所有的异常都会被统计,其实正常的业务异常是不需要被统计的,例如有的服务接口参数校验不通过时会抛异常,这时因为参数不合法而触发降级是不合理的。所以我们只针对超时、服务挂了等几个特殊异常才会进行降级处理。
组件选择好之后该怎么实现呢?
我们本着:关注点聚焦业务、将降级工具化的思想,利用自动扫包工具+RPC框架过滤器机制设计我们的组件。实现机制如下图:
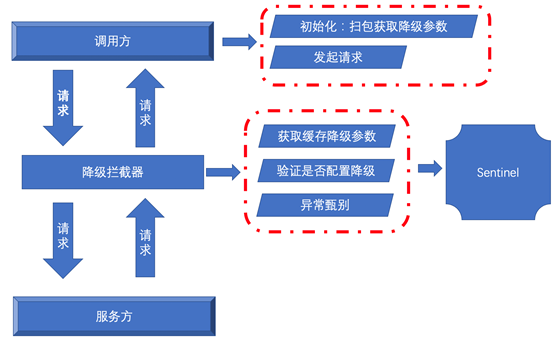
图1-5 资源中心降级方案
我们的组件在使用降级的时候只需要两步就可以:1、实现要降级的接口,定义Fall Back类;2、要Fall Back方法上以注解的形式配置降级参数。
参数如何降级参数如何设置呢?
我们进行参数设计是需要遵循两个原则:普通网络抖动不触发降级,尽可能快的发现发现服务异常进入降级状态。
我们的做法是:
1、 统计过往服务正常状态下由于网络抖动触发的超时量;
2、 以这个量基准与当时的请求量相比较得到降级触发的阀值;
3、 开放在线手动微调接口,对其参数进行微调,以保证设置的参数达到最优效果。
2.5幂等防重设计
我们采用两层防护措施进行防重设计。第一层DB层,幂等的key用唯一索引,保证DB底层只有一条数据入库。第二层应用层,我们采用基于Redis的幂登锁来保证数据的唯一性。引入第二层的原因是减少DB的压力。第一层是兜底层,防止Redis挂了无法进行防重。
3、目前我们的架构
经过我们的实践和建设,形成了我们目前的整体架构:

图1-6 资源中心系统架构
二、性能优化之路
在保障高可用的前提下,作为支持商家使用的基础服务,从性能上能够快速响应,也是我们的重中之重。在性能优化的道路上,我们也介绍一下我们的一些实践经验。
1、服务外部优化
我们基于Mongo提供日志流水的查询,经过我们进行索引优化后,还存在稍微量大一点的数据就会超时。就我们查询的数据量来看在MySQL下一点问题也没有。经过我们与DBA的长期观察与解决,由于投入的人力、时间成本有限以及社区没有相关的问题的解决方案,最终没有找到问题的根本原因从而解决问题。
不能再一颗树上吊死,我们换了另外一种思路,换个存储介质是否可以?
1、 Mongo存的是操作日志,不存在更新的为,数据比较好迁移
2、 Mongo运维人员较少而且大数据平台拉取数据支持的不友好
经过分析确实可行,我们最终选择了TiDB。三方面原因:
1、 不需要我们应用层进行分库分表,性能也能满足我们的需求;
2、 运维以及公司的基础环境相对比较完善投入的人力成本以及硬成本比较好;
3、 社区比较活跃遇到棘手问题容易解决。
最终我们经过大概10个人天的时间从迁移数据到下掉双写代码。而且效果非常好,原来200左右的超时量,下降到50以内。
2、服务内部优化
2.1、JVM调优
每次服务启动或者重启时都会有一段时间的超时。我们通过JSTAT命令监控服务,我们发现服务在每次启动的时候都会有4次FGC,接下来我们观察GC日志发现4次FGC的原因是因为元空间不够了,最终4次GC后元空间的大小为100多M,最终我们将JVM的参数调整为:MateSpace=256m。为什么不是128呢?给未来预留余地,防止未来随着项目的元数据增多再次发生同样的问题。
启动时FGC是没有了,但是我们发现我们的服务由物理机迁移到docker云平台后,YGC的时间大大的增加了,几乎每次YGC时都会有服务超时。当时我们的新生代配置是10G空间,按照默认Eden和两个Survivor的比例是8:1:1新生代的空间是老年代的8倍。我们的物理机的配置是32核128G而我们的云机器是8核16G,CPU核数少了四倍,内存少了8倍。总所周知JVM在进行GC处理的时候主要是利用CPU进行内存整理,算是一个CPU密集型操作。现在CPU计算能力减少了4倍GC的耗时理所当然的就要增加了。
这时我们并没有贸然的增加云机器的配置,因为我们日常8核16G其实基本上够用了,没有必要为了YGC的问题额外的浪费成本。我们也没有贸然的将现有的新生代减少4倍。这样新生代空间骤然减少这么多倍,可能会带来更加频繁YGC的风险,导致服务整体耗时会更慢,甚至会出现线上事故。我们采取较为缓和的手段,一点一点减少新生代大小以及减少Eden以及Survivor的比例。最终,经过我们反复尝试将JVM参数调至:-Xmn:8g -XX:SurvivorRatio=4。
2.2、分布式锁的优化
在优化之前系统中存在两个问题:
1、 业务峰值时期会有因为抢悲观锁而等待超时最终导致导致交易失败的问题;
2、 基于Redis实现的分布式锁,依赖Redis的可用性。
上面这两个问题的最好解决办法就是无锁化。理想是美好的但是现实有一定的阻碍:业务上资源的消耗和转移是不能并行的。
是不是无锁化进行不下去了呢?经过我们观察发现两个接口的请求量如下图:
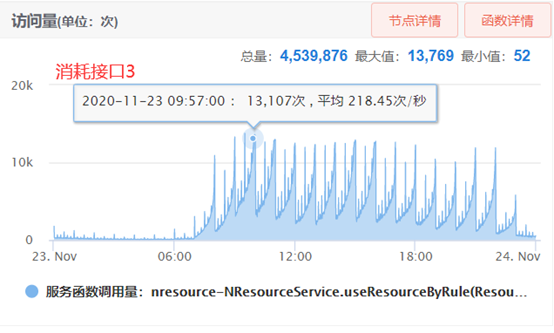
图2-1 资源消耗接口流量监控

图2-2 资源转移接口流量监控
这两个接口的热度相差3个数量级。他们之间的依赖关系是转移时不允许消耗。
基于前面的分析我们设计了如下的方案:
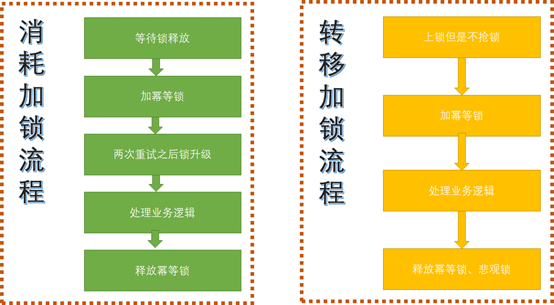
图2-3 乐观锁方案
转移的时候上锁,但是不等待锁;消耗的时候仅仅依赖相同用户来的转移的锁,其他的场景为乐观锁。
我们还有一个机制,乐观锁有冲突首先是重试,如果冲突较大我们升级为悲观锁。
最后我们对Redis锁做DB锁的兜底方案。那么问题来了,为什么不直接用DB锁呢?
为了最求更优体验,每日千万级别的写,追求极致性能,99%场景可用,不能因为1%的不可用放弃这个方案,况且我们还有兜底方案,保证数据一致性。
下面是我们无锁化操作的使用方式:
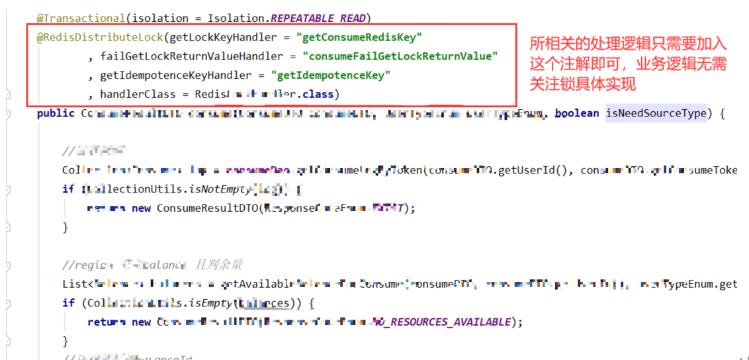
图2-4 乐观锁代码实现
只需要一个注解就可以使用复杂高效的分布式锁。通过这些手段,我们最终性能提升了接近10%。
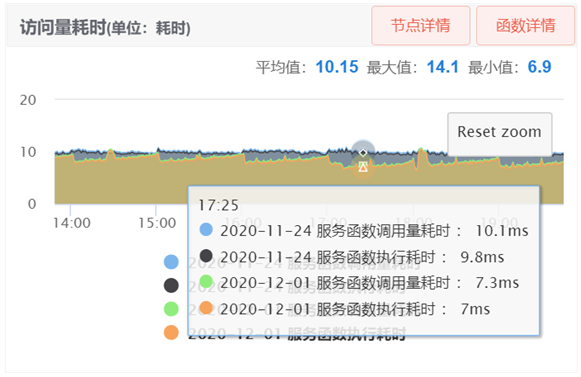
图2-5 资源消耗接口性能监控
2.3、接口优化
以批量接口为例,下面是我们部分批量接口的耗时情况:
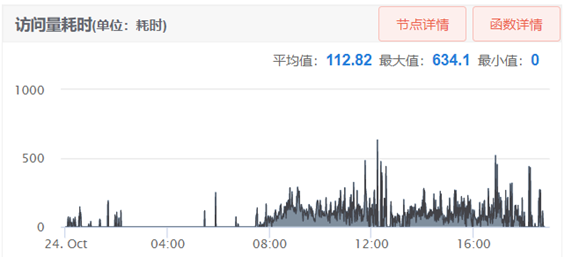
图2-6 资源批量消耗接口性能
从上图可以看到批量消耗平均耗时在100ms以上,有时候甚至超过500ms,这是在1分钟内的平均耗时,我看过请求日志有些甚至在1000ms以上。
我们的做法是:按照用户和资源维度进行拆分多线程消耗,每个线程内部的多个消耗合并成一次资源扣减,减少DB的交互。另外消耗流水在主接口之外的Event Bus中异步执行,不参与主接口的处理逻辑,整个接口性能平均提升了三倍。
总结
除了上述工作,这些我们做了预热,索引优化,所有连接池参数通用配置,SQL优化,代码逻辑优化,多线程并发处理,增大SCF(58RPC框架)工作线程数等一系列工作,我们采用从整体到局部全方位极致性能优化的思路进行强化。最终接平均口性能提升30%,超时量由2000优化到几十。效果如下图:
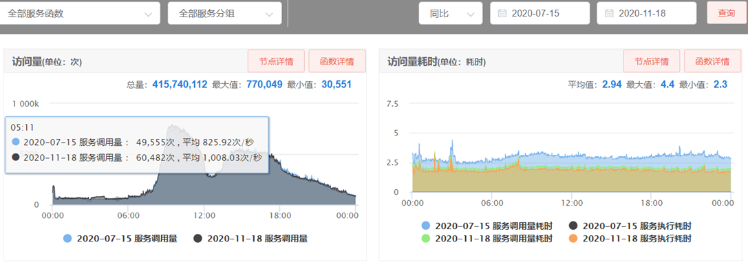
图3-1 资源中心系统监控
“治大国若烹小鲜”,在我们的服务治理上,除了基础设施,大的系统架构之外,在具体的实施细节上,是要精细的管理的。在性能调优上,也是1ms也不放过的极致追求。
--------------------------------------------------------------------------------------------------------------
参考链接:
https://www.jianshu.com/p/2a3d1842a0da
https://blog.csdn.net/andong154564667/article/details/80776956
https://blog.csdn.net/lizz861109/article/details/103581742
https://github.com/alibaba/Sentinel/wiki/Sentinel工作主流程
参考书籍:
李智慧——《大型网站技术架构核心原理与案例分析》
李运华——《从零开始学架构》