在深度学习中处理不均衡数据集
在深度学习中处理不均衡数据集
- 作者:George Seif 编译:ronghuaiyang,参考AI公园
1.过采样和欠采样
下面的图给出了一个大概的说明:
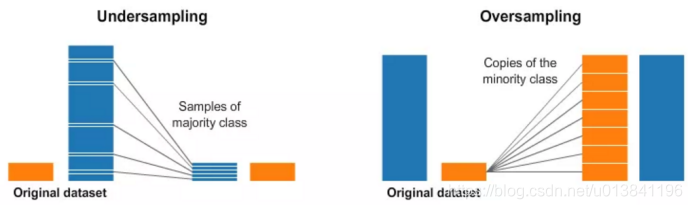
在图像的两边,蓝色的类别比橘黄色的类别的样本多得多。这种情况下,我们在预处理时,有两种选择。
欠采样 意思是从多数的类别中只采样其中的一部分的样本,选择和少数类别同样多的样本。这种采样保持了该类别原来的数据分布。这很容易,我们只需要少用点样本就可以让数据变得均衡。
过采样 的意思是我们复制少数类别中的样本,使得数量和多数样本一样多。复制操作需要保持少数样本的原有的数据分布。我们不需要获取更多的数据就可以让数据集变得均衡。采样的方法是一个很好的类别均衡的方法。
注:一定要保持采样后的数据分布和原有数据分布类似。
data argumentation:
基本数据增强主要包含如下方式:
1.旋转: 可通过在原图上先放大图像,然后剪切图像得到。
2.平移:先放大图像,然后水平或垂直偏移位置剪切
3.缩放:缩放图像
4.随机遮挡:对图像进行小区域遮挡
5.水平翻转:以过图像中心的竖直轴为对称轴,将左、右两边像素交换
6.颜色色差(饱和度、亮度、对比度、 锐度等)
7.噪声扰动: 对图像的每个像素RGB进行随机扰动, 常用的噪声模式是椒盐噪声和高斯噪声;
2.权值均衡(损失敏感函数)
权值均衡是在训练样本的时候,在计算loss的时候,通过权值来均衡数据的分布。正常情况下,每个类别在损失函数中的权值是1.0。但是有时候,当某些类别特别重要的时候,我们需要给该类别的训练样本更大权值。
可以直接给对应的类别的样本的loss乘上一个因子来设定权值。在Keras中,我们可以这样:
import keras class_weight = {"buy": 0.75, "don't buy": 0.25} model.fit(X_train, Y_train, epochs=10, batch_size=32, class_weight=class_weight)
我们创建了一个字典,其中,“买”类别为75%,表示了占据了75%的loss,因为比“不买”的类别更加的重要,“不买”的类别设置成了25%。当然,这两个数字可以修改,直到找到最佳的设置为止。我们可以使用这种方法来均衡不同的类别,当类别之间的样本数量差别很大的时候。我们可以使用权值均衡的方式来使我们的所有的类别对loss的贡献是相同的,而不用取费力的收集少数类别的样本了。
另一个可以用来做训练样本的权值均衡的是Focal loss。如下所示,主要思想是这样:在数据集中,很自然的有些样本是很容易分类的,而有些是比较难分类的。在训练过程中,这些容易分类的样本的准确率可以达到99%,而那些难分类的样本的准确率则很差。问题就在于,那些容易分类的样本仍然在贡献着loss,那我们为什么要给所有的样本同样的权值?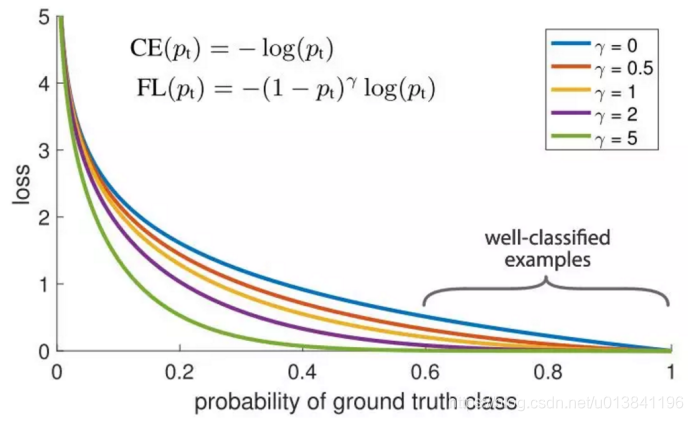
这正是Focal loss要解决的问题。focal loss减小了正确分类的样本的权值,而不是给所有的样本同样的权值。这和给与训练样本更多的难分类样本时一样的效果。在实际中,当我们有数据不均衡的情况时,我们的多数的类别很快的会训练的很好,分类准确率很高,因为我们有更多的数据。但是,为了确保我们在少数类别上也能有很好的准确率,我们使用focal loss,给与少数类别的样本更高的权值。focal loss使用Keras是很容易实现的:
import keras from keras import backend as K import tensorflow as tf # Define our custom loss function def focal_loss(y_true, y_pred): gamma = 2.0, alpha = 0.25 pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred)) pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred)) return -K.sum(alpha * K.pow(1. - pt_1, gamma) * K.log(pt_1))-K.sum((1-alpha) *K.pow( pt_0, gamma) * K.log(1. - pt_0)) # Compile our model adam = Adam(lr=0.0001) model.compile(loss=[focal_loss], metrics=["accuracy"], optimizer=adam)
3.提升识别性能的方法:
1: Data argumentation
2: Transfer learning
3: Model fusion
4: The style relationship