一、Spider 用法
在 Scrapy 中,要抓取网站的链接配置、抓取逻辑、解析逻辑都是在 Spider 里完成的。Spider 的一些基础属性和基础方法:
- name:爬虫名字,Spider的名字定义了 Scrapy 是如何定位并初始化 Spider的,必须是唯一的。例如爬取 mywebsite.com,那么该 Spider通常被命名为 mywebsite。
- allowed_domains:允许爬取的域名,不在在范围的链接不会被根据爬取。
- start_urls:它是起始 URL 列表,当我们没有实现 start_requets() 方法时,默认从这个列表开始抓取。
- custom_settings:它是一个字典,是专属与本 Spider 的配置,此设置会覆盖项目全局的设置。此设置必须在初始化前被更新,必须定义成类变量。
- crawler:它是由from_crawler()方法设置的,代表的是本 Spider 对应的 Crawler 对象,Crawler对象包含了许多项目组件,利用它我们可以获取项目的一些配置。如获取Settings。
- settings:它是一个 Settings 对象,利用它我们可以直接获取项目的全局设置变量。
- start_requets():此方法用于生成初始请求,它必须返回一个可迭代的对象。此方法默认使用 start_urls 里面的url来构造 Request,而且默认请求方式是 Get,若想要用 POST请求,可以重写这个方法,并使用 FormRequest。
- parse():当Response 没有指定回调函数是,该方法被默认调用。
- closed():当 Spider 关闭时,该方法被调用,一般用来释放一些资源或其他收尾操作。
二、Downloader Middleware 用法
下载中间件,位于Scrapy 的 Request 和 Response之间的处理模块。其在整个架构中起作用的位置有以下两个:
- 在
Scheduler调度出队列的 Request发送给 Downloader 下载之前,即可以在Request下载前对其修改。 - 在下载后生成的 Response 发送给 Spider之前,即可以在生成的Response被Spider解析前修改它。
所以,Downloader Middleware 可以用来修改 User-Agent、处理重定向、设置代理、失败重试、设置Cookies等。Scrapy 已经为我们提供了许多的 Downloader Middleware,如负责失败重试、重定向的中间件,这些下载中间件被 DOWNLOADER_MIDDLEWARES_BASE 变量所定义,这个变量是一个字典,如下所示:

这个字典的键名是下载中间件的名称,键值代表优先级,越小越靠近Scrapy Engine,越大越靠近Downloader,
所以越小越先被调用。若我们想将我们自定义的下载中间件加入到项目中,我们可以修改 DOWNLOADER_MIDDLEWARES 变量。
- 核心方法
- process_request(request, spider):Request被下载之前调用。
- process_response(request, response, spider):Response被Spider解析之前调用。
- process_exception(request, exception, spider):当 Downloader 或 process_request()方法抛出异常时被调用。
Demo
-
新建一个项目:
scrapy startproject scrapydownloadertest -
新建一个 Spider
进入项目根路径,新建一个名为 httpbin 的 Spider:
scrapy genspider httpbin httpbin.org修改 httpbin.py 如下:
# -*- coding: utf-8 -*- import scrapy class HttpbinSpider(scrapy.Spider): name = 'httpbin' allowed_domains = ['httpbin.org'] # 修改成get方式的请求 start_urls = ['http://httpbin.org/get'] def parse(self, response): # 添加一个行日志,输出 response.text,为了观察Scrapy发送的Request信息 self.logger.debug(response.text)运行此 Spider:
scrapy crawl httpbin结果中包含以下 Scrapy 发送的Request信息:
2019-02-09 14:16:58 [httpbin] DEBUG: { "args": {}, "headers": { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding": "gzip,deflate,br", "Accept-Language": "en", "Connection": "close", "Host": "httpbin.org", "User-Agent": "Scrapy/1.5.0 (+https://scrapy.org)" },观察 user-Agent,这是Scrapy自动为我们设置的,那么怎么修改用户代理呢?
我们可以直接在
settings.py中添加USER_AGENT变量或者通过Downloader Middleware的process_request()方法来修改。前者的话很简单,在settings.py 添加内容如下:
USER_AGENT = Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36一般推荐使用此方法来设置,但是我们如果想要实现随机的 User-Agent,就需要自己实现一个下载中间件类了,在
middlewares.py里面添加一个RandomUseAgentMiddleware类:import random class RandomUseAgentMiddleware(): def __init__(self): self.user_agents = [ 'Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)', 'Mozilla/5.0 (Windows NT6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2', 'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/201000101 Firefox/15.0.1' ] def process_request(self, request, spider): # 设置成随机取一个代理 request.headers['User-Agent'] = random.choice(self.user_agents)要使自定义的
Downloader Middleware生效,就需要添加到DOWNLOADER_MIDDLEWARES变量中,所以在settings.py中取消DOWNLOADER_MIDDLEWARES注释,并设置成如下内容:DOWNLOADER_MIDDLEWARES = { 'scrapydownloadertest.middlewares.RandomUseAgentMiddleware': 543, }然后,重新运行 Spider,观察结果中的用户代理:
2019-02-09 14:52:56 [httpbin] DEBUG: { "args": {}, "headers": { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding": "gzip,deflate,br", "Accept-Language": "en", "Connection": "close", "Host": "httpbin.org", "User-Agent": "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)" },确实用户代理被成功地修改为随机列表中的一个。
三、Spider Middleware 用法
Spider Middleware 是介入到 Scrapy 的 Spider 处理机制的钩子框架。它的作用有:
- 可以在 Downloader生成的Response 发送给 Spider 之前对 Response进行处理。
- 可以在Spider 生成的 Request 发送给 Scheduler 对 Request 进行处理。
- 可以在 Spider生成的 Item 发送给 Item Pipeline 之前对 Item进行处理。
Spider Middleware 的使用频率不如 Downloader Middleware 高,在这里省略相关介绍。
四、Item Pipeline 用法
Item Pipeline 是项目管道,主要功能有以下 4 点:
- 清理 HTML 数据。
- 验证爬取数据,检查爬取字段。
- 查重并丢弃重复结果。
- 将爬取结果保存到数据库中。
核心方法
- process_item(item, spider):必须实现的方法,被定义的 Item Pipeline 会默认调用这个方法对 Item 进行处理。如,数据处理或插入数据到数据库中。它必须返回 Item 类型或者 抛出一个 DropItem 异常。如果它返回的是 Item 类型,那么会将此 Item交给其他低优先级的 process_item 处理,直到所有的方法被调用完毕;如果它抛出了 DropItem 异常,那么此 Item 会被丢弃不再处理。
- open_spider(self, spider):此方法在 Spider 开启的时候自动调用。我们可以在这里做一些初始化操作,如开启数据库连接等。
- close_spider(self, spide):此方法在 Spider 关闭的时候自动调用。我们可以在这里做一些收尾的工作,若关闭数据库连接等。
- from_crawler(cls, crawler):此方法是一个类方法,用@classmethod标识,是一种依赖注入的方式。通过
crawler对象,我们可以拿到Scrapy的所有核心组件,如全局配置的每个信息,然后创建一个 Pipeline 实例。参数 cls 就是 Class,最后返回一个 Class 实例。
Demo
目标:以爬取 360 摄影美图(https://image.so.com)为例,来分别实现 MongoDB、MySQL、Image图片存储的三个 Pipeline。分析网页的结构,观察图片是怎么来的。
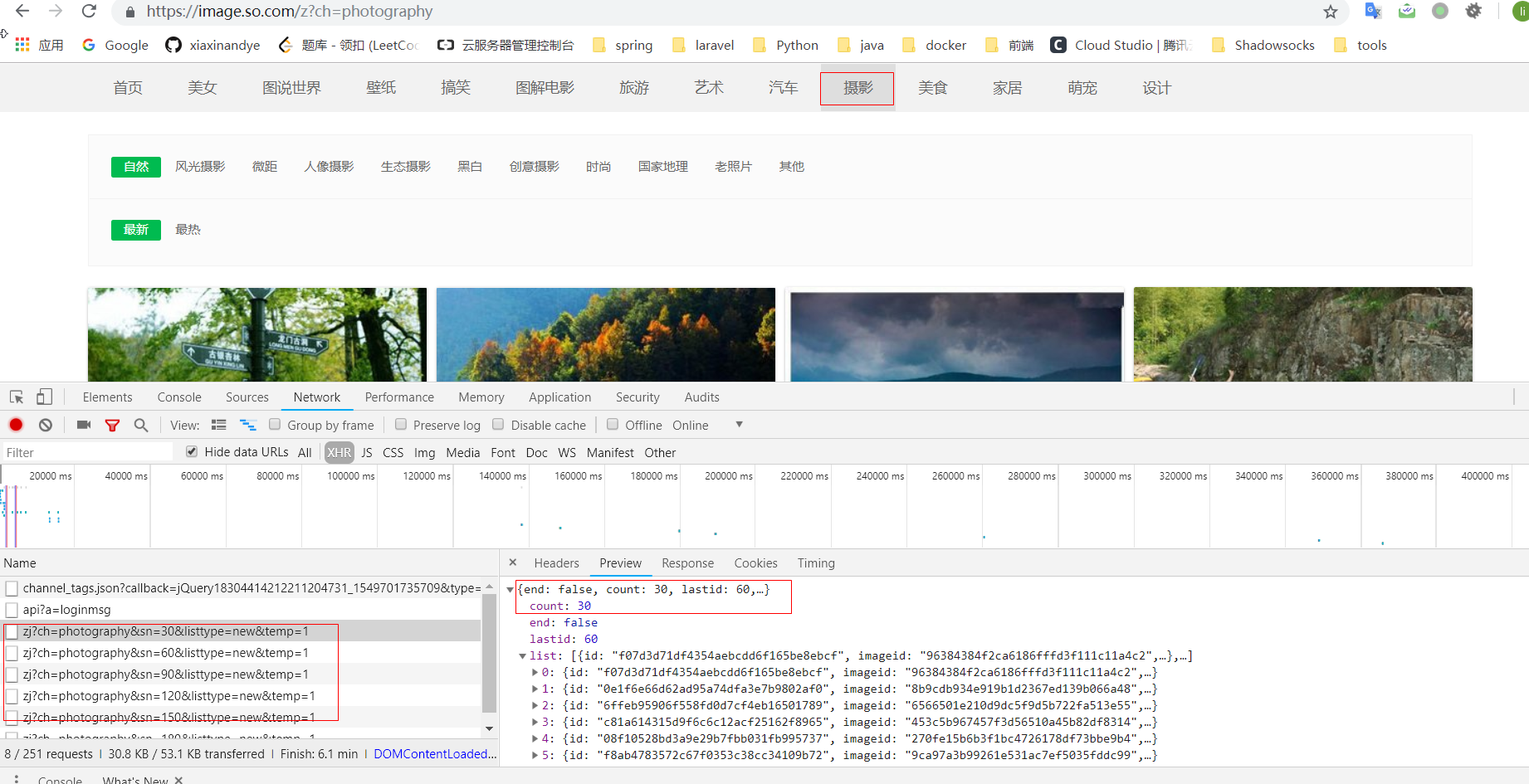
结论:最开始默认返回 30 张图片,然后当我们鼠标继续向下移动时,会发送 ajax 请求,从返回的 json里面包含了图片的链接,并且也是 30 张图片,唯一变的参数就是 sn,当 sn =30时,返回的是31 - 60号的图片,依次类推。而且测试后发现当 sn = 0 时,返回的是 1-30 号的图片。
-
新建Scrapy项目 images360
scrapy startproject images360 -
新建 Spider
cd images360 scrapy genspider images images.so.com -
构造请求
定义爬取的页数为 50,在 settings.py 中定义:
MAX_PAGE = 50在 Spider中定义 start_requests() 方法,用来生成 50 次 请求:
# -*- coding: utf-8 -*- import scrapy from urllib.parse import urlencode from scrapy import Spider, Request class ImagesSpider(scrapy.Spider): name = 'images' allowed_domains = ['images.so.com'] start_urls = ['http://images.so.com/'] def parse(self, response): pass def start_requests(self): data = {'ch': 'photography', 'listtype': 'new', 'temp': '1'} base_url = 'https://image.so.com/zj?' for page in range(1, self.settings.get('MAX_PAGE') + 1): data['sn'] = (page - 1) * 30 # 字典用 urlencode编码成请求参数 params = urlencode(data) url = base_url + params yield Request(url=url, callback=self.parse)在 Settings.py 中,修改 ROBOTSTXT_OBEY 变量,不遵守该网站的 robots.txt
# Obey robots.txt rules ROBOTSTXT_OBEY = False运行 Spider 得到如下结果:
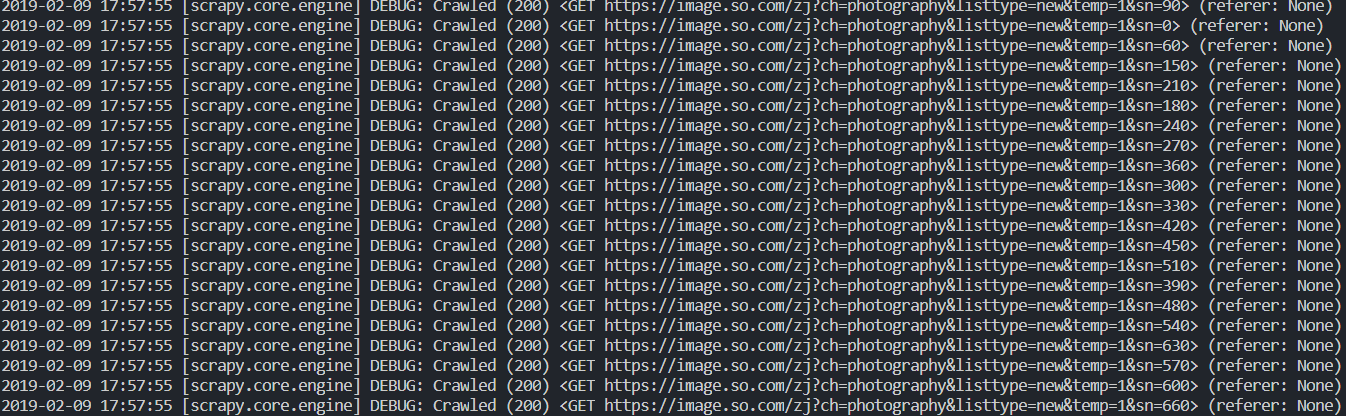
-
提取信息
首先定义一个 Item 类用于存放 image:
items.py
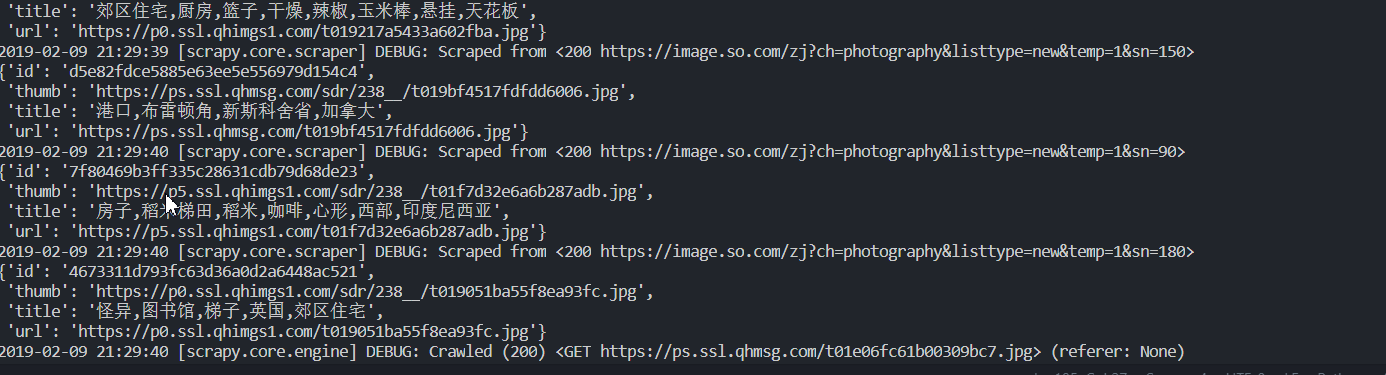
from scrapy import Item, Field class ImageItem(Item): collection = table = 'imgaes' id = Field() url = Field() title = Field() thumb = Field()改写 Spider:
def parse(self, response): result = json.loads(response.text) for image in result.get('list'): item = ImageItem() item['id'] = image.get('imageid') item['url'] = image.get('qhimg_url') item['title'] = image.get('group_title') item['thumb'] -
存储数据
-
MongoDB
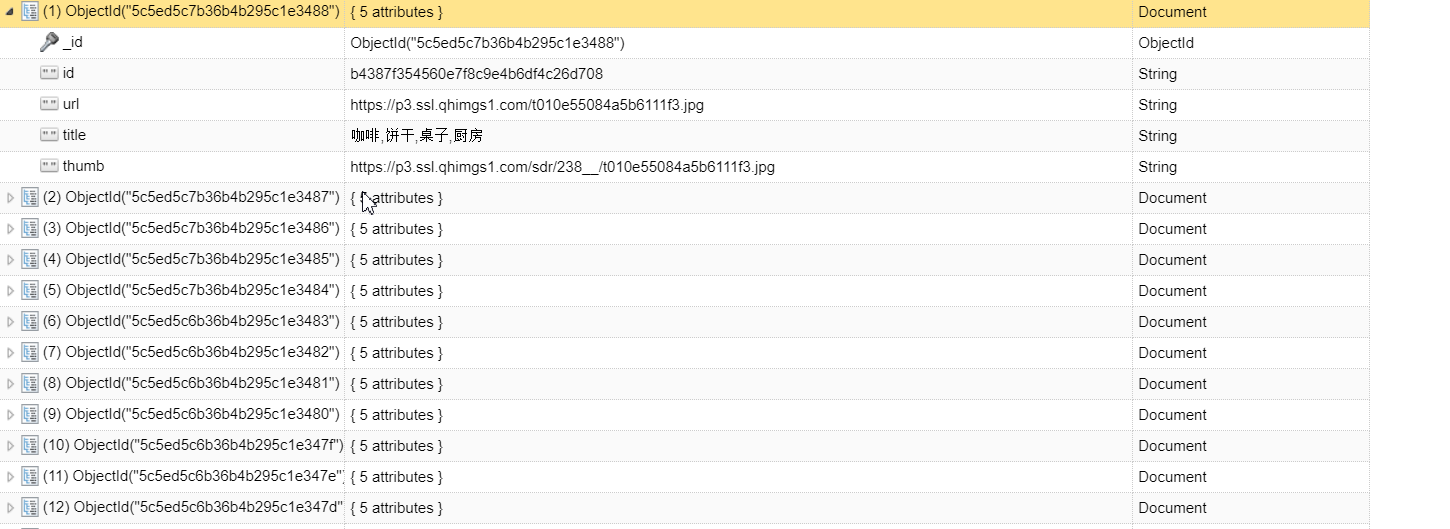
编写一个 MongoPipeline 将数据保存到 MongoDB 中,在 pipelines.py 中添加如下类的实现:
import pymongo class MongoPipeline(object): def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri = crawler.settings.get('MONGO_URI'), mongo_db = crawler.settings.get('MONGO_DB') ) def open_spider(self,spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def process_item(self, item, spider): self.db[item.collection].insert(dict(item)) return item def close_spider(self, spider): self.client.close()在 settings.py 中添加以下两个变量:
MONGO_URI = 'localhost' MONGO_DB = 'images360' -
MySQL
首先创建数据库 images360,SQL语句:
CREATE DATABASE images360 DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci新建一张表,包含id、url、title、thumb 四个字段,SQL语句:
CREATE TABLE images( id VARCHAR(255) PRIMARY KEY, url VARCHAR(255) NULL, title VARCHAR(255) NULL, thumb VARCHAR(255) NULL )实现 MySQLPipeline:
import pymysql class MysqlPipeline(): def __init__(self, host, database, user, password, port): self.host = host self.database = database self.user = user self.password = password self.port = port @classmethod def from_crawler(cls, crawler): return cls( host = crawler.settings.get('MYSQL_HOST'), database = crawler.settings.get('MYSQL_DATABASE'), user = crawler.settings.get('MYSQL_USER'), password = crawler.settings.get('MYSQL_PASSWORD'), port = crawler.settings.get('MYSQL_PORT') ) def open_spider(self, spider): self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8', port=self.port) self.cursor = self.db.cursor() def close_spider(self, spider): self.db.close() def process_item(self, item, spider): data = dict(item) keys = ', '.join(data.keys()) values = ', '.join(['%s'] * len(data)) sql = 'insert into %s (%s) values(%s)' % (item.table, keys, values) self.cursor.execute(sql,tuple(data.values())) self.db.commit() return item添加几项设置在 settings.py 中:
MYSQL_HOST = 'localhost' MYSQL_DATABASE = 'images360' MYSQL_USER = 'root' MYSQL_PASSWORD = '123456' MYSQL_PORT = 3306 -
Image Pipeline
Scrapy 提供了专门处理下载的 Pipeline,包括文件下载和图片下载,下载过程同样支持异步和多线程,效率十分高效。
首先要定义存储文件的路径,在 settings.py 中加入以下代码:
IMAGES_STORE = './images'内置的 ImagesPipeline 不符合我们的需求,我们要自己定义 ImagePipeline 继承 ImagesPipeline :
from scrapy import Request from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline class ImagePipeline(ImagesPipeline): def file_path(self, request, response=None, info=None): url = request.url file_name = url.split('/')[-1] # 最后一部分作为文件名 return file_name def item_completed(self, results, item, info): images_paths = [x['path'] for ok, x in results if ok] if not images_paths: raise DropItem('Image Download Failed') return item def get_media_requests(self, item, info): yield Request(item['url'])
启用我们定义的三个 Pipeline,修改settings.py, 设置
ITEM_PIPELINES: -
ITEM_PIPELINES = {
'images360.pipelines.ImagePipeline': 300,
'images360.pipelines.MongoPipeline': 301,
'images360.pipelines.MysqlPipeline': 302,
}
注意下调用顺序,首先调用 ImagePipeline 对 Item 做下载后的筛选下载失败的就不需要进行保存到数据库中了。
最后执行程序,爬取。
scrapy crawl images

五、参考数据
崔庆才.《Python3 网络爬虫开发实战》