说到阿里巴巴大数据,不得不提到的是10年前王坚博士率领建构的飞天大数据平台,十年磨一剑,今天飞天大数据平台已是阿里巴巴10年大平台建设最佳实践的结晶,是阿里大数据生产的基石。飞天大数据平台在阿里巴巴集团内每天有数万名数据和算法开发工程师在使用,承载了阿里99%的数据业务构建。同时也已经广泛应用于城市大脑、数字政府、电力、金融、新零售、智能制造、智慧农业等各领域的大数据建设。

在2015年的时候,我们开始关注到数据的海量增长对系统带来了越来越高的要求,随着深度学习的需求增长,数据和数据对应的处理能力是制约人工智能发展的关键问题,我们在给客户聊到一个摆在每个CIO/CTO面前的现实问题——如果数据增长10倍,应该怎么办?图中数字大家看得非常清晰,非常简单的拍立淘系统背后是PB的数据在做支撑,阿里小蜜客服系统有20个PB,大家每天在淘宝上日常使用的个性化推荐系统,后台要超过100个PB的数据来支撑后台的决策,10倍到100倍的数据增长是非常常见的。从这个角度上来讲,10倍的数据增长通常意味着什么问题? 第一,意味着10倍成本的增长,如果考虑到增长不是均匀的,会有波峰和波谷,可能需要30倍弹性要求;第二,实际上因为人工智能的兴起,二维结构性的关系型数据持续性增长的同时,带来的是非结构化数据,这种持续的数据增长里面,一半的增长来自于这种非结构化数据,我们除了能够处理好这种二维的数据化之后,我们如何来做好多种数据融合的计算?第三,阿里有一个庞大的中台团队,如果说我们的数据增长了10倍,我们的团队是不是增长了10倍?如果说数据增长了10倍,数据的关系复杂度也超过了10倍,那么人工的成本是不是也超过了10倍以上,我们的飞天平台在2015年后就是围绕这三个关键性的问题来做工作的。
原创技术优化 + 系统融合
当阿里巴巴的大数据走过10万台规模的时候,我们已经走入到技术的无人区,这样的挑战绝大多数公司不一定能遇到,但是对于阿里巴巴这样的体量来讲,这个挑战是一直摆在我们面前的。
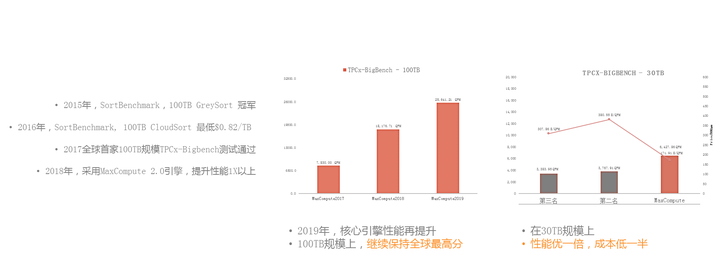
大家可以看到,2015年的时候,我们整个的体系建立起来之后,就开始做各种各样的Benchmark,比如2015年100TB的Sorting,2016年我们做CloudSort,去看性价比,2017年我们选择了Bigbench。如图是我们最新发布的数据,在2017、2018和2019年,每年都有一倍的性能提升,同时我们在30TB的规模上比第二名的产品有一倍的性能增长,并且有一半的成本节省,这是我们的计算力持续上升的优化趋势。
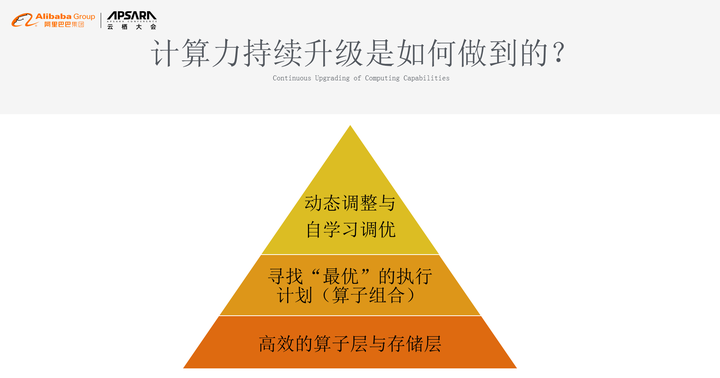
那么,计算力持续升级是如何做到的?如图是我们经常用到的系统升级的三角理论,最底层的计算模型是高效的算子层和存储层,这是非常底层的基础优化,往上面要找到最优的执行计划,也就是算子组合,再往上是新的方向,即怎么做到动态调整与自学习的调优。
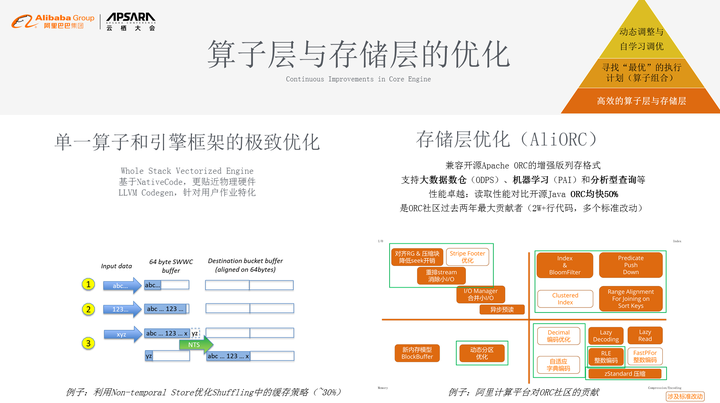
我们先来看单一算子和引擎框架的极致优化,我们用的是比较难写难维护的框架,但是因为它比较贴近物理硬件,所以带来了更极致的性能追求。对于很多系统来说可能5%的性能提升并不关键,但对于飞天技术平台来讲,5%的性能提升就是5千台的规模,大概就是2~3亿的成本。如图做了一个简单的小例子做单一算子的极致优化,在shuffle子场景中,利用Non-temporal Store优化shuffling中的缓存策略,在这样的策略上有30%的性能提升。 除了计算模块,它还有存储模块,存储分为4个象限。一四象限是存储数据本身的压缩能力,数据增长最直接的成本就是存储成本的上升,我们怎么做更好的压缩和编码以及indexing?这是一四象限做的相关工作;二三象限是在性能节省上做的相关工作,我们存储层其实是基于开源ORC的标准,我们在上面做了非常多的改进和优化,其中白框里面都有非常多的标准改动,我们读取性能对比开源Java ORC 均快 50%,我们是ORC社区过去两年最大贡献者,贡献了2W+行代码,这是我们在算子层和存储层的优化,这是最底层的架构。

但是从另外一个层面上来讲,单一的算子和部分的算子组合很难满足部分的场景需求,所以我们就提到灵活的算子组合。举几个数字,我们在Join上有4种模式,有3种Shuffling模式提供,有3种作业运行模式,有多种硬件支持和多种存储介质支持。图右是怎样去动态判别Join模式,使得运算效率更高。通过这种动态的算子组合,是我们优化的第二个维度。
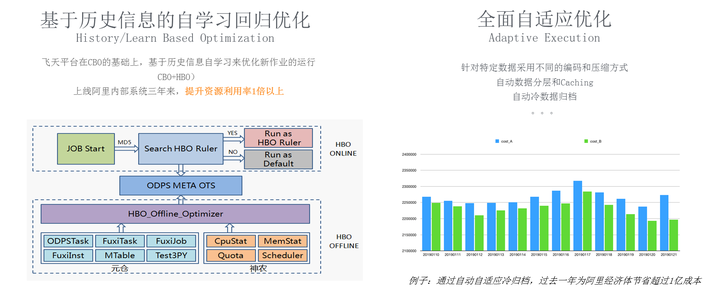
从引擎优化到自学习调优是我们在最近1年多的时间里花精力比较多的,我们在考虑如何用人工智能及自学习技术来做大数据系统,大家可以想象学骑自行车,刚开始骑得不好,速度比较慢甚至有的时候会摔倒,通过慢慢的学习,人的能力会越来越好。对于一个系统而言,我们是否可以用同样的方式来做?当一个全新的作业提交到这个系统时,系统对作业的优化是比较保守的,比如稍微多给一点资源,那么我选择的执行计划会相对比较保守一点,使得至少能够跑过去,当跑过之后就能够搜集到信息和经验,通过这些经验再反哺去优化数据,所以我们提出一个基于历史信息的自学习回归优化,底层是如图的架构图,我们把历史信息放在OFFLINE system去做各种各样的统计分析,当作业来了之后我们把这些信息反哺到系统之中去,让系统进行自学习。通常情况下,一个相似的作业大概跑了3到4次的时候,进入到一个相对比较优的过程,优指的是作业运行时间和系统资源节省。这套系统大概在阿里内部3年前上线的,我们通过这样的系统把阿里的水位线从40%提升到70%以上。 另外图中右侧也是一个自学习的例子,我们怎么区分热数据和冷数据,之前可以让用户自己去set,可以用一个普通的configuration去配置,后来发现我们采用动态的根据作业方式来做,效果会更好,这个技术是去年上线的,去年为阿里节约了1亿+人民币。从以上几个例子上来讲引擎层面和存储层面做的极致性能优化,性能优化又带来了用户成本的降低,在2019年9月1号,飞天大数据平台的整体存储成本降低了30%,同时我们发布了基于原生计算的新规格,可以实现最高70%的成本节省。 以上都是在引擎层面的优化,随着AI的普惠优化,AI的开发人员会越来越多,甚至很多人都不太具备代码的能力,阿里内部有10万名员工,每天有超过1万个员工在飞天大数据平台上做开发,从这个角度上来讲,不仅系统的优化是重要的,平台和开发平台的优化也是非常关键的。
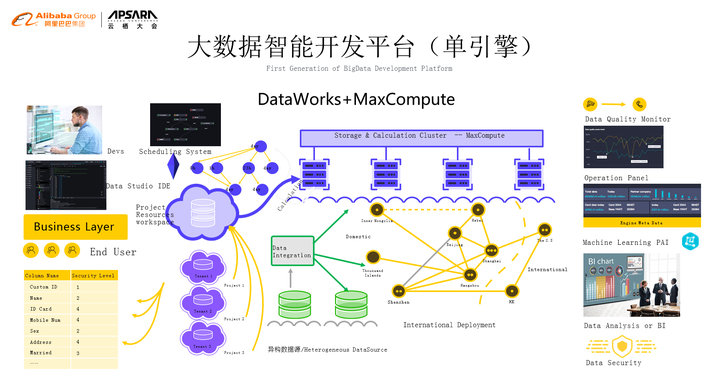
计算引擎对大家来说看不见摸不着,我们要去用它肯定希望用最简单的方式,先来看一下Maxcompute计算引擎。首先我们需要有用户,用户怎么来使用?需要资源隔离,也就是说每个用户在系统上面使用的时候会对应着账号,账号会对应着权限,这样就把整套东西串联起来。今天我的用户怎么用?用哪些部分?这是第一部分。第二部分是开发,开发有IDE,IDE用来写代码,写完代码之后提交,提交之后存在一个调度的问题,这么多的资源任务顺序是什么?谁先谁后,出了问题要不要中断,这些都由调度系统来管,我们的这些任务就有可能在不同的地方来运行,可以通过数据集成把它拉到不同的区域,让这些数据能够在整个的平台上跑起来,我们所有的任务跑起来之后我们需要有一个监控,同时我们的operation也需要自动化、运维化,再往下我们会进行数据的分析或者BI报表之类的,我们也不能够忘记machine learning也是在我们的平台上集成起来的。最后,最重要的就是数据安全,这一块整个东西构起一个大数据引擎的外沿+大数据引擎本身,这一套我们称之为单引擎的完备大数据系统,这一套系统我们在2017年的时候就具备了。

2018年的时候我们做什么?2018年我们在单引擎的基础上对接到多引擎,我们整个开发链路要让它闭环化,数据集成可以把数据在不同的数据源之间进行拖动,我们把数据开发完之后,传统的方式是再用数据引擎把它拖走,而我们做的事情是希望这个数据是云上的服务,这个服务能够直接对用户提供想要的数据,而不需要把数据整个拖走,因为数据在传输过程中有存储的消耗、网络的消耗和一致性消耗,所有的这些东西都在消耗用户的成本,我们希望通过数据服务让用户拿到他想要的东西。再往下,如果数据服务之上还有自定义的应用,用户还需要去建一个机房,搭一个web服务,然后把数据拿过来,这样也很麻烦,所以我们提供一个托管的web应用的云上开发平台,能够让用户直接看到所有的数据服务,在这个方向上来说,我们就可以构建任意的数据智能解决方案。
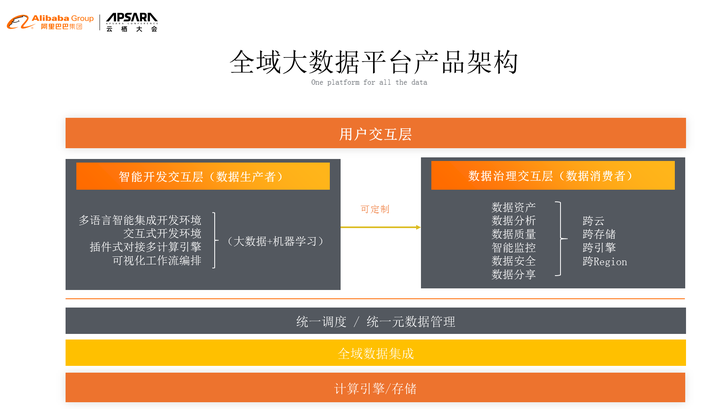
到2019年,我们会把理念再拓展一层,首先对于用户来说是用户交互层,但是用户的交互层不仅仅是开发,所以我们会把用户分成两类,一部分叫做数据的生产者,也就是写任务、写调度、运维等,这些是数据的生产者,数据的生产者做好的东西给谁呢?给数据的消费者,我们的数据分散在各个地方,所有的东西都会在治理的交互层对数据的消费者提供服务,这样我们就在一个新的角度来诠释飞天大数据平台。除了引擎存储以外,我们有全域的数据集成进行拉动,统一的调度可以在不同的引擎之间来切换协同工作,同时我们有统一的元数据管理,在这之上我们对数据的生产者和数据的消费者也都进行了相应的支持,那么这个整体就是全域的大数据平台产品架构。
云原生平台到全域云数仓
我们整个平台都是云原生的,云原生有哪些技术呢?
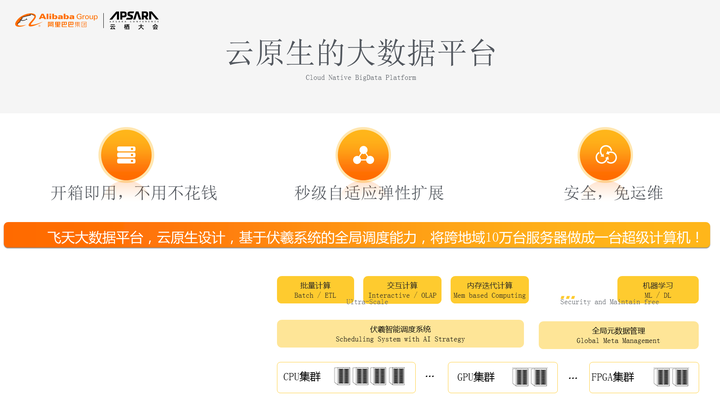
飞天大数据平台在10年前就坚持云原生的数据,云原生意味着三件事情,第一开箱即用、不用不花钱,这个和传统的买硬件方式有非常大的不同;第二我们具备了秒级自适应的弹性扩展,用多少买多少;第三因为是云上的框架,我们很多运维和安全的东西由云自动来完成了,所以是安全免运维的。从系统架构上讲,飞天大数据包括传统的CPU、GPU集群,以及平头哥芯片集群,再往上是我们的伏羲智能调度系统和元数据系统,再往上我们提供了多种计算能力,我们最重要的目标就是通过云原生设计把10万台在物理上分布在不同地域的服务器让用户觉得像一台计算机。我们今天已经达到了10年前的设计要求,具备了更强的服务扩展能力,能够支撑5到10年的数据进步的发展。 我们充分利用云原生设计的理念,支持大数据和机器学习的快速大规模弹性负载需求。我们支撑0~100倍的弹性扩容能力,去年开始,双十一60%的数据处理量来自于大数据平台的处理能力,当双11巅峰来的时候,我们把大数据的资源弹回来让给在线系统去处理问题。从另外一个角度来讲,我们具备弹性能力,相比物理的IDC模式,我们有80%成本的节省,按作业的计费模式,我们提供秒级弹性伸缩的同时,不使用不收费。相比自建IDC,综合成本只有1/5。除了坚持原生之外,我们最近发现,随着人工智能的发展,语音视图的数据越来越多了,处理的能力就要加强,我们要从二维的大数据平台变成全域的数据平台。
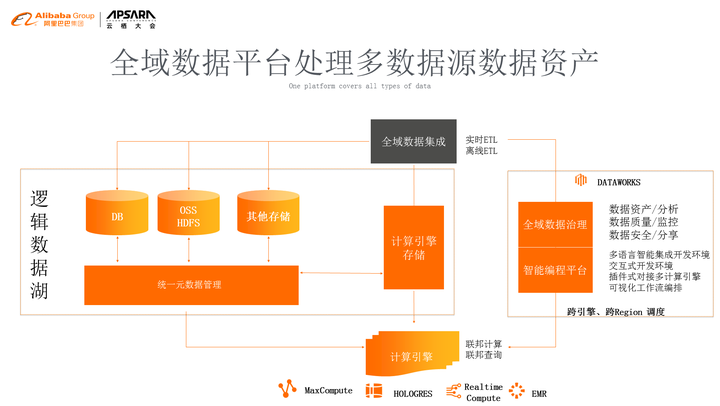
如图所示,业界有一个比较火的概念叫数据湖,我们要把客户多种多样的数据拿到一起来进行统一的查询和管理。但是对于真正的企业级服务实践,我们看到一些问题,首先数据的来源对于客户来说是不可控的,也是多种多样的,而且很大程度上没有办法把所有的数据统一用一种系统和引擎来管理起来,在这种情况下我们需要更大的能力是什么呢?我们今天通过不同的数据源,可以进行统一的计算和统一的查询和分析,统一的管理,所以我们提出一个更新的概念叫逻辑数据湖,对于用户来说,不需要把他的数据进行物理上的搬迁,但是我们一样能够进行联邦计算和查询,这就是我们讲的逻辑数据湖的核心理念。 为了支撑这件事情,我们会有统一的元数据管理系统和调度系统,能够让不同的计算引擎协同起来工作,最后把所有的工作汇聚到全域数据治理上面,并且提供给数据开发者一个编程平台,让他能够直接的产生数据,或者是去定制自己的应用。那么,通过这样的方式,我们把原来的单维度大数据平台去做大数据处理,拓展到一个全域的数据治理,这个数据其实可以包含简单的大数据的,也可以包含数据库的,甚至是一些OSS的file,这些我们在整个的平台里面都会加以处理。
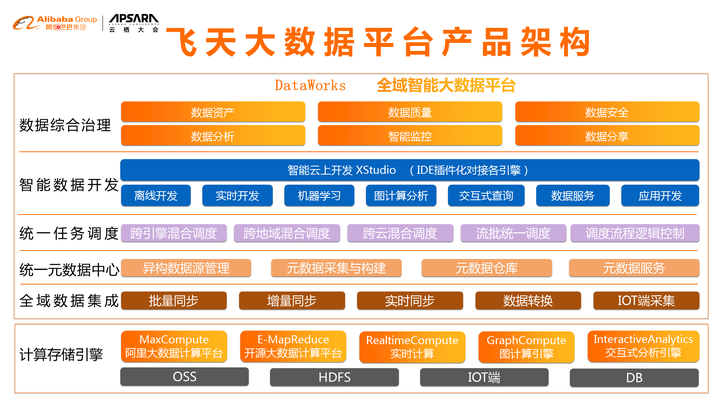
如图为飞天大数据的产品架构,下面是存储计算引擎,可以看到我们除了计算引擎自带的存储之外还有其它开放的OSS,还有IOT端采集的数据和数据库的数据,所有数据进行全域数据集成,集成后进行统一的元数据管理,统一的混合任务调度,再往上是开发层和数据综合治理层,通过这种方式,我们立体化的把整个大数据圈起来管理。
大数据与AI 双生系统
提到了大数据我们肯定会想到AI,AI和大数据是双生的,对于AI来说它是需要大数据来empower的,也就说bigdata for AI。下面可以通过一个demo来看我们怎么来做这件事情。对于AI的开发工程师来说,他们比较常用的方式是用交互式的notebook来进行AI的开发,因为它比较直观,但是如何把大数据也进行交互式开发,并且和AI来绑定,下面来看一下这个简单的例子。
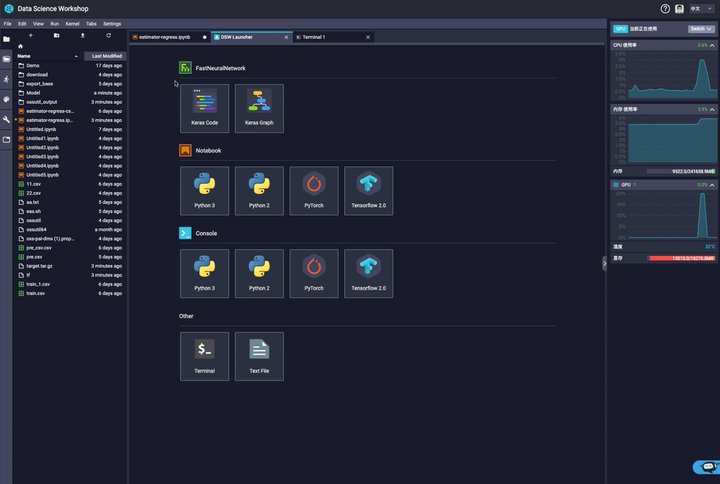
如图是我们DSW的平台,我们可以直接的用一个magic命令,connect到现存的maxcompute集群,并且选择project后,可以直接输入sql语句,这些都是智能的。然后我们去执行,结果出来之后我们可以对feature进行相应的分析,包括可以去改变这些feature的横纵坐标做出不同的charts,同时我们甚至可以把生成的结果直接web到excel方式进行编辑和处理,处理完之后我们再把数据拉回来,也可以切换到GPU或者CPU进行深度学习和训练,训练完了之后,我们会把整个的代码变成一个模型,我们会把这个模型导入到一个相应的地方之后提供一个Web服务,这个服务也就是我们的在线推理服务。整套流程做完之后,甚至我们可以再接数据应用,可以在托管的WEB上构建,这就是大数据平台给AI提供数据和算力。

大数据和AI是双生系统,AI是一个工具层,可以优化所有的事情。我们希望飞天的大数据平台能够赋能给AI。我们在最开始的时候希望build一个可用的系统,能够面临双11的弹性负载仍然是可用的。通过这些年的努力,我们追求极致的性能,我们能够打破数据的增长和成本增长的线性关系,我们也希望它是一个智能的,我们希望更多的数据开发工程师来支持它,我们需要更复杂的人力投入来理解他,我们希望有更强的大数据来优化大数据系统。

我们提出一个概念叫Auto Data Warehouse,我们希望通过智能化的方式把大数据做得更聪明。整体上可以分成3个阶段:
-
第一阶段是计算层面和效率层面,我们尝试寻找计算的第一层原理,我们去找百万到千万级别里面的哪些作业是相似的,因此可以合并,通过这种方式来节省成本,还有当你有千万级别的表之后,究竟哪些表建索引全局是最优的,以及我们怎么去做冷热的数据分层和做自适应编码。
-
第二阶段是资源规划,AI和Auto Data Warehouse可以帮助我们做更好的资源优化,包括我们有3种的执行作业模式,哪一种模式更好,是可以通过学习的方式学出来的,还有包括作业的运行预测和自动预报警,这套系统保证了大家看得到或者看不到的阿里关键作业的核心,比如每过一段时间大家会刷一下芝麻信用分,每天早上九点阿里的商户系统会和下游系统做结算,和央行做结算,这些基线是由千百个作业组成的一条线,从每天早上凌晨开始运行到早上八点跑完,系统因为各种各样的原因会出现各种的状况,可能个别的机器会宕机。我们做了一个自动预测系统,去预测这个系统是否能够在关键时间点上完成,如果不能够完成,会把更多的资源加进来,保证关键作业的完成。这些系统保证了我们大家日常看不见的关键数据的流转,以及双十一等重要的资源弹性。
-
第三阶段是智能建模,当数据进来之后和里面已有的数据究竟有多少的重叠?这些数据有多少的关联?当数据是几百张表时,搞DBA手工的方式可以调优的,现在阿里内部的系统有超过千万级别的表,我们有非常好的开发人员理解表里面完全的逻辑关系。这些自动调优和自动建模能够帮助我们在这些方面做一些辅助性的工作。
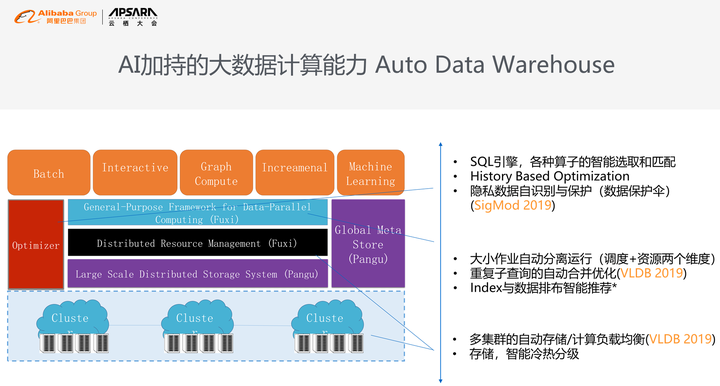
这是Auto Data Warehouse系统架构图,从多集群的负载均衡到自动冷存,到中间的隐形作业优化,再到上层的隐私数据自动识别,这是我们和蚂蚁一起开发的技术,当隐私的数据自动显示到屏幕上来,系统会自动检测并打码。我们其中的三项技术,包括自动隐私保护,包括重复子查询自动合并优化,包括多集群的自动容灾,我们有3篇paper发表,大家有兴趣的话可以去网站上读一下相关的论文。
本文为云栖社区原创内容,未经允许不得转载。