建模服务,在MaxCompute执行sql任务的时候有时候作业会很慢,本文通过查看logview排查具体任务慢的原因
在这里把任务跑的慢的问题划分为以下几类
- 资源不足导致的排队(一般是包年包月项目)
- 数据倾斜,数据膨胀
- 用户自身逻辑导致的运行效率低下
一、资源不足
一般的SQL任务会占用CPU、Memory这两个维度的资源,logview如何查看参考链接
1.1 查看作业耗时和执行的阶段

![]()
1.2 提交任务的等待
如果提交任务以后一直显示“Job Queueing...”则有可能是由于其他人的任务占用了资源组的资源,使得自己的任务在排队。
在SubStatusHistory中看Waiting for scheduling就是等待的时间

![]()
1.3 任务提交后的资源不足
这里还有另一种情况,虽然任务可以提交成功,但是由于所需的资源较大,当前的资源组不能同时启动所有的实例,导致出现了任务虽然有进度,但是执行并不快的情况。这种可以通过logview中的latency chart功能观察到。latency chart可以在detail中点击相应的task看到

![]()
上图显示的是一个资源充足的任务运行状态,可以看到蓝色部分的下端都是平齐的,表示几乎在同一时间启动了所有的实例。

![]()
而这个图形的下端呈现阶梯向上的形态,表示任务的实例是一点一点的调度起来的,运行任务时资源并不充足。如果任务的重要性较高,可以考虑增加资源,或者调高任务的优先级。
1.4资源不足的原因
1.通过cu管家查看cu是否占满,点到对应的任务点,找到对应时间看作业提交的情况

![]()
按cpu占比进行排序
(1)某个任务占用cu特别大,找到大任务看logview是什么原因造成(小文件过多、数据量确实需要这么多资源)。
(2)cu占比均匀说明是同时提交多个大任务把cu资源直接打满。

![]()
2.由于小文件过多导致cu占慢
map阶段的并行度是根据输入文件的分片大小,从而间接控制每个Map阶段下Worker的数量。默认是256m。如果是小文件会当作一个块读取如下图map阶段m1每个task的i/o bytes都只有1m或者几十kb,所以造成2500多个并行度瞬间把资源打满,说明该表下文件过多需要合并小文件

![]()
3.数据量大导致资源占满
可以增加购买资源,如果是临时作业可以加set odps.task.quota.preference.tag=payasyougo;参数,可以让指定作业临时跑到按量付费大资源池,
1.5任务并行度如何调节
MaxCompute的并行度会根据输入的数据和任务复杂度自动推测执行,一般不需要调节,理想情况并行度越大速度处理越快但是对于包年包月资源组可能会把资源组占满,导致任务都在等待资源这种情况会导致任务变慢
map阶段并行度
odps.stage.mapper.split.size :修改每个Map Worker的输入数据量,即输入文件的分片大小,从而间接控制每个Map阶段下Worker的数量。单位MB,默认值为256 MB
reduce的并行度
odps.stage.reducer.num :修改每个Reduce阶段的Worker数量
odps.stage.num:修改MaxCompute指定任务下所有Worker的并发数,优先级低于odps.stage.mapper.split.size、odps.stage.reducer.mem和odps.stage.joiner.num属性。
odps.stage.joiner.num:修改每个Join阶段的Worker数量。
二、数据倾斜
数据倾斜
【特征】task 中大多数 instance 都已经结束了,但是有某几个 instance 却迟迟不结束(长尾)。如下图中大多数(358个)instance 都结束了,但是还有 18 个的状态是 Running,这些 instance 运行的慢,可能是因为处理的数据多,也可能是这些instance 处理特定数据慢。

![]()
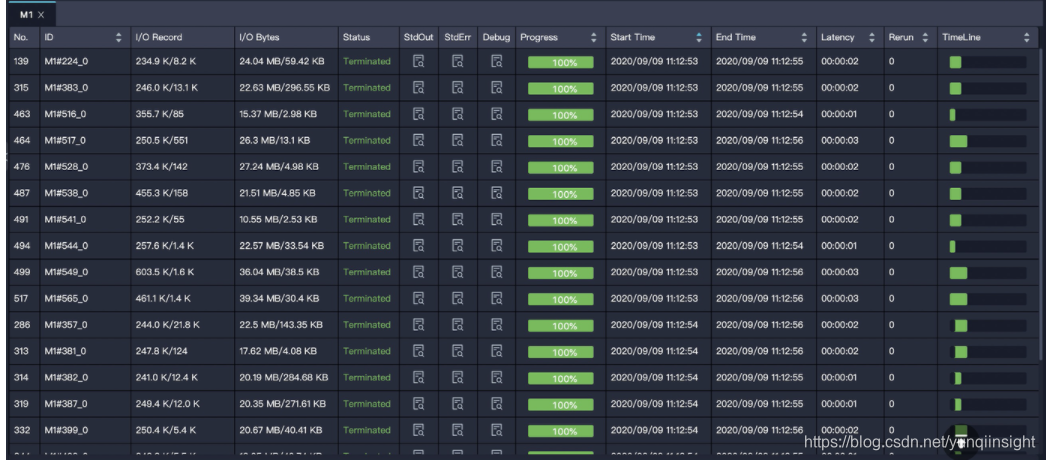
![]() 解决方法:https://help.aliyun.com/document_detail/102614.html?spm=a2c4g.11186623.6.1160.28c978569uyE9f
解决方法:https://help.aliyun.com/document_detail/102614.html?spm=a2c4g.11186623.6.1160.28c978569uyE9f
三、逻辑问题
这里指用户的SQL或者UDF逻辑低效,或者没有使用最优的参数设定。表现出来的现象时一个Task的运行时间很长,而且每个实例的运行时间也比较均匀。这里的情况更加多种多样,有些是确实逻辑复杂,有些则有较大的优化空间。
数据膨胀
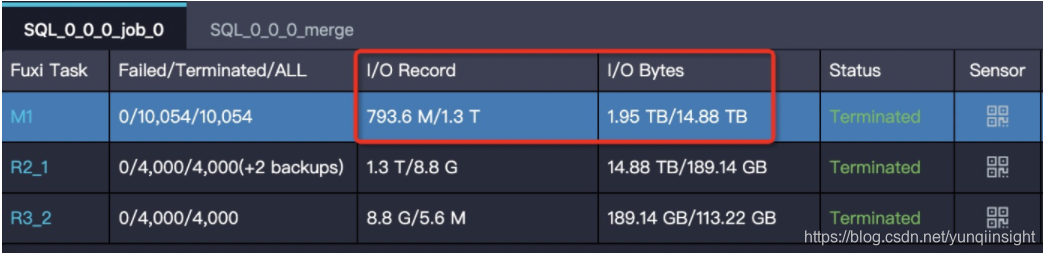
【特征】task 的输出数据量比输入数据量大很多。
比如 1G 的数据经过处理,变成了 1T,在一个 instance 下处理 1T 的数据,运行效率肯定会大大降低。输入输出数据量体现在 Task 的 I/O Record 和 I/O Bytes 这两项:
![]()
解决方法:确认业务逻辑确实需要这样,增大对应阶段并行度
UDF执行效率低
【特征】某个 task 执行效率低,且该 task 中有用户自定义的扩展。甚至是 UDF 的执行超时报错:“Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance”。
首先确定udf位置,点看慢的fuxi task, 可以看到operator graph 中是否包含udf,例如下图说明有java 的udf。
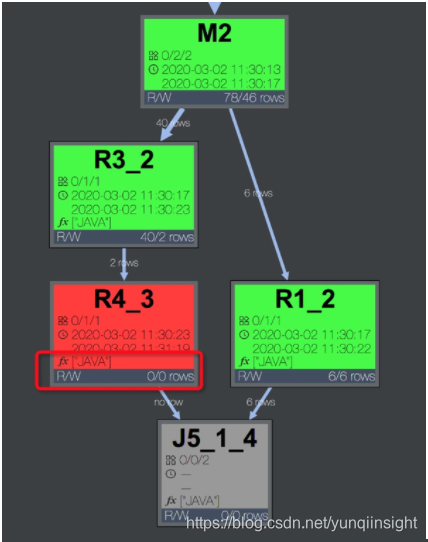
![]()
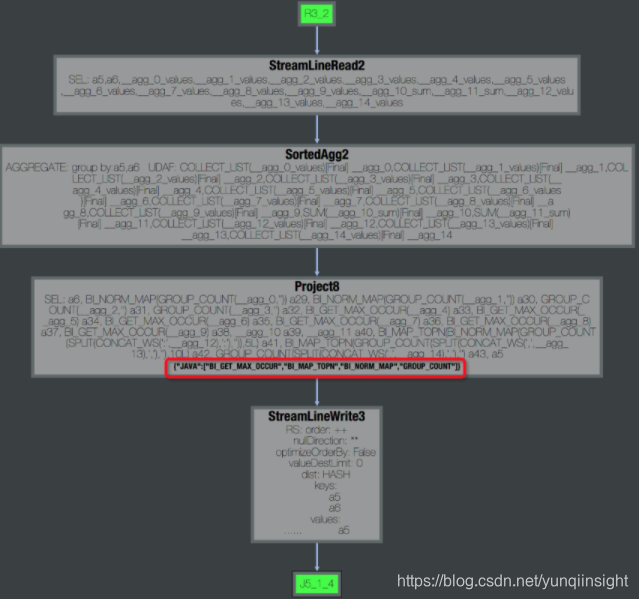
![]()
通过查看logview 中fuxi instance 的stdout 可以查看该operator 运行速度,正常情况 Speed(records/s) 在百万或者十万级别。
![]()
解决方法:检查udf逻辑尽量使用内置函数
本文为阿里云原创内容,未经允许不得转载。