简介: 本文将聚焦在 K8s 层的容器优先级和服务质量模型上,希望给业界提供一些可借鉴的思路。
作者:南异
引言
阿里巴巴在离线混部技术从 2014 年开始,经历了七年的双十一检验,内部已经大规模落地推广,每年为阿里集团节省数十亿的资源成本,整体资源利用率达到 70% 左右,达到业界领先。这两年,我们开始把集团内的混部技术通过产品化的方式输出给业界,通过插件化的方式无缝安装在标准原生的 K8s 集群上,配合混部管控和运维能力,提升集群的资源利用率和产品的综合用户体验。
由于混部是一个复杂的技术及运维体系,包括 K8s 调度、OS 隔离、可观测性等等各种技术,本文将聚焦在 K8s 层的容器优先级和服务质量模型上,希望给业界提供一些可借鉴的思路。
K8s 原生模型
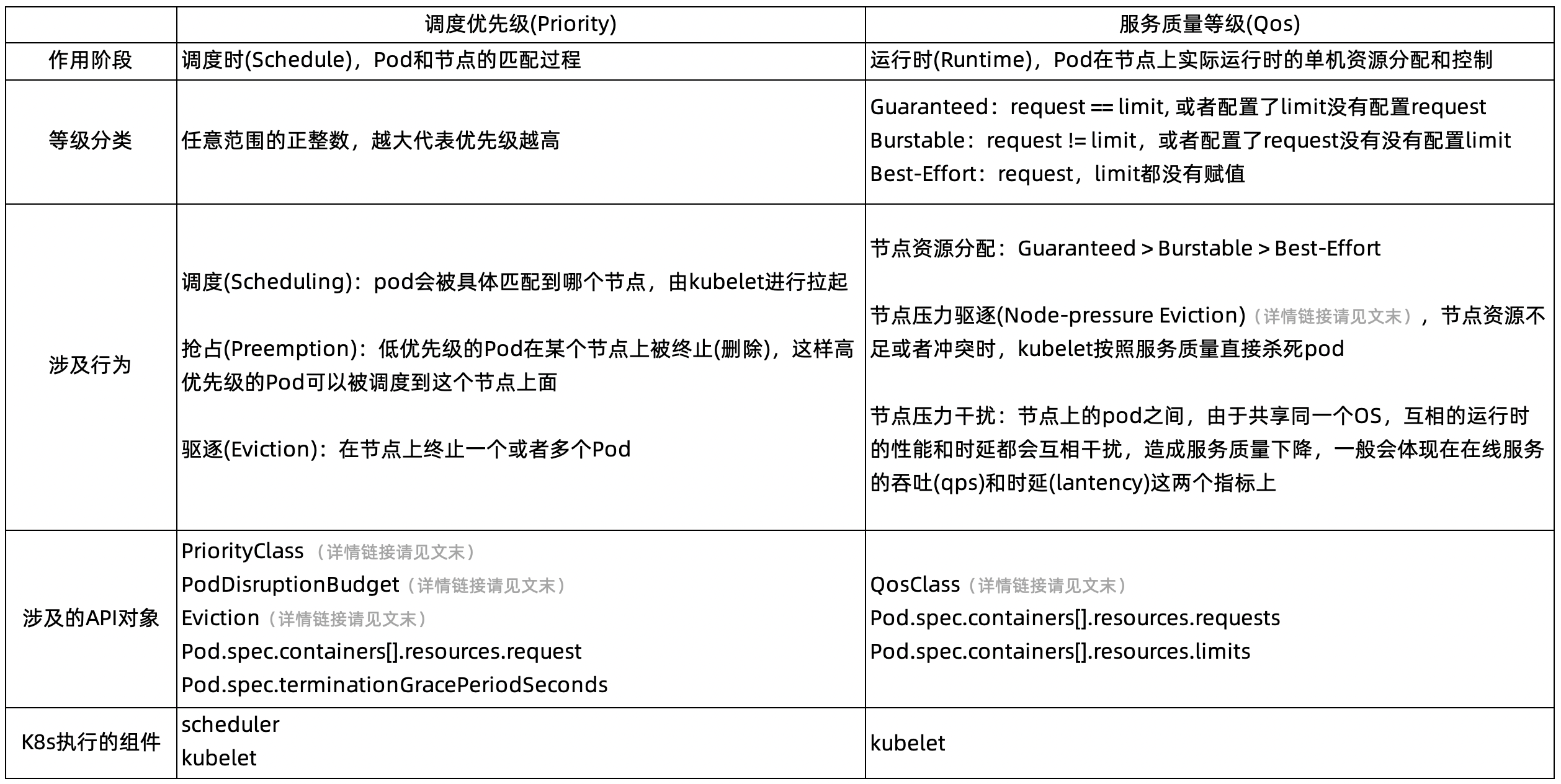
在实际的生产实践中,即使是很多对云原生和 K8s 比较熟悉的技术人员,往往也会混淆调度优先级(Priority)和服务质量(QoS)。
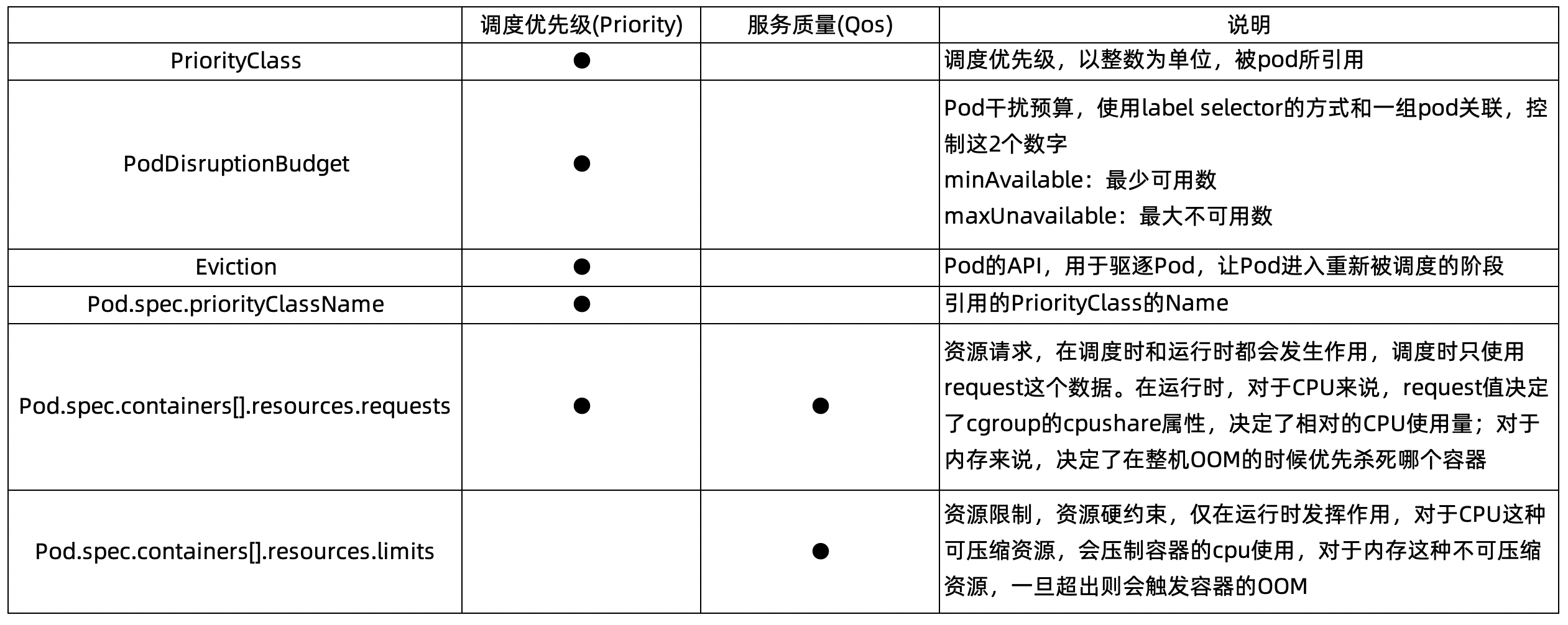
所以,在谈混部的模型前,首先我们对 K8s 原生的概念做详细的介绍,详见下表:
混部需要解决的问题
混部主要解决的问题是,在保证部署应用的服务等级目标 SLO 的前提下,充分利用集群中的空闲资源,来提升集群整体的利用率。
当一个集群被在线服务部署分配部署完以后,由于在线应用的高保障的特性,会给容器一个 peak 的资源规格,这样有可能导致实际真实利用率很低。 我们希望将这部分空闲但是未使用的资源超卖出来提供给低 SLO 的离线作业使用,以此提高整体机器水位。这样就需要提供基于 SLO 的调度能力,以及考虑到机器真实资源水位进行调度,避免热点的产生。
我们希望将这部分空闲但是未使用的资源超卖出来提供给低 SLO 的离线作业使用,以此提高整体机器水位。这样就需要提供基于 SLO 的调度能力,以及考虑到机器真实资源水位进行调度,避免热点的产生。
另外,由于在线通常 SLO 比较高,离线 SLO 比较低,那么当机器水位整体提升过高的时候,可以通过抢占离线的作业方式,来保障在线应用的 SLO。以及需要利用率内核层面 cgroup 的隔离特性来保障高 SLO 和低 SLO 作业。
那么,在这些在线和离线的 Pod 之间,我们就需要用不同的调度优先级和服务质量等级,以满足在线和离线的实际运行需求。
云原生混部定义的应用等级模型
首先请看一下在混部中一个 Pod 的 yaml 是怎么定义的
apiVersion: v1
kind: Pod
metadata:
annotations:
alibabacloud.com/qosClass: BE # {LSR,LS,BE}
labels:
alibabacloud.com/qos: BE # {LSR,LS,BE}
spec:
containers:
- resources:
limits:
alibabacloud.com/reclaimed-cpu: 1000 # 单位 milli core,1000表示1Core
alibabacloud.com/reclaimed-memory: 2048 # 单位 字节,和普通内存一样。单位可以为 Gi Mi Ki GB MB KB
requests:
alibabacloud.com/reclaimed-cpu: 1000
alibabacloud.com/reclaimed-memory: 2048
这是在混部里面我们引入的 Pod 的等级,和社区原生不同的地方在于,我们显式的在 anotation 和 label 里面申明了 3 种等级:LSR、LS、BE。这 3 种等级会同时和调度优先级(Priority)、服务质量(Qos)产生关联。
具体的每个容器的资源用量,LSR 和 LS 还是沿用原有的 cpu/memory 的配置方式,BE 类任务比较特殊,通过社区标准的 extended-resource 模式来申明资源。
那么,这 3 类等级具体代表的运行时含义又是什么呢?可以参考这个图,看下这三类应用在 CPU 上的运行时的情况 以及详细的对其他资源使用的影响:
以及详细的对其他资源使用的影响:
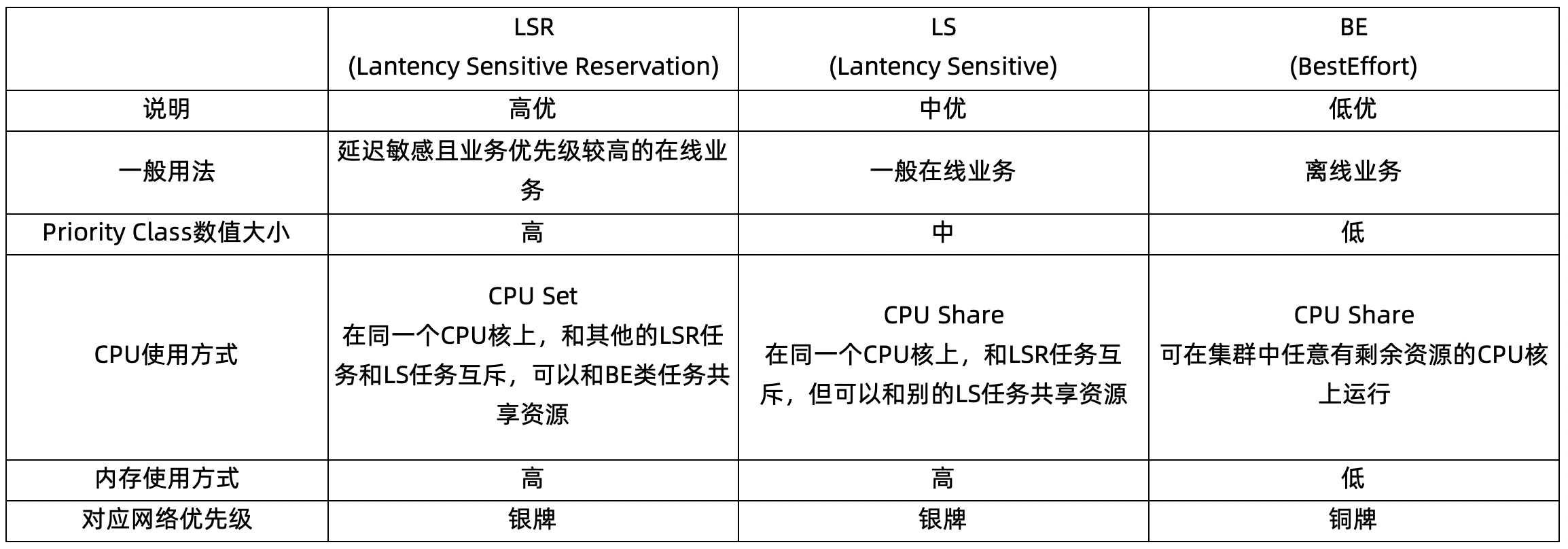
当这三种类型优先级任务实际在调度和运行时发生的行为,如下面这个表所示

配额、水位线、多租隔离
本文仅聚焦讨论了 K8s 单 Pod 的调度优先级,在实际使用时,为了保证应用的 SLO,需要配合单机的水位线、租户的配额、以及 OS 隔离能力等等使用,我们会在后续文章里面详细探讨。
相关解决方案介绍
进入了 2021 年,混部在阿里内部已经成为了一个非常成熟的技术,为阿里每年节省数十亿的成本,是阿里数据中心的基本能力。而阿里云也把这些成熟的技术经过两年的时间,沉淀成为混部产品,开始服务于各行各业。
在阿里云的产品族里面,我们会把混部的能力通过 ACK 敏捷版,以及 CNStack(CloudNative Stack)产品家族,对外进行透出,并结合龙蜥操作系统(OpenAnolis),形成完整的云原生数据中心混部的一体化解决方案,输出给我们的客户。
原文链接
本文为阿里云原创内容,未经允许不得转载。