输入图像的focus 结构
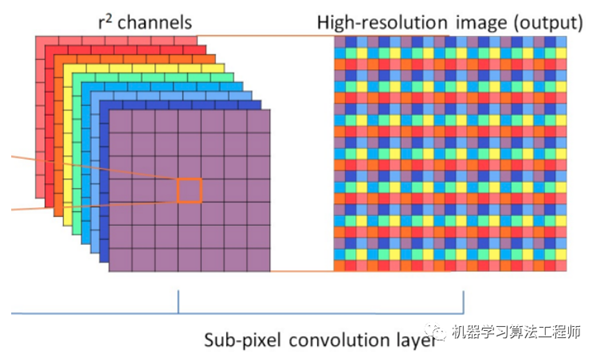
这个是从右到左的方向,将高分辨率的图片,分成r*r个小的channel
这样输入就变小了
增加正样本,加快训练速度
本文也采用了增加正样本anchor数目的做法来加速收敛,这其实也是yolov5在实践中表明收敛速度非常快的原因。其核心匹配规则为:
(1) 对于任何一个输出层,抛弃了基于max iou匹配的规则,而是直接采用shape规则匹配,也就是该bbox和当前层的anchor计算宽高比,如果宽高比例大于设定阈值,则说明该bbox和anchor匹配度不够,将该bbox过滤暂时丢掉,在该层预测中认为是背景
(2) 对于剩下的bbox,计算其落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该bbox的,可以发现粗略估计正样本数相比前yolo系列,至少增加了三倍
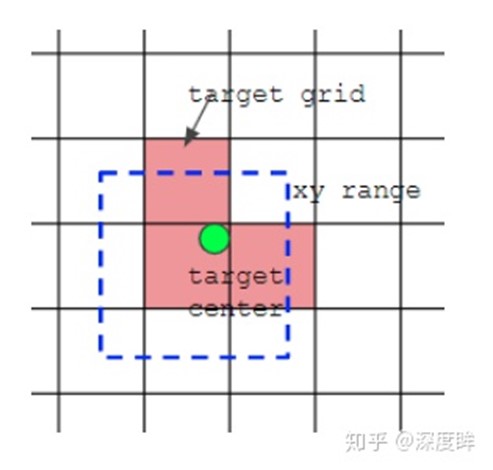
如上图所示,绿点表示该Bbox中心,现在需要额外考虑其2个最近的邻域网格也作为该bbox的正样本anchor。从这里就可以发现bbox的xy回归分支的取值范围不再是0~1,而是-0.5~1.5(0.5是网格中心偏移,请仔细思考为啥是这个范围),因为跨网格预测了。
Neck PANet 和SPP,并且在Neck 中也添加了CSP
CIoU loss +DIoU NMS
输入图片的自适应缩放, 减少黑边
第一步:计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,
可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
第二步:计算缩放后的尺寸

原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。
第三步:计算黑边填充数值

将416-312=104,得到原本需要填充的高度。
再采用numpy中np.mod取余数的方式,得到40个像素,再除以2,即得到图片高度两端需要填充的数值。
这里最终的结果并不是一个正方形了,
此外,需要注意的是:
a.这里大白填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一样的效果。
b.训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
来自 <https://jishuin.proginn.com/p/763bfbd2a0ad>