ElimiNet: A Model for Eliminating Options for Reading Comprehension with Multiple Choice Questions
摘要
多选式阅读理解任务要求人(或机器)通过阅读给定的{文章,问题}对,然后在n个选项中选出正确的一个。对于这个任务,当前最先进的模型首先计算了问句感知的文章表示,然后选择与此表示具有最大相似度的选项作为答案。然而,当人类在做这项任务时并不是只关注选项的选择,而且会对选项之间进行比较,从而消除某些选项,然后再做选择。具体来说,他通过一个‘门’结构来决定在给定{文章,问题}对的情况下,一个选项是否需要被消除,如果该选项确实需要被消除,那么就使得文章表示正交于此选项(类似于忽略文章中与消除选项相对应的部分)。该模型进行多轮局部消除以完善段落表示,最后使用选择模块选择最佳选项。我们在最近发表的大规模数据集RACE上验证我们的模型性能,结果表示在该数据集中13类问题中,我们的模型在其中7类问题上优于目前最先进的模型。此外,我们的实验结果表明,将我们基于消除选择的方法与基于选择的方法相结合,可以使我们比该数据集上报告的最佳性能提高3.1%。
1 Introduction
阅读理解是根据给定文章来回答问题的一项任务。具有此类功能的AI代理在多种商业应用中被广泛使用,例如回答公司金融报告中的问题、使用产品手册进行故障排除,回答维基百科文档中的常识性问题等。基于其广泛的应用场景,一些文献中已经研究了该任务的集中变种任务。例如,给定一篇文章和一个问题,它的答案可以是(i)文中的某个片段,或者是(ii)根据文章生成的,又或者是n个选项中的其中一个。最后一类任务被广泛用于高中、初中和竞争考试中。我们将其称之为多选式阅读理解(RC-MCQ)。人们对建立具有深度语言理解能力的AI代理的研究的兴趣日益增长,在一些测试中,其性能甚至可以与人类相媲美。例如,最近Lai等人针对RC-MCQ任务发表了一个大规模数据集,其数据来自中国高中和初中的英语考试。其中包含了大约28000篇文章和接近100000个问题。这个规模的数据集使得训练和验证基于复杂神经网络的模型成为可能,同时也可以有效衡量RC-MCQ任务的科学进展。然而,回答这种的多项选择式的问题(如图1所示),人们通常会结合选项消除和选项选择两种思路。更具体地说,人们首先试着消除与给定问题不相关的选项。这样做可以让我们忽略文中与此选项相关的部分内容(因为这部分内容与被消除的选项相关,例如图1中被标记为蓝色和橙色的部分,它们分别与选项B和选项C相关)。这个过程可被重复多次,每次都消除一个选项并重新审视文章(通过忽略不相关部分)。最终,当不再有机会消除任何一个选项时,我们在剩余选项中选择一个最好的选项。相反,针对RC-MCQ任务,现有的最先进的模型只集中于选项的选择。具体来说,给定一个问题和一篇文章,他们首先计算得出问句感知的文章表示(记为dq),然后对每个选项计算出一个表示,最后选择与dq最相近的那个选项作为答案。这些模型没有迭代过程可以消除选项,并且根据这种消除精炼段落的表示形式。

我们提出了一个模型,该模型视试图模拟人类回答LCQ任务的过程。与先前最先进的方法类似,我们首先计算一个问句感知的文章表示(这实质上是在试图保留文章表示中仅与问题相关的部分)。接着我们使用一个消除门(取决于文章、问句和选项)来决定一个选项是否需要被消除。然后,仿照上述人类回答该问题的过程,我们让模型也忽略与这个被消除选项相关的部分。我们通过使文章表示与选项表示相减的方式来实现该操作(类似于Gram-Schmidt正交)。由消除门来对正交的程度做出软决定。我们将此过程重复多次,每轮做一次选项的软消除,并完善文章表示。我们称该模型为消除(ElimiNet)。需要注意的是,这样的模型对于那些选项之间高度相关的例子是无效的。比如,如果一个问题是询问蝴蝶一生的生命形态,而选项是对它的四个生命形态(蝴蝶、茧、毛毛虫、pupa)进行排序,那么该模型此时是无效的。然而,我们在本文中使用的数据集中并不包含这类需要排序的问题和选项。
我们在RACE数据集上验证我们的模型,并与次数据及上最先进的模型门控注意力阅读器(GAR)进行了比较。实验结果显示在RACE数据集中的13类问题中,我们的模型在7类问题里优于GAR。我们也对通过ElimiNet学习到的软消除概率进行了可视化,结果显示该模型确实学会了迭代完善文章表示,并将概率质量推向正确的选择。最后,我们展示了结合了ElimiNet的复合模型与GAR的47.2%的准确率相比,该模型有3.1%的提升。我们的代码是公开可用的。
2 Related Work
在过去的几年中,大规模数据集的出现使得人们对阅读理解任务产生的强烈的兴趣。这些数据集覆盖了不同种类的阅读理解任务。例如,SQuAD、TriviaQA、NewsQA、MS MARCO和NarrativeQA等,它们都包含{文章、问题和答案},这里的答案是文章中的片段或通过生成而得到的。另一方面,CNN/Daily Mail、Children’s Book Test (CBT)和Who Did What (WDW)数据集是填空式阅读理解数据集,该任务是预测问题中空缺的单词或实体词。还有一类数据集,像MCTest、AI2和RACE,它们属于多选式阅读理解数据集,该任务需要选择正确的答案。
这些数据集的出现和深度学习在多种NLP任务中的成功应用使得基于神经网络的阅读理解模型得以实现和使用。例如,[Xiong et al., 2016; Seo et al., 2016; Wang et al., 2017; Hu et al., 2017]等工作提出的模型解决了第一类需要抽取文章片段型的阅读理解任务,其实现数据集为SQuAD。类似的,[Chen et al., 2016; Kadlec et al.,2016; Cui et al., 2017; Dhingra et al., 2017]等工作提出的模型解决了第二类填空式的阅读理解任务。最后,Lai等人采用[Chen et al., 2016;Dhingra et al., 2017]等工作中为填空式阅读理解提出的模型来解决RC-MCQ任务。不管这些模型解决的是哪类任务,它们都有一个相似的框架。具体来说,这些模型都包括以下组件:(i)文章编码(ii)问题编码(iii)问题与文章间的交互捕获(iv)问题与选项间的交互捕获(针对多选式阅读理解)(v)多轮迭代表示文章(vi)用于预测/生成/选择答案的解码器。这些模型的不同之处是由编码器、解码器、交互函数和迭代机制的具体选择造成的。大多数现有的先进模型都可视为上述框架的具体实例。
我们的模型和现有的RC-MCQ模型的关键不同之处在于,我们引入了组件来(软)消除不相关的选项并基于这种消除机制来完善文章表示。文章表示通过多次(软)消除来进行完善,随后将其用于选择最相关的那个选项。据我们所知,这是第一个将选项消除的思想用于RC-MCQ任务的模型。
3 Proposed Model
给定一篇包含M个词的文章D=[w1d, w2d,…, wMd],一个包含N个词的问题Q=[ w1q, w2q,…, wNq]和n个包含Jk个词的选项Zk=[ w1z, w1z,…, wJkz],其中k大于等于1,小于等于n。该任务是预测选项的条件概率分布(即预测P(Zi|D,Q))。我们使用神经网络对该结构进行建模,它包含文章/问题/选项的编码模块,它们之间的交互特征捕获模块,消除选项模块和选择答案模块。我们称其为编码器,交互、消除和选择,结构如图2所示。其中,我们工作的主要贡献是引入了一个模块用于消除。具体来说,我们以入了一个模块用于(i)决定一个选项是否需要被消除(ii)完善文章表示以考虑消除/未消除的选项(iii)重复上述过程多次。在本节的剩余部分,我们将对我们模型的多种组件进行介绍。
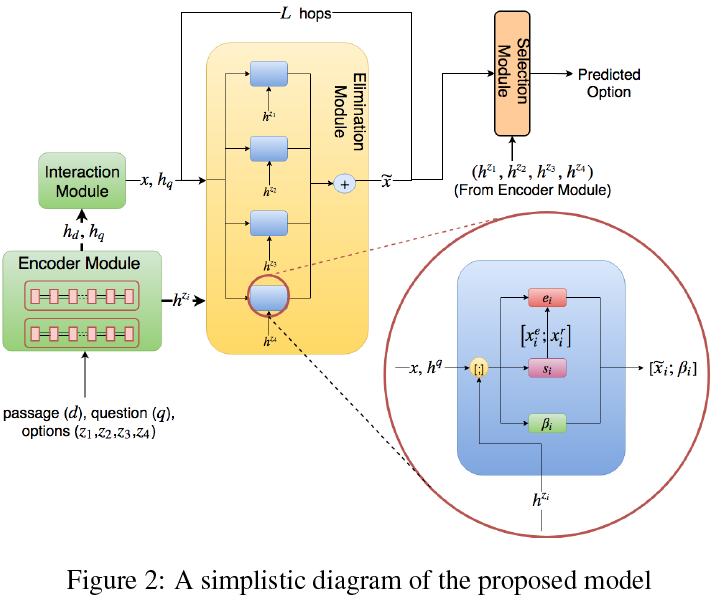
Encoder Module:我们先计算得到问题和选项的向量表示,该过程通过一个双向循环网络实现。该网络中包含两个GRU组件,一个从左往右对文本(问题或选项)进行编码,一个从右往左对文本(问题或选项)进行编码。例如,对于给定的问题Q=[ w1q, w2q,…, wNq],每个GRU单元为每个时间步计算得到一个隐藏表示:
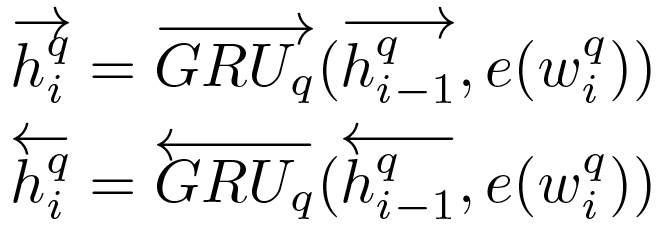
联接所有时间步的隐藏表示以得到最终表示。选项的最终表示也通过相同的方式获得。只是需要注意的是,用于问题和选项的编码结构(GRU)是独立的,但用于不同选项的编码编码结构(GRU)是相同的。此外,文章表示也是通过该结构得到的,后面的交互模块中,我们也使用GRU去计算文章中词之间的交互值。
Interaction Module: 该模块的思想是当计算出基本的问句和文章的表示形式,就允许它们进行交互,以便可以根据问句的编码表示来完善文章的编码表示。这与人类先读文章和问题,然后再多次阅读文章,试图集中于与问题先关的部分,而忽略与问题不相关的部分(例如,图1中标为红色的部分)。尉氏县这个思路,我们使用与门控注意力阅读器相同的多条结构来实现迭代完善文章表示的过程。在每一跳中,我们使用如下公式来进行计算:
![]() 该操作的目标是通过每一跳基于与问题的交互来完善其嵌入表示。接着,我们计算:
该操作的目标是通过每一跳基于与问题的交互来完善其嵌入表示。接着,我们计算:
![]()
这是计算当前文章词表示中每个维度的重要性,然后用作放大或缩小文章词表示中不同维度的门。
![]()
现在,我们使用双向递归神经网络对这些经完善的文章词表示进行相互交互,以计算下一跳的表示形式。
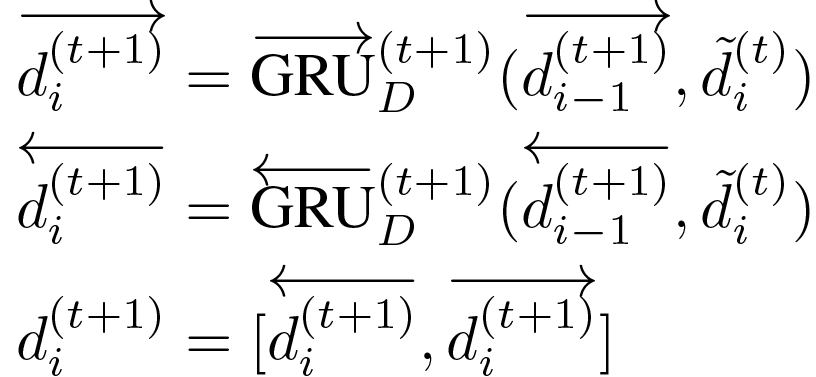
对T跳重复上述过程,其中每跳以d(t)i,Q作为输入并计算精确表示。在T跳之后,我们通过使用加权和组合文章词表示的方式来获得该文章的定长向量表示。
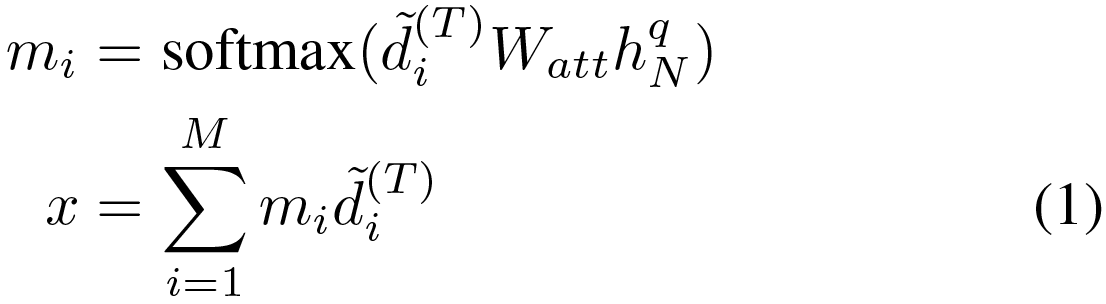
其中,mi计算每个段落单词的重要性,x是段落表示的加权和。
Elimination Module:该模块的目标是完善文章表示,以便模型不会对与不相关选项对应的那部分内容投入关注。为实现该功能,我们需要先决定一个选项是否需要被消除,从而确保文章表示中的相应部分是否需要被修改。对于第一步,我们引入了一个消除门来实现软消除:
![]()
需要注意的是该门结构对于不同选项并不是共享的,即每个选项都有自己单独的门结构。特别的,该门结构的值取决于选项被双向GRU编码的最终状态。同时它也取决于问题被双向GRU编码的最终状态和经交互模块处理后的完善后的文章表示。W,V,U是待训练参数。
基于上述软消除操作,我们想继续完善文章表示。为此,我们计算xie和xir,前者是文章表示与选项表示正交的组成部分,后者是文章表示与选项表示相关的组成部分。
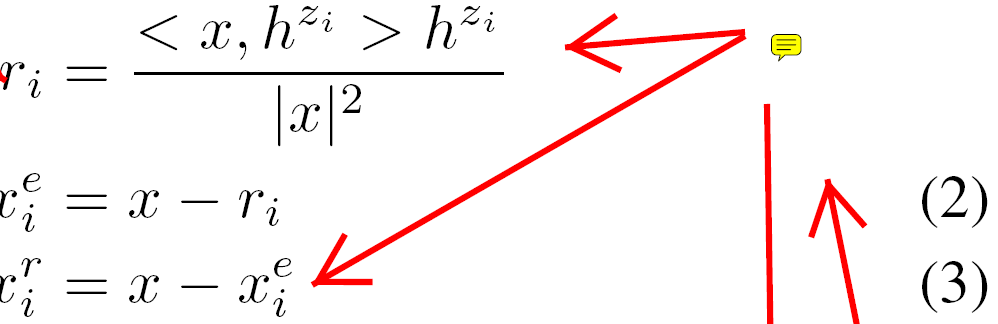
消除门决定了xie和xir中有多少信息需要保留。
![]()
如果ei=1(意味着消除,例如图1中的选项D对应的部分),那么文章表示将与此选项进行正交(类似忽略与此选项相关的文章内容);如果ei=0(意味着不消除,例如图1中标记为绿色的部分,它对应着选项A),那么文章表示将与此选项对齐(类似重点关注与该选项相关的文章内容)。
注意公式2与公式3,我们完全减去选项相关内容和选项正交内容。我们想让模型更具灵活性,以便决定有多少内容参与相减。为实现这个效果,我们引入了另一个门。称之为相减门,
![]()
这里的W,V,U是待训练参数。我们用x-si*ri和x-si*xie来代替公式2和公式3中的减法。一些人可能认为ei本身可以编码信息,但是实验结果显示将这两个组件(消除门和相减门)分开训练可以获得更好的效果。
对于每个选项,我们独立计算其表示。这些表示被结合为单个完善的文章表示。
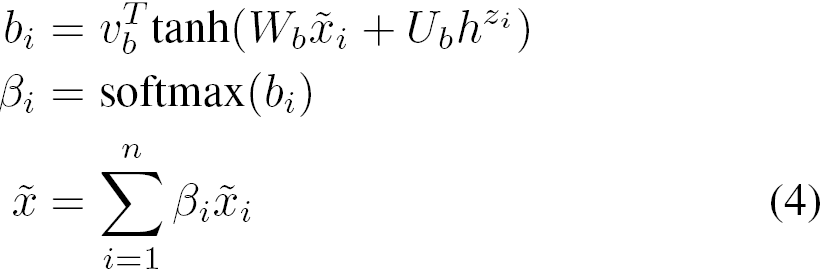
我们重复上述过程L次,第m次需要的文章输入是第m-1次输出的完善后的文章输出。
Selection Module 最后,选择模块使用经过L次消除迭代后的完善文章表示与每个选项表示,通过双线型相似度函数计算其匹配得分。
![]()
我们选择上面得分最高的选项作为答案。我们使用交叉熵损失函数来训练网络,这个过程中通过对所有选项得分进行归一化来得到每个选项作为正确答案的概率。
4 Experimental Setup
在本节中,我们介绍了用于验证模型性能的数据集,模型的超参,训练过程以及与最优模型的对比。
Dataset:我们在RACE数据集上验证了我们模型的性能,该数据集中的多选式问题来自中国高中和初中的英语考试。高中部分的数据(RACE-H)中的训练数据有62445个问题,验证数据有3451个问题,测试数据有3498个问题。初中部分的数据(RACE-M)中的训练数据有18728个问题,验证数据有1021个问题,测试数据有1045个问题。
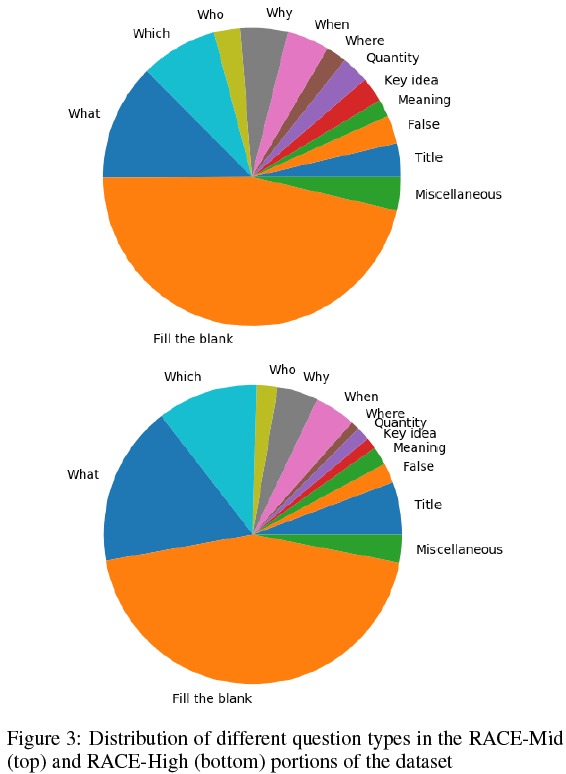
该数据集中的问题具有多种难度。例如,有些问题是要选出最合适的文章题目,这要求模型具有深度语言理解能力。有些问题需要在特定语境下(文章中)解释某个术语或短语的意思。类似的,有些问题要求概括本文的中心思想。最后,还有些标准的Wh型问题。基于这些类型的问题,我们想知道消除模块对于哪类问题更有用。为了验证该问题,在内部注释者的帮助下,我们通过人工标注的规则,将该数据集中的问题分为13类:(i)6种Wh型问题,(ii)要求总结文章的题目/意义/中心思想的问题,(iii)判断题,(iv)数量题(例如,how much,how many),(v)填空题。数据集中91.26的问题可以划分进这12类问题,还有8.74%的问题被标记为其他。RACE-H和RACE-M中类别的划分情况如图3所示。
Training Procedures:我们通过两种方式来训练模型。第一种方式:我们同时训练所有模块(encoder, interaction, elimination, and selection)的所有参数。第二种方式:我们先删掉消除模块,只训练剩余的模块。然后固定编码模块和交互模块的参数,只训练消除模块和选择模块的参数。第一种方式是为了让模型更好地理解全文,第二种方式是为了聚焦于消除选项(换句话说,第二种方式确保了整体训练过程的重点是消除模块)。当然,我们也必须同时学习选择模块的参数,因为此时它需要完善文章表示。从经验上来说,我们发现这种预训练过程对于端到端训练好的模型性能并没有提升。因此,我们只报道了第一种方式的结果(例如,端到端的训练)。
Hyperparameters:我们将词表大小限制为50000,对文章、问题和选项使用相同的词表。我们使用数据集作者划分的训练集、验证集和测试集数据。我们基于验证集上的准确率对模型进行微调。我们用10维Glove嵌入表示来初始化我们的词嵌入矩阵。我们分别以微调和不微调的方式进行实验。文章、问题和选项处理过程中使用的BiGRU的神经元数量都是相同的,我们使用如下数量分别进行了实验:{64,128,256}。在交互模块中,我们分别使用{1,2,3}跳进行了实验,在消除模块中,使用{1,3,6}轮进行了实验。我们在BiGRU中使用dropout机制,并使用{0.2,0.3,0.5}进行了实验。我们使用Adam和SGD作为优化器分别进行了试验,使用Adam时,学习率为10-3;使用SGD时,学习率为{0.1,0.3,0.5}。最终我们发现使用Adam时模型收敛更快。我们将训练上限设置为50epoch。
Models Compared:我们将我们的结果与RACER上最先进的方法(Gated Attention Reader)进行了比较。这个模型最初是为了解决填空式阅读理解任务而被提出的,事实上,它确实是当前填空式阅读理解任务中的最优模型。RACE的作者将此模型作为RC-MCQ数据集上的基准方法,并用选项和文章表示的双线型相似度作为最终输出。
5 Results and Discussions
在本节中,我们将对我们的实验结果进行讨论。
5.1 Performance of Individual Models
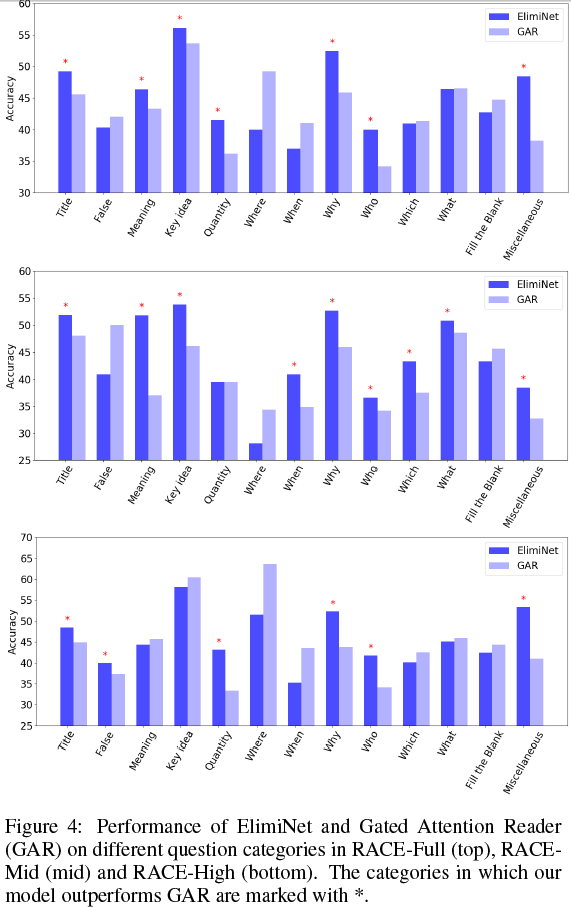
我们在RACE-H、RACE-M和RACE全数据集上将我们的方法与不同的模型进行了对比。对于每个数据集,我们都在不同类型的问题上对比了准确率的差异。对比结果总结在图4中。我们发现在RACE-M中,我们的模型在13类问题中的9类里表现都要优于GAR。类似的,在RACE-H中,我们的模型在13类问题中的6类里表现都要优于GAR。而在RACE全数据集中,我们的模型在13类问题中的7类里表现都要优于GAR。需要注意的是,在全测试集(包含所有类型的问题)上,我们的模型性能要略高于GAR。这主要的原因是数据集中填空式的问题占大多数,而我们的模型在此类问题中的性能要低2%。然而,该数据集中填空式问题占了总量的50%,尽管我们的模型在其他类别中有提升,但也因在此类问题中心梗不佳而被拉低了整体性能。
5.2 Ensemble of Different Models
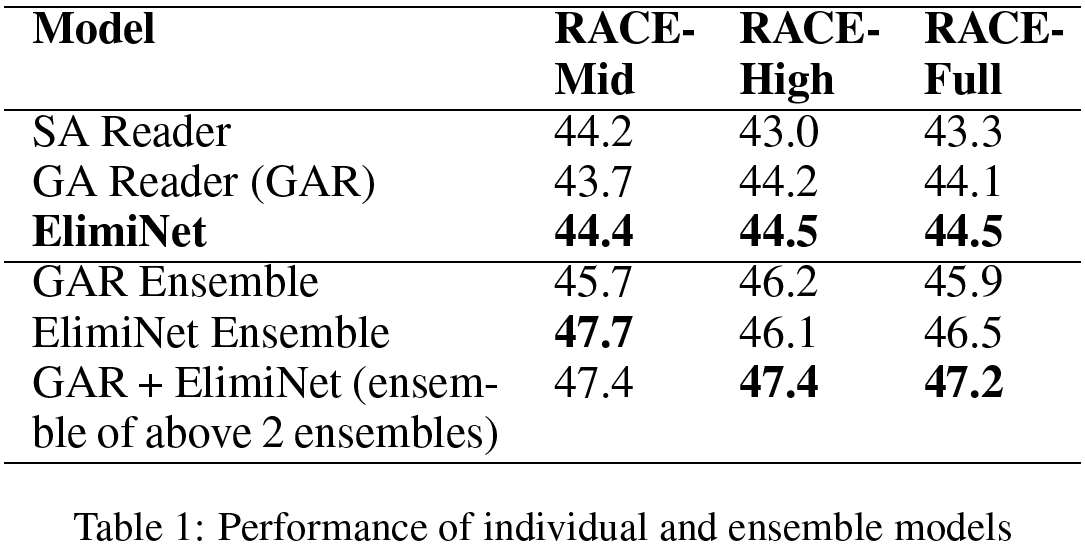
由于ElimiNet和GAR在不同类型的问题上表现都不错,所以我们这些结构的复合模型一定会比但模型的性能要好。为了公平比较,当我们独立进行n个GAR模型和n个ElimiNet模型的复合时,我们还希望看到其性能。我们将其分别称为GAR-ensemble和ElimiNet-ensemble。使用不同的超参数设置对集合中的每个模型进行训练,我们使用n=6(当n>6时,我们并没有看到性能的提升)。实验结果展示于表1中。ElimiNet-ensemble优于GAR-ensemble,并且最终的复合模型提供了最佳效果。我们观察到ElimiNet-ensemble在RACE-M数据集上的表现明显优于GAR-ensemble,并且在RACE-H数据集上给出几乎相同的性能。总之,通过复合模型,我们获得了47.2的准确率,该结果比GAR高出3.1%,比GAR-ensemble高出1.3%。
5.3 Effect of Subtract Gate
我们想看看相减门是否可以使得模型更好地进行学习。为此,我们我么比较了有相减门和没有相减门的模型性能差异。我们发现我们模型的准确率从44.33%下降到了42.58%,而在13类问题中,只有在其中3类问题上由于GAR。这表示相减门提供的灵活性确实有助于模型的性能。
5.4 Visualizing Shift in Probability Scores
如果消除模块确实在学习消除选项并与未消除/消除的选项对齐/正交化段落表示,那么当我们进行多次消除时,我们应该会看到概率分数发生变化。在图5中,为了可视化,我们在两个不同的测试实例通过消除模块之前以最高的概率绘制了正确选项和不正确选项的概率。我们观察到,当我们进行多次消除时,概率质量将从错误的选项(蓝色曲线)转移到正确的选项(绿色曲线)。 这表明消除模块正在学习使段落表示与正确的选项对齐(因此,增加其相似度)并使之远离错误的选项(因此,减小其相似度)。

6 Conclusion
我们对多选式阅读理解任务进行了研究,并提出了一个模拟人类解决此问题的方式的模型。具体来说,该模型使用消除和选择的结合来找到正确答案。这个模型是通过引入了一个消除模块来实现的,该模块对一个选项是否需要被消除做出软决定。然后,修改文章表示,使其与未消除的选项对齐或与消除的选项正交。正交或对其惭怍是通过两个门控函数实现的。这个过程被重复复多次以迭代完善文章表示。我们在最近发布的RACE数据集上评估了我们的模型,并表明在13个问题类型中,我们的模型在7类问题中的表现优于当前的最新模型。最后,将我们的消除选择方法与最新的选择方法结合使用,与RACE数据集上报告的最佳性能相比,我们得到了3.1%的改善。作为未来的工作,我们希望使用强化学习技术来代替硬消除,以学习硬消除的策略。