转载自:https://blog.csdn.net/shiyong1949/article/details/78482737
在mysql中使用group by进行分组后取某一列的最大值,我们可以直接使用MAX()函数来实现,但是如果我们要取最大值对应的ID,那么我们需要取得整行的数据。最开始的实现方法如下
SELECT t.event_id,MAX(t.create_time) as create_time from monitor_company_event t GROUP BY t.company_name,t.row_key,t.event_subType
执行以上SQL语句确实可以得到每个分组中最大的create_time,但是经检查发现最大的create_time对应event_id不是同一行的数据,如果我们要对event_id进行操作的话,结果肯定是错误的。
最后在网上找到了一个变通的办法,如下
SELECT t.* FROM (select * from `monitor_company_event` order by `create_time` desc limit 10000000000) t GROUP BY t.company_name,t.row_key,t.event_subType
从以上SQL中可以看出,我们先对所有的数据按create_time时间降序排列,然后再分组,那么每个分组中排在最上面的记录就是时间最大的记录,对执行结果检查后,确实可以实现我们的需求。
注意:
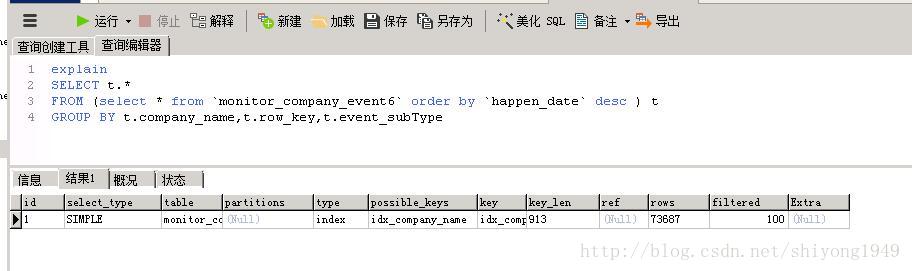
limit 10000000000 是必须要加的,如果不加的话,数据不会先进行排序,通过 explain 查看执行计划,可以看到没有 limit 的时候,少了一个 DERIVED 操作。
explain SELECT t.* FROM (select * from `monitor_company_event` order by `create_time` desc limit 10000000000) t GROUP BY t.company_name,t.row_key,t.event_subType

explain SELECT t.* FROM (select * from `monitor_company_event` order by `create_time` desc ) t GROUP BY t.company_name,t.row_key,t.event_subType